 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
Reducing the Scope of Language Models with Circuit Breakers
Oct 28, 2024Language models are now deployed in a wide variety of user-facing applications, often for specific purposes like answering questions about documentation or acting as coding assistants. As these models are intended for particular purposes, they should not be able to answer irrelevant queries like requests for poetry or questions about physics, or even worse, queries that can only be answered by humans like sensitive company policies. Instead we would like them to only answer queries corresponding to desired behavior and refuse all other requests, which we refer to as scoping. We find that, despite the use of system prompts, two representative language models can be poorly scoped and respond to queries they should not be addressing. We then conduct a comprehensive empirical evaluation of methods which could be used for scoping the behavior of language models. Among many other results, we show that a recently-proposed method for general alignment, Circuit Breakers (CB), can be adapted to scope language models to very specific tasks like sentiment analysis or summarization or even tasks with finer-grained scoping (e.g. summarizing only news articles). When compared to standard methods like fine-tuning or preference learning, CB is more robust both for out of distribution tasks, and to adversarial prompting techniques. We also show that layering SFT and CB together often results in the best of both worlds: improved performance only on relevant queries, while rejecting irrelevant ones.
Efficient Global String Kernel with Random Features: Beyond Counting Substructures
Nov 25, 2019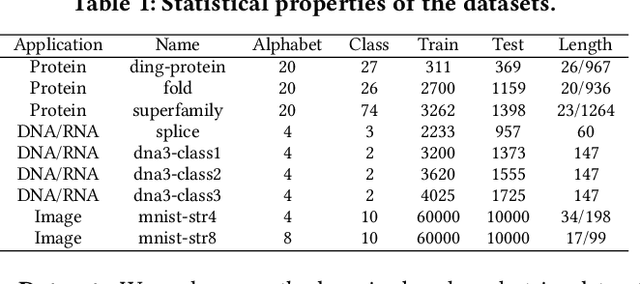
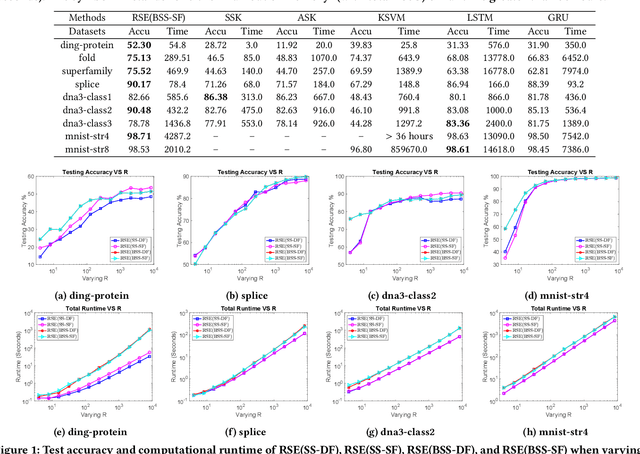
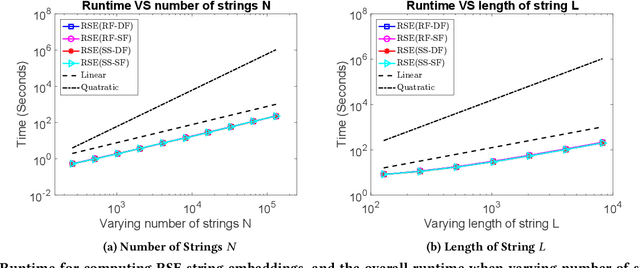
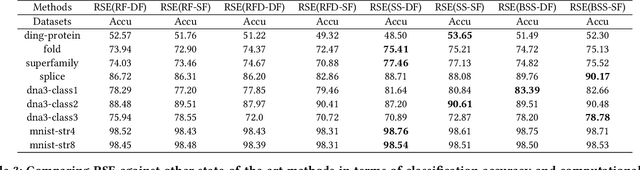
Analysis of large-scale sequential data has been one of the most crucial tasks in areas such as bioinformatics, text, and audio mining. Existing string kernels, however, either (i) rely on local features of short substructures in the string, which hardly capture long discriminative patterns, (ii) sum over too many substructures, such as all possible subsequences, which leads to diagonal dominance of the kernel matrix, or (iii) rely on non-positive-definite similarity measures derived from the edit distance. Furthermore, while there have been works addressing the computational challenge with respect to the length of string, most of them still experience quadratic complexity in terms of the number of training samples when used in a kernel-based classifier. In this paper, we present a new class of global string kernels that aims to (i) discover global properties hidden in the strings through global alignments, (ii) maintain positive-definiteness of the kernel, without introducing a diagonal dominant kernel matrix, and (iii) have a training cost linear with respect to not only the length of the string but also the number of training string samples. To this end, the proposed kernels are explicitly defined through a series of different random feature maps, each corresponding to a distribution of random strings. We show that kernels defined this way are always positive-definite, and exhibit computational benefits as they always produce \emph{Random String Embeddings (RSE)} that can be directly used in any linear classification models. Our extensive experiments on nine benchmark datasets corroborate that RSE achieves better or comparable accuracy in comparison to state-of-the-art baselines, especially with the strings of longer lengths. In addition, we empirically show that RSE scales linearly with the increase of the number and the length of string.
P2L: Predicting Transfer Learning for Images and Semantic Relations
Aug 20, 2019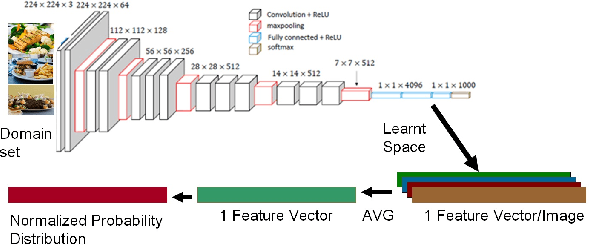

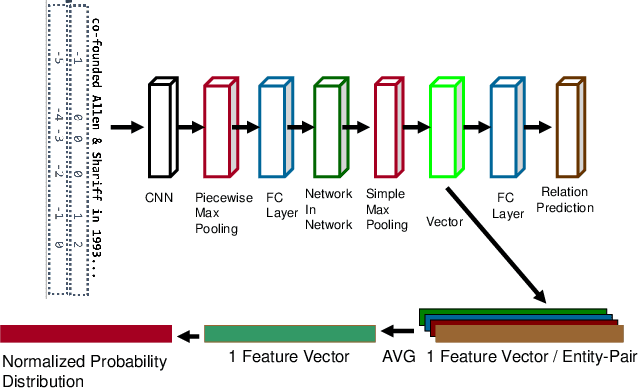
Transfer learning enhances learning across tasks, by leveraging previously learned representations -- if they are properly chosen. We describe an efficient method to accurately estimate the appropriateness of a previously trained model for use in a new learning task. We use this measure, which we call "Predict To Learn" ("P2L"), in the two very different domains of images and semantic relations, where it predicts, from a set of "source" models, the one model most likely to produce effective transfer for training a given "target" model. We validate our approach thoroughly, by assembling a collection of candidate source models, then fine-tuning each candidate to perform each of a collection of target tasks, and finally measuring how well transfer has been enhanced. Across 95 tasks within multiple domains (images classification and semantic relations), the P2L approach was able to select the best transfer learning model on average, while the heuristic of choosing model trained with the largest data set selected the best model in only 55 cases. These results suggest that P2L captures important information in common between source and target tasks, and that this shared informational structure contributes to successful transfer learning more than simple data size.
IPC: A Benchmark Data Set for Learning with Graph-Structured Data
May 15, 2019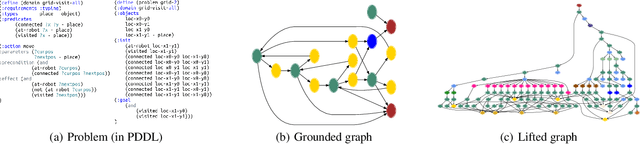
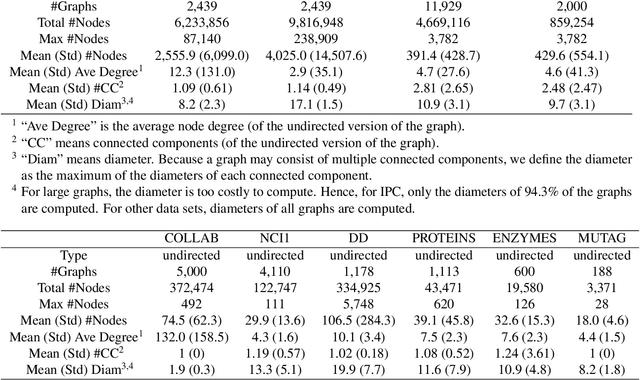
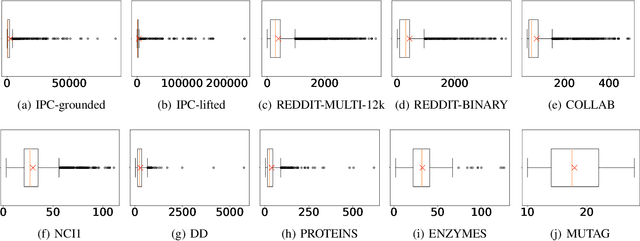
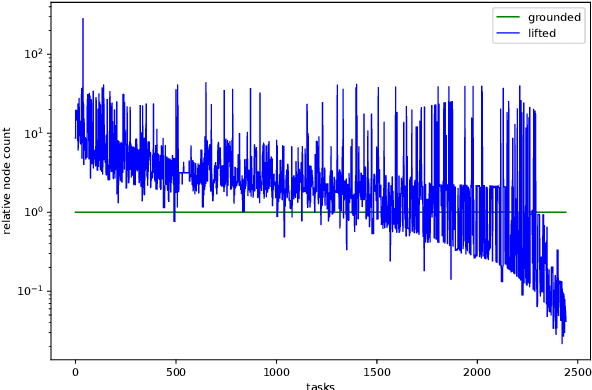
Benchmark data sets are an indispensable ingredient of the evaluation of graph-based machine learning methods. We release a new data set, compiled from International Planning Competitions (IPC), for benchmarking graph classification, regression, and related tasks. Apart from the graph construction (based on AI planning problems) that is interesting in its own right, the data set possesses distinctly different characteristics from popularly used benchmarks. The data set, named IPC, consists of two self-contained versions, grounded and lifted, both including graphs of large and skewedly distributed sizes, posing substantial challenges for the computation of graph models such as graph kernels and graph neural networks. The graphs in this data set are directed and the lifted version is acyclic, offering the opportunity of benchmarking specialized models for directed (acyclic) structures. Moreover, the graph generator and the labeling are computer programmed; thus, the data set may be extended easily if a larger scale is desired. The data set is accessible from \url{https://github.com/IBM/IPC-graph-data}.
Adaptive Planner Scheduling with Graph Neural Networks
Nov 03, 2018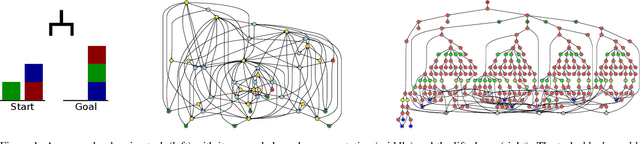
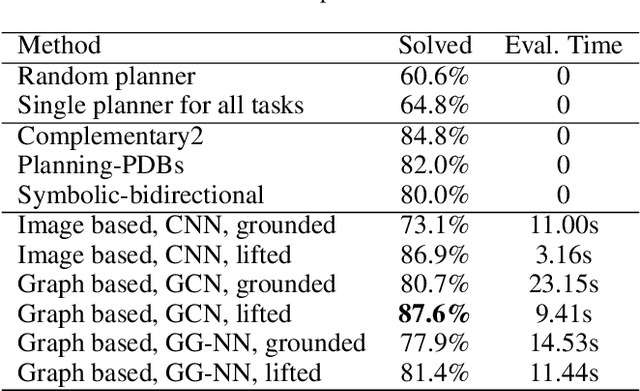
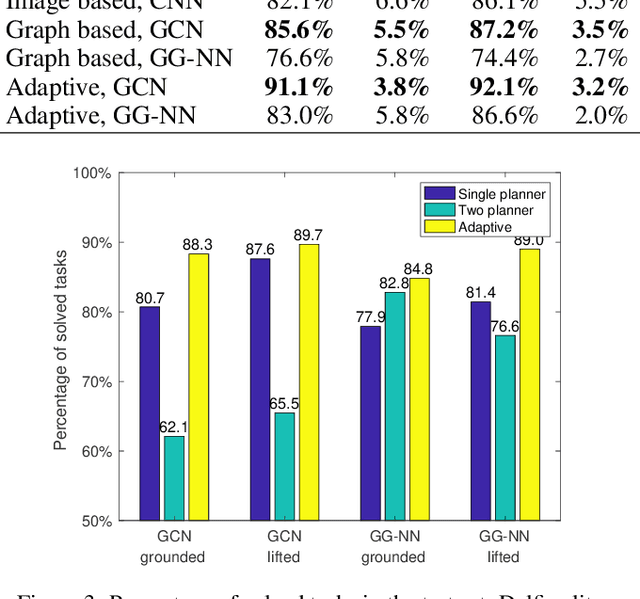
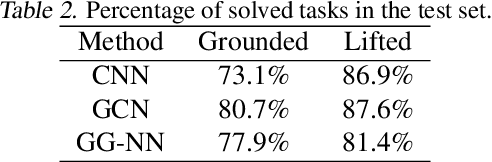
Automated planning is one of the foundational areas of AI. Since a single planner unlikely works well for all tasks and domains, portfolio-based techniques become increasingly popular recently. In particular, deep learning emerges as a promising methodology for online planner selection. Owing to the recent development of structural graph representations of planning tasks, we propose a graph neural network (GNN) approach to selecting candidate planners. GNNs are advantageous over a straightforward alternative, the convolutional neural networks, in that they are invariant to node permutations and that they incorporate node labels for better inference. Additionally, for cost-optimal planning, we propose a two-stage adaptive scheduling method to further improve the likelihood that a given task is solved in time. The scheduler may switch at halftime to a different planner, conditioned on the observed performance of the first one. Experimental results validate the effectiveness of the proposed method against strong baselines, both deep learning and non-deep learning based.