 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrash to Treasure: Harvesting OOD Data with Cross-Modal Matching for Open-Set Semi-Supervised Learning
Aug 12, 2021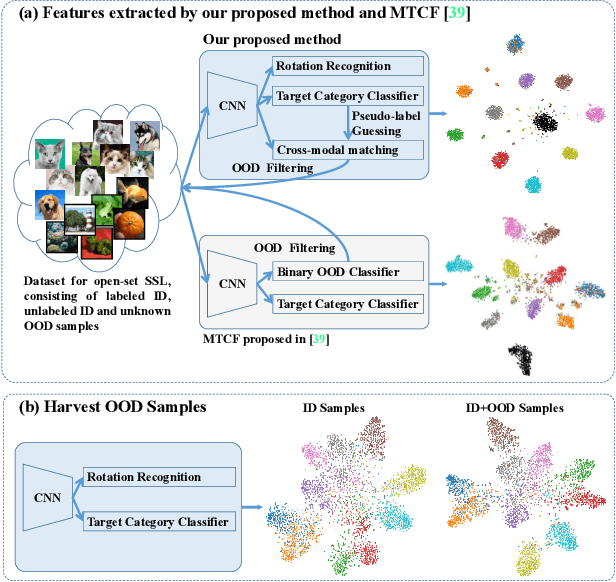
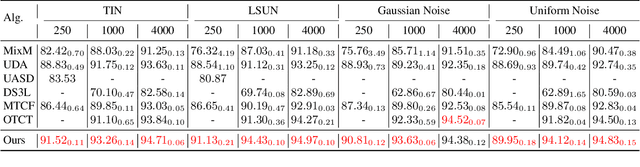
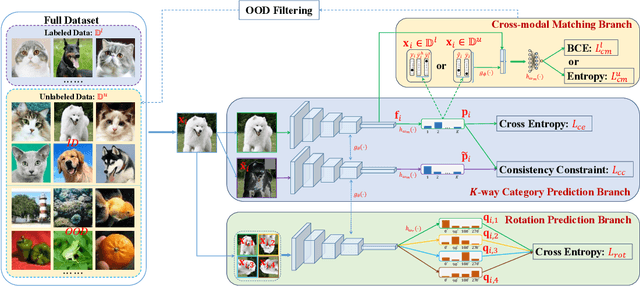
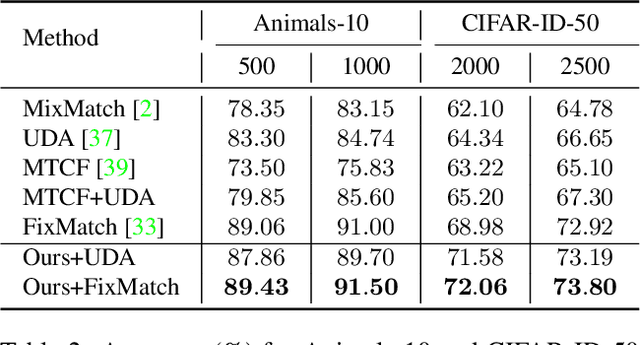
Open-set semi-supervised learning (open-set SSL) investigates a challenging but practical scenario where out-of-distribution (OOD) samples are contained in the unlabeled data. While the mainstream technique seeks to completely filter out the OOD samples for semi-supervised learning (SSL), we propose a novel training mechanism that could effectively exploit the presence of OOD data for enhanced feature learning while avoiding its adverse impact on the SSL. We achieve this goal by first introducing a warm-up training that leverages all the unlabeled data, including both the in-distribution (ID) and OOD samples. Specifically, we perform a pretext task that enforces our feature extractor to obtain a high-level semantic understanding of the training images, leading to more discriminative features that can benefit the downstream tasks. Since the OOD samples are inevitably detrimental to SSL, we propose a novel cross-modal matching strategy to detect OOD samples. Instead of directly applying binary classification, we train the network to predict whether the data sample is matched to an assigned one-hot class label. The appeal of the proposed cross-modal matching over binary classification is the ability to generate a compatible feature space that aligns with the core classification task. Extensive experiments show that our approach substantially lifts the performance on open-set SSL and outperforms the state-of-the-art by a large margin.
GREN: Graph-Regularized Embedding Network for Weakly-Supervised Disease Localization in X-ray images
Jul 14, 2021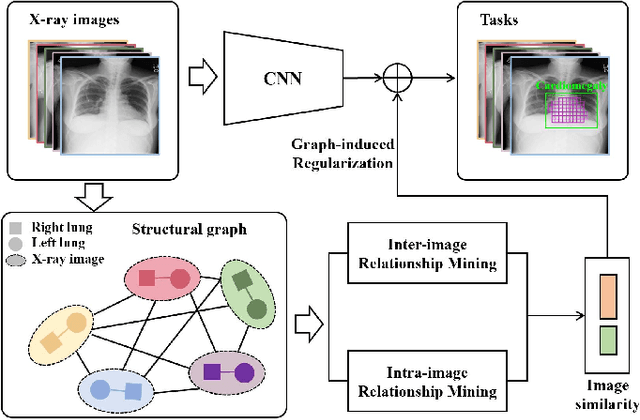
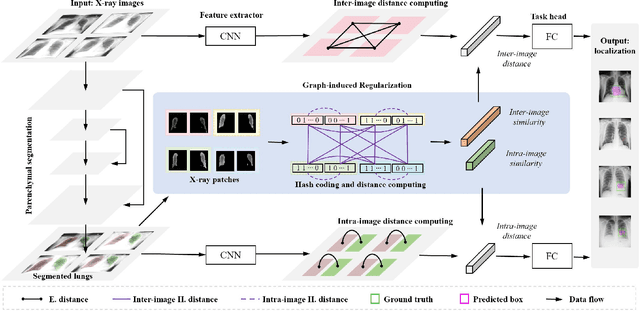
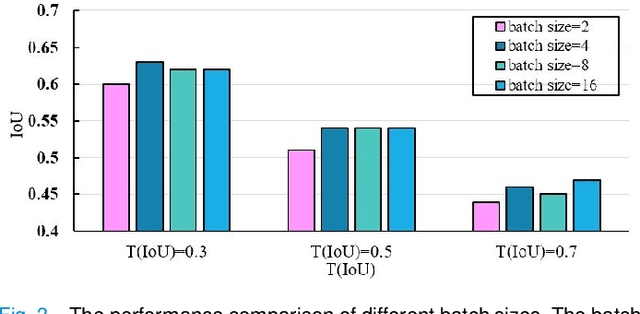
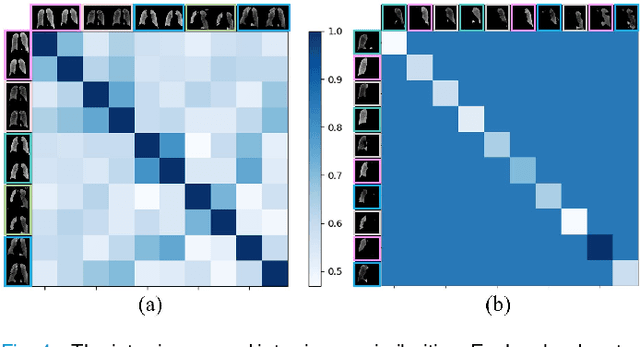
Locating diseases in chest X-ray images with few careful annotations saves large human effort. Recent works approached this task with innovative weakly-supervised algorithms such as multi-instance learning (MIL) and class activation maps (CAM), however, these methods often yield inaccurate or incomplete regions. One of the reasons is the neglection of the pathological implications hidden in the relationship across anatomical regions within each image and the relationship across images. In this paper, we argue that the cross-region and cross-image relationship, as contextual and compensating information, is vital to obtain more consistent and integral regions. To model the relationship, we propose the Graph Regularized Embedding Network (GREN), which leverages the intra-image and inter-image information to locate diseases on chest X-ray images. GREN uses a pre-trained U-Net to segment the lung lobes, and then models the intra-image relationship between the lung lobes using an intra-image graph to compare different regions. Meanwhile, the relationship between in-batch images is modeled by an inter-image graph to compare multiple images. This process mimics the training and decision-making process of a radiologist: comparing multiple regions and images for diagnosis. In order for the deep embedding layers of the neural network to retain structural information (important in the localization task), we use the Hash coding and Hamming distance to compute the graphs, which are used as regularizers to facilitate training. By means of this, our approach achieves the state-of-the-art result on NIH chest X-ray dataset for weakly-supervised disease localization. Our codes are accessible online.
Deep Transformers for Fast Small Intestine Grounding in Capsule Endoscope Video
Apr 07, 2021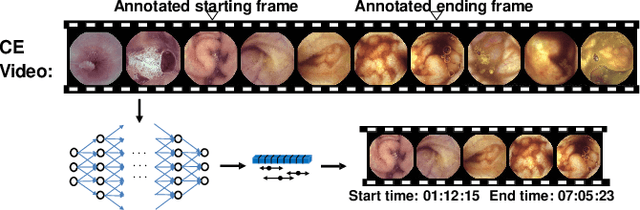
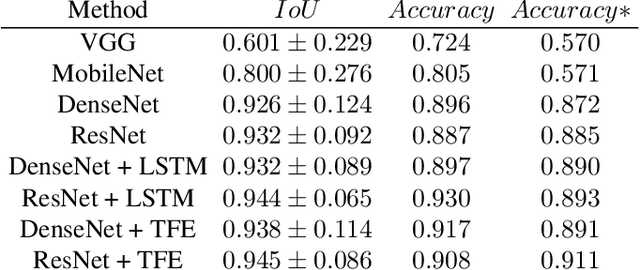
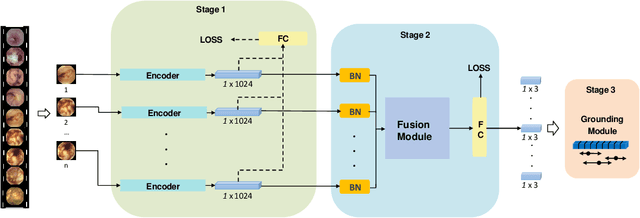
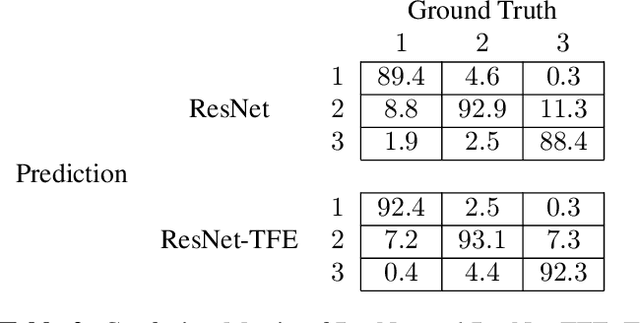
Capsule endoscopy is an evolutional technique for examining and diagnosing intractable gastrointestinal diseases. Because of the huge amount of data, analyzing capsule endoscope videos is very time-consuming and labor-intensive for gastrointestinal medicalists. The development of intelligent long video analysis algorithms for regional positioning and analysis of capsule endoscopic video is therefore essential to reduce the workload of clinicians and assist in improving the accuracy of disease diagnosis. In this paper, we propose a deep model to ground shooting range of small intestine from a capsule endoscope video which has duration of tens of hours. This is the first attempt to attack the small intestine grounding task using deep neural network method. We model the task as a 3-way classification problem, in which every video frame is categorized into esophagus/stomach, small intestine or colorectum. To explore long-range temporal dependency, a transformer module is built to fuse features of multiple neighboring frames. Based on the classification model, we devise an efficient search algorithm to efficiently locate the starting and ending shooting boundaries of the small intestine. Without searching the small intestine exhaustively in the full video, our method is implemented via iteratively separating the video segment along the direction to the target boundary in the middle. We collect 113 videos from a local hospital to validate our method. In the 5-fold cross validation, the average IoU between the small intestine segments located by our method and the ground-truths annotated by broad-certificated gastroenterologists reaches 0.945.
Densely Nested Top-Down Flows for Salient Object Detection
Feb 18, 2021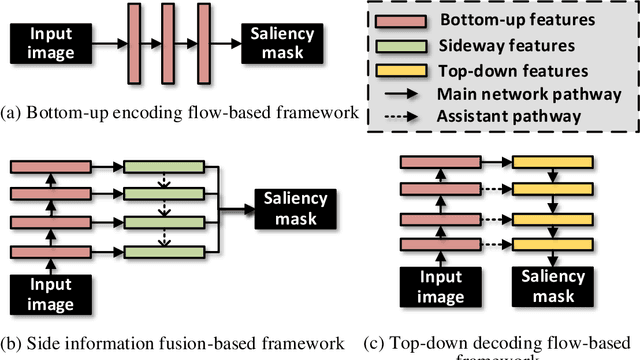
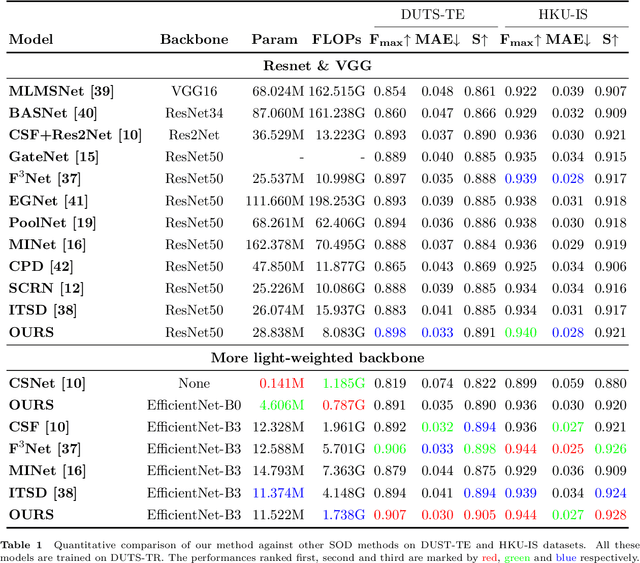
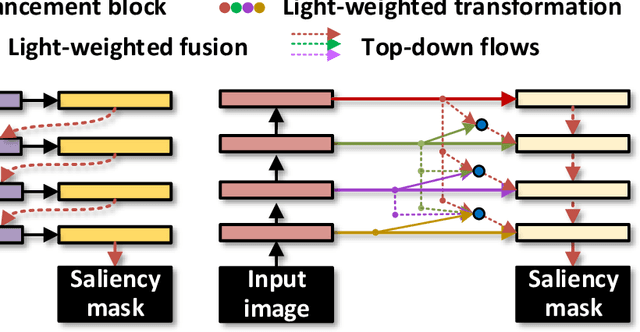
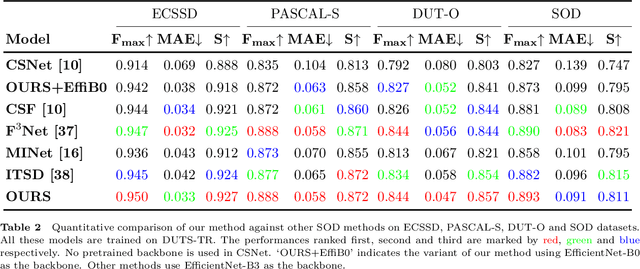
With the goal of identifying pixel-wise salient object regions from each input image, salient object detection (SOD) has been receiving great attention in recent years. One kind of mainstream SOD methods is formed by a bottom-up feature encoding procedure and a top-down information decoding procedure. While numerous approaches have explored the bottom-up feature extraction for this task, the design on top-down flows still remains under-studied. To this end, this paper revisits the role of top-down modeling in salient object detection and designs a novel densely nested top-down flows (DNTDF)-based framework. In every stage of DNTDF, features from higher levels are read in via the progressive compression shortcut paths (PCSP). The notable characteristics of our proposed method are as follows. 1) The propagation of high-level features which usually have relatively strong semantic information is enhanced in the decoding procedure; 2) With the help of PCSP, the gradient vanishing issues caused by non-linear operations in top-down information flows can be alleviated; 3) Thanks to the full exploration of high-level features, the decoding process of our method is relatively memory efficient compared against those of existing methods. Integrating DNTDF with EfficientNet, we construct a highly light-weighted SOD model, with very low computational complexity. To demonstrate the effectiveness of the proposed model, comprehensive experiments are conducted on six widely-used benchmark datasets. The comparisons to the most state-of-the-art methods as well as the carefully-designed baseline models verify our insights on the top-down flow modeling for SOD. The code of this paper is available at https://github.com/new-stone-object/DNTD.
Contralaterally Enhanced Networks for Thoracic Disease Detection
Oct 09, 2020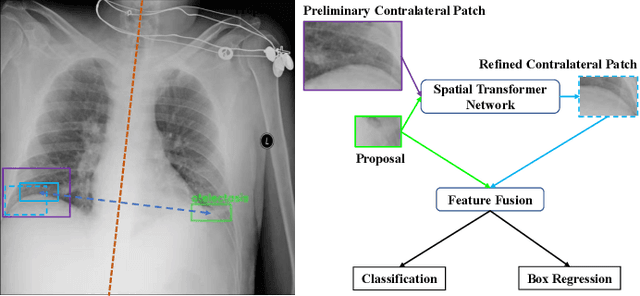

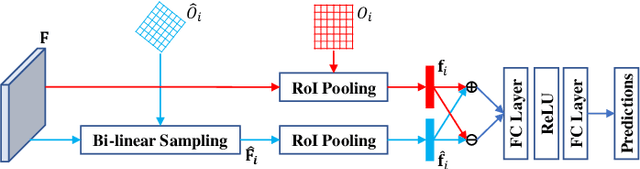
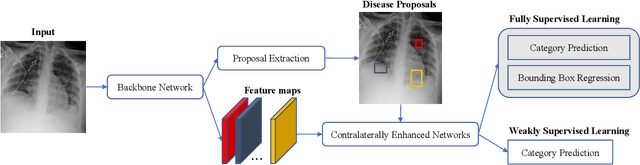
Identifying and locating diseases in chest X-rays are very challenging, due to the low visual contrast between normal and abnormal regions, and distortions caused by other overlapping tissues. An interesting phenomenon is that there exist many similar structures in the left and right parts of the chest, such as ribs, lung fields and bronchial tubes. This kind of similarities can be used to identify diseases in chest X-rays, according to the experience of broad-certificated radiologists. Aimed at improving the performance of existing detection methods, we propose a deep end-to-end module to exploit the contralateral context information for enhancing feature representations of disease proposals. First of all, under the guidance of the spine line, the spatial transformer network is employed to extract local contralateral patches, which can provide valuable context information for disease proposals. Then, we build up a specific module, based on both additive and subtractive operations, to fuse the features of the disease proposal and the contralateral patch. Our method can be integrated into both fully and weakly supervised disease detection frameworks. It achieves 33.17 AP50 on a carefully annotated private chest X-ray dataset which contains 31,000 images. Experiments on the NIH chest X-ray dataset indicate that our method achieves state-of-the-art performance in weakly-supervised disease localization.
A Single Frame and Multi-Frame Joint Network for 360-degree Panorama Video Super-Resolution
Aug 24, 2020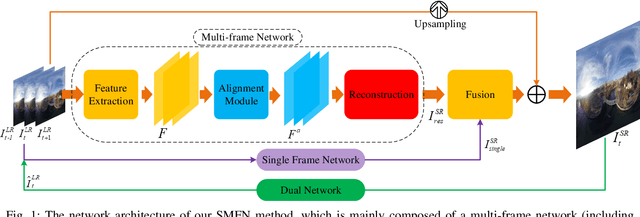
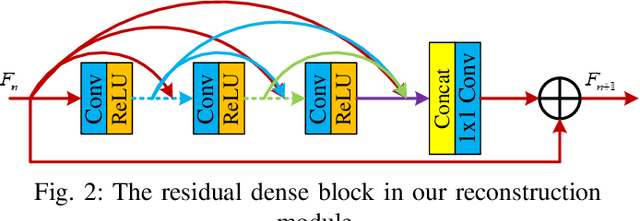
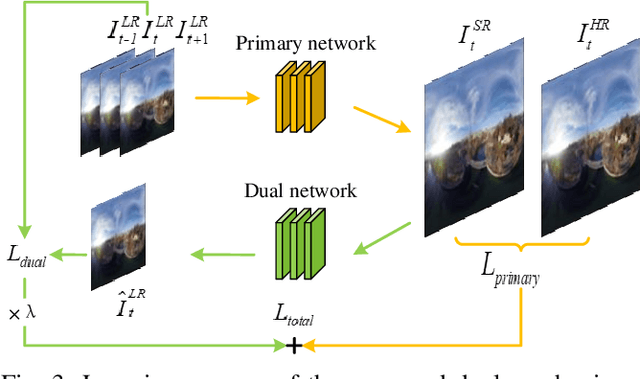

Spherical videos, also known as \ang{360} (panorama) videos, can be viewed with various virtual reality devices such as computers and head-mounted displays. They attract large amount of interest since awesome immersion can be experienced when watching spherical videos. However, capturing, storing and transmitting high-resolution spherical videos are extremely expensive. In this paper, we propose a novel single frame and multi-frame joint network (SMFN) for recovering high-resolution spherical videos from low-resolution inputs. To take advantage of pixel-level inter-frame consistency, deformable convolutions are used to eliminate the motion difference between feature maps of the target frame and its neighboring frames. A mixed attention mechanism is devised to enhance the feature representation capability. The dual learning strategy is exerted to constrain the space of solution so that a better solution can be found. A novel loss function based on the weighted mean square error is proposed to emphasize on the super-resolution of the equatorial regions. This is the first attempt to settle the super-resolution of spherical videos, and we collect a novel dataset from the Internet, MiG Panorama Video, which includes 204 videos. Experimental results on 4 representative video clips demonstrate the efficacy of the proposed method. The dataset and code are available at https://github.com/lovepiano/SMFN_For_360VSR.
PNEN: Pyramid Non-Local Enhanced Networks
Aug 22, 2020
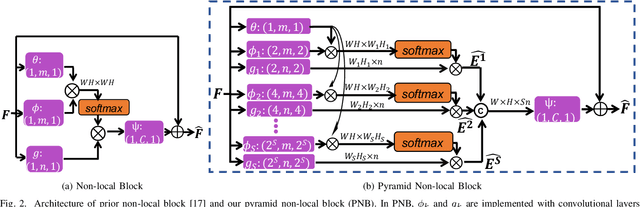


Existing neural networks proposed for low-level image processing tasks are usually implemented by stacking convolution layers with limited kernel size. Every convolution layer merely involves in context information from a small local neighborhood. More contextual features can be explored as more convolution layers are adopted. However it is difficult and costly to take full advantage of long-range dependencies. We propose a novel non-local module, Pyramid Non-local Block, to build up connection between every pixel and all remain pixels. The proposed module is capable of efficiently exploiting pairwise dependencies between different scales of low-level structures. The target is fulfilled through first learning a query feature map with full resolution and a pyramid of reference feature maps with downscaled resolutions. Then correlations with multi-scale reference features are exploited for enhancing pixel-level feature representation. The calculation procedure is economical considering memory consumption and computational cost. Based on the proposed module, we devise a Pyramid Non-local Enhanced Networks for edge-preserving image smoothing which achieves state-of-the-art performance in imitating three classical image smoothing algorithms. Additionally, the pyramid non-local block can be directly incorporated into convolution neural networks for other image restoration tasks. We integrate it into two existing methods for image denoising and single image super-resolution, achieving consistently improved performance.
Graph Neural Networks for UnsupervisedDomain Adaptation of Histopathological ImageAnalytics
Aug 21, 2020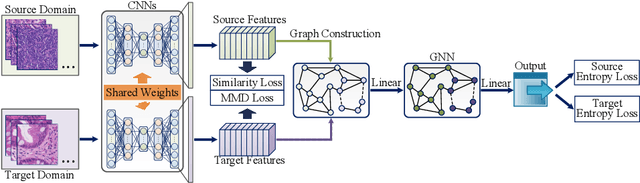

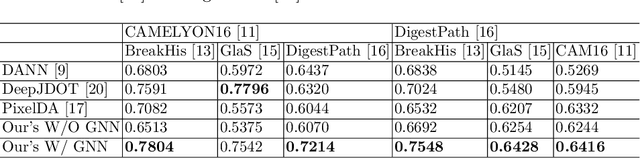
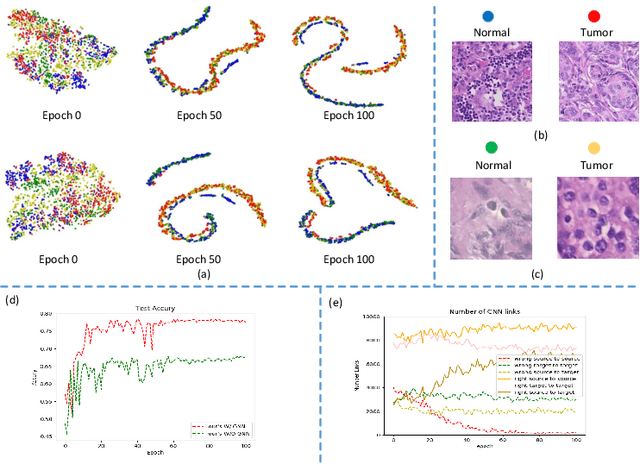
Annotating histopathological images is a time-consuming andlabor-intensive process, which requires broad-certificated pathologistscarefully examining large-scale whole-slide images from cells to tissues.Recent frontiers of transfer learning techniques have been widely investi-gated for image understanding tasks with limited annotations. However,when applied for the analytics of histology images, few of them can effec-tively avoid the performance degradation caused by the domain discrep-ancy between the source training dataset and the target dataset, suchas different tissues, staining appearances, and imaging devices. To thisend, we present a novel method for the unsupervised domain adaptationin histopathological image analysis, based on a backbone for embeddinginput images into a feature space, and a graph neural layer for propa-gating the supervision signals of images with labels. The graph model isset up by connecting every image with its close neighbors in the embed-ded feature space. Then graph neural network is employed to synthesizenew feature representation from every image. During the training stage,target samples with confident inferences are dynamically allocated withpseudo labels. The cross-entropy loss function is used to constrain thepredictions of source samples with manually marked labels and targetsamples with pseudo labels. Furthermore, the maximum mean diversityis adopted to facilitate the extraction of domain-invariant feature repre-sentations, and contrastive learning is exploited to enhance the categorydiscrimination of learned features. In experiments of the unsupervised do-main adaptation for histopathological image classification, our methodachieves state-of-the-art performance on four public datasets
Meta Corrupted Pixels Mining for Medical Image Segmentation
Jul 07, 2020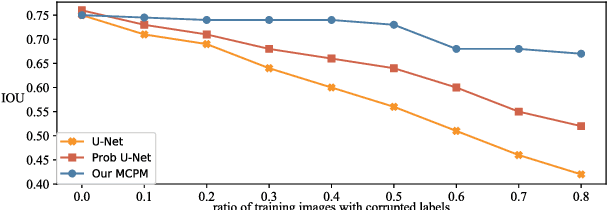
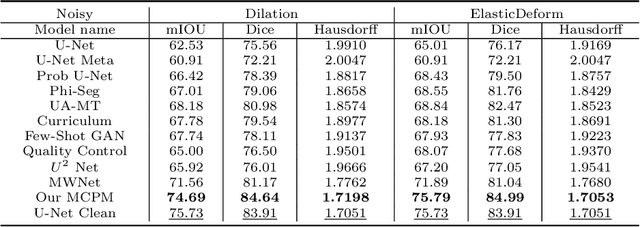
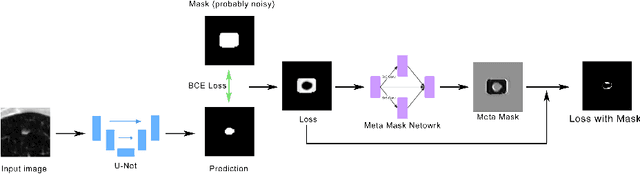

Deep neural networks have achieved satisfactory performance in piles of medical image analysis tasks. However the training of deep neural network requires a large amount of samples with high-quality annotations. In medical image segmentation, it is very laborious and expensive to acquire precise pixel-level annotations. Aiming at training deep segmentation models on datasets with probably corrupted annotations, we propose a novel Meta Corrupted Pixels Mining (MCPM) method based on a simple meta mask network. Our method is targeted at automatically estimate a weighting map to evaluate the importance of every pixel in the learning of segmentation network. The meta mask network which regards the loss value map of the predicted segmentation results as input, is capable of identifying out corrupted layers and allocating small weights to them. An alternative algorithm is adopted to train the segmentation network and the meta mask network, simultaneously. Extensive experimental results on LIDC-IDRI and LiTS datasets show that our method outperforms state-of-the-art approaches which are devised for coping with corrupted annotations.
Globally Guided Progressive Fusion Network for 3D Pancreas Segmentation
Nov 23, 2019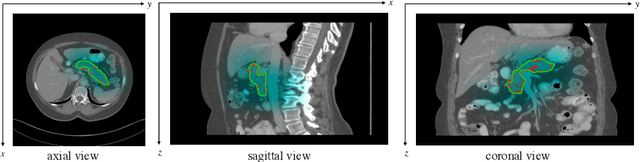
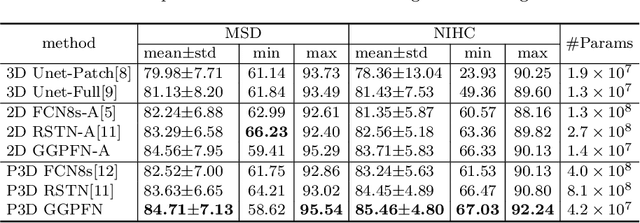
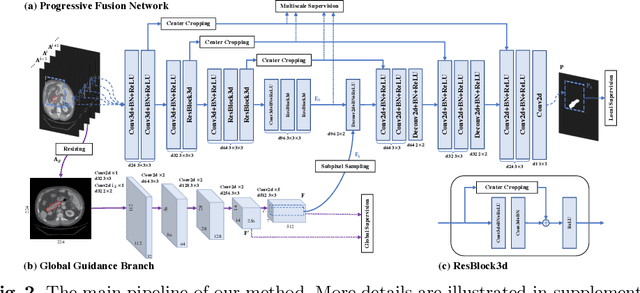
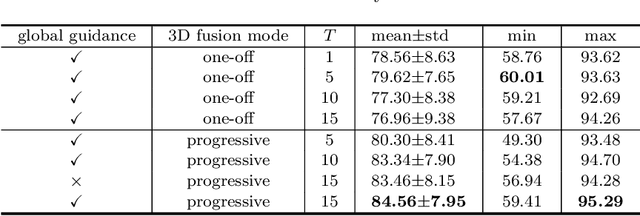
Recently 3D volumetric organ segmentation attracts much research interest in medical image analysis due to its significance in computer aided diagnosis. This paper aims to address the pancreas segmentation task in 3D computed tomography volumes. We propose a novel end-to-end network, Globally Guided Progressive Fusion Network, as an effective and efficient solution to volumetric segmentation, which involves both global features and complicated 3D geometric information. A progressive fusion network is devised to extract 3D information from a moderate number of neighboring slices and predict a probability map for the segmentation of each slice. An independent branch for excavating global features from downsampled slices is further integrated into the network. Extensive experimental results demonstrate that our method achieves state-of-the-art performance on two pancreas datasets.