 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-Fest: Few-shot based Attention Network for Driver's Vigilance Estimation with EEG Signals
Nov 07, 2022A lack of driver's vigilance is the main cause of most vehicle crashes. Electroencephalography(EEG) has been reliable and efficient tool for drivers' drowsiness estimation. Even though previous studies have developed accurate and robust driver's vigilance detection algorithms, these methods are still facing challenges on following areas: (a) small sample size training, (b) anomaly signal detection, and (c) subject-independent classification. In this paper, we propose a generalized few-shot model, namely EEG-Fest, to improve aforementioned drawbacks. The EEG-Fest model can (a) classify the query sample's drowsiness with a few samples, (b) identify whether a query sample is anomaly signals or not, and (c) achieve subject independent classification. The proposed algorithm achieves state-of-the-art results on the SEED-VIG dataset and the SADT dataset. The accuracy of the drowsy class achieves 92% and 94% for 1-shot and 5-shot support samples in the SEED-VIG dataset, and 62% and 78% for 1-shot and 5-shot support samples in the SADT dataset.
Number-Adaptive Prototype Learning for 3D Point Cloud Semantic Segmentation
Oct 18, 2022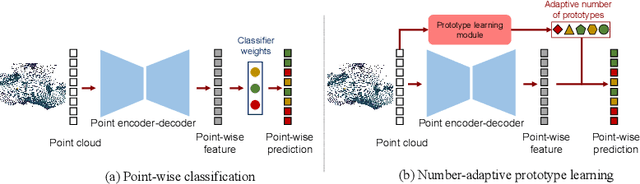
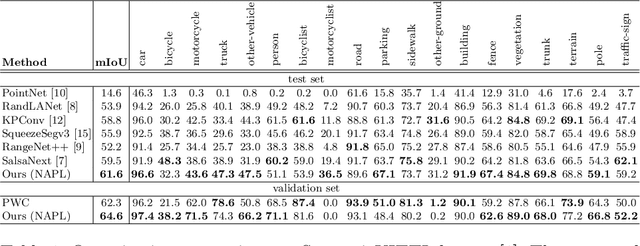
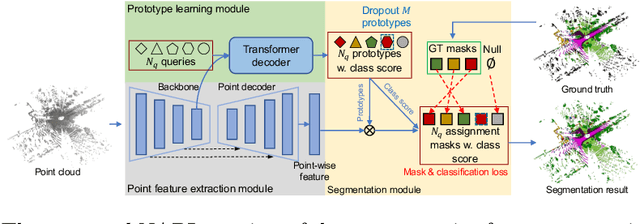
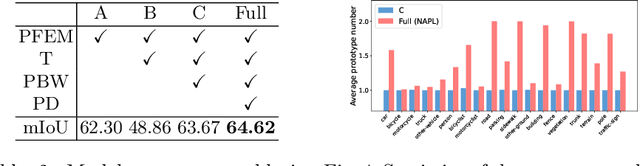
3D point cloud semantic segmentation is one of the fundamental tasks for 3D scene understanding and has been widely used in the metaverse applications. Many recent 3D semantic segmentation methods learn a single prototype (classifier weights) for each semantic class, and classify 3D points according to their nearest prototype. However, learning only one prototype for each class limits the model's ability to describe the high variance patterns within a class. Instead of learning a single prototype for each class, in this paper, we propose to use an adaptive number of prototypes to dynamically describe the different point patterns within a semantic class. With the powerful capability of vision transformer, we design a Number-Adaptive Prototype Learning (NAPL) model for point cloud semantic segmentation. To train our NAPL model, we propose a simple yet effective prototype dropout training strategy, which enables our model to adaptively produce prototypes for each class. The experimental results on SemanticKITTI dataset demonstrate that our method achieves 2.3% mIoU improvement over the baseline model based on the point-wise classification paradigm.
Neural Methods for Logical Reasoning Over Knowledge Graphs
Sep 28, 2022



Reasoning is a fundamental problem for computers and deeply studied in Artificial Intelligence. In this paper, we specifically focus on answering multi-hop logical queries on Knowledge Graphs (KGs). This is a complicated task because, in real-world scenarios, the graphs tend to be large and incomplete. Most previous works have been unable to create models that accept full First-Order Logical (FOL) queries, which include negative queries, and have only been able to process a limited set of query structures. Additionally, most methods present logic operators that can only perform the logical operation they are made for. We introduce a set of models that use Neural Networks to create one-point vector embeddings to answer the queries. The versatility of neural networks allows the framework to handle FOL queries with Conjunction ($\wedge$), Disjunction ($\vee$) and Negation ($\neg$) operators. We demonstrate experimentally the performance of our model through extensive experimentation on well-known benchmarking datasets. Besides having more versatile operators, the models achieve a 10\% relative increase over the best performing state of the art and more than 30\% over the original method based on single-point vector embeddings.
* 14 pages, 5 figures, 11 tables
CARE: Certifiably Robust Learning with Reasoning via Variational Inference
Sep 12, 2022


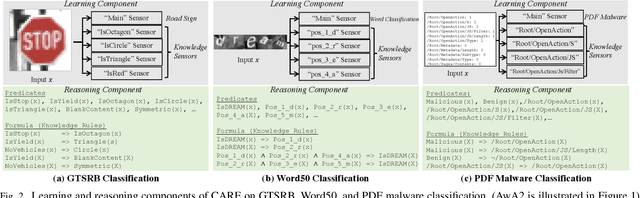
Despite great recent advances achieved by deep neural networks (DNNs), they are often vulnerable to adversarial attacks. Intensive research efforts have been made to improve the robustness of DNNs; however, most empirical defenses can be adaptively attacked again, and the theoretically certified robustness is limited, especially on large-scale datasets. One potential root cause of such vulnerabilities for DNNs is that although they have demonstrated powerful expressiveness, they lack the reasoning ability to make robust and reliable predictions. In this paper, we aim to integrate domain knowledge to enable robust learning with the reasoning paradigm. In particular, we propose a certifiably robust learning with reasoning pipeline (CARE), which consists of a learning component and a reasoning component. Concretely, we use a set of standard DNNs to serve as the learning component to make semantic predictions, and we leverage the probabilistic graphical models, such as Markov logic networks (MLN), to serve as the reasoning component to enable knowledge/logic reasoning. However, it is known that the exact inference of MLN (reasoning) is #P-complete, which limits the scalability of the pipeline. To this end, we propose to approximate the MLN inference via variational inference based on an efficient expectation maximization algorithm. In particular, we leverage graph convolutional networks (GCNs) to encode the posterior distribution during variational inference and update the parameters of GCNs (E-step) and the weights of knowledge rules in MLN (M-step) iteratively. We conduct extensive experiments on different datasets and show that CARE achieves significantly higher certified robustness compared with the state-of-the-art baselines. We additionally conducted different ablation studies to demonstrate the empirical robustness of CARE and the effectiveness of different knowledge integration.
Improving Privacy-Preserving Vertical Federated Learning by Efficient Communication with ADMM
Jul 22, 2022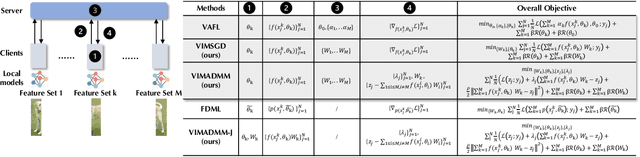
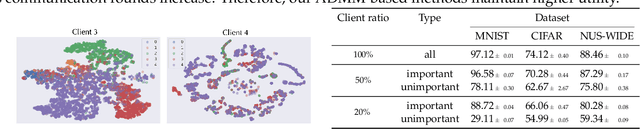
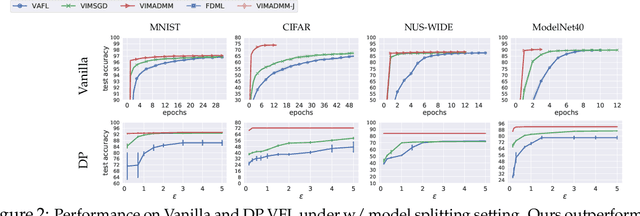

Federated learning (FL) enables distributed devices to jointly train a shared model while keeping the training data local. Different from the horizontal FL (HFL) setting where each client has partial data samples, vertical FL (VFL), which allows each client to collect partial features, has attracted intensive research efforts recently. In this paper, we identified two challenges that state-of-the-art VFL frameworks are facing: (1) some works directly average the learned feature embeddings and therefore might lose the unique properties of each local feature set; (2) server needs to communicate gradients with the clients for each training step, incurring high communication cost that leads to rapid consumption of privacy budgets. In this paper, we aim to address the above challenges and propose an efficient VFL with multiple linear heads (VIM) framework, where each head corresponds to local clients by taking the separate contribution of each client into account. In addition, we propose an Alternating Direction Method of Multipliers (ADMM)-based method to solve our optimization problem, which reduces the communication cost by allowing multiple local updates in each step, and thus leads to better performance under differential privacy. We consider various settings including VFL with model splitting and without model splitting. For both settings, we carefully analyze the differential privacy mechanism for our framework. Moreover, we show that a byproduct of our framework is that the weights of learned linear heads reflect the importance of local clients. We conduct extensive evaluations and show that on four real-world datasets, VIM achieves significantly higher performance and faster convergence compared with state-of-the-arts. We also explicitly evaluate the importance of local clients and show that VIM enables functionalities such as client-level explanation and client denoising.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022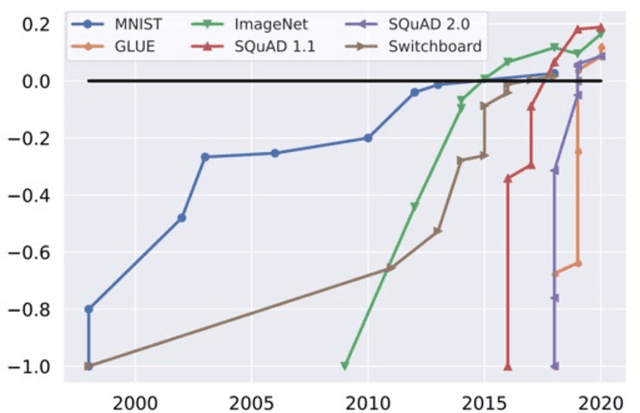
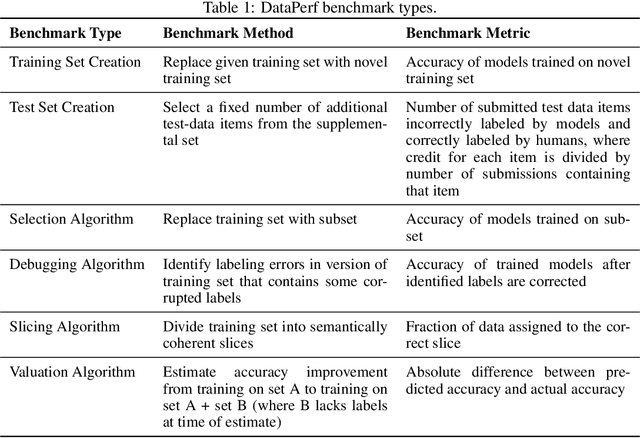
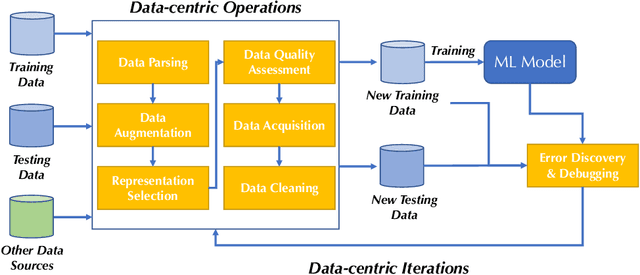
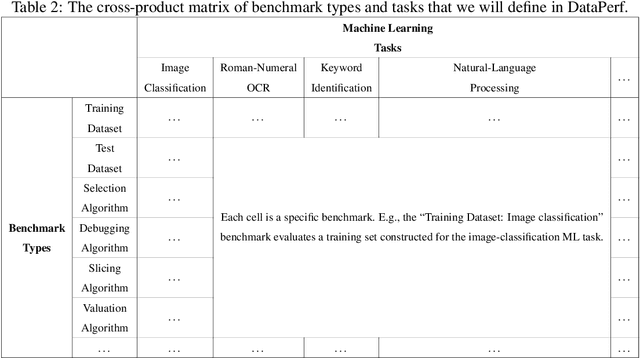
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Keyword Extraction in Scientific Documents
Jul 07, 2022


The scientific publication output grows exponentially. Therefore, it is increasingly challenging to keep track of trends and changes. Understanding scientific documents is an important step in downstream tasks such as knowledge graph building, text mining, and discipline classification. In this workshop, we provide a better understanding of keyword and keyphrase extraction from the abstract of scientific publications.
GraphFramEx: Towards Systematic Evaluation of Explainability Methods for Graph Neural Networks
Jun 30, 2022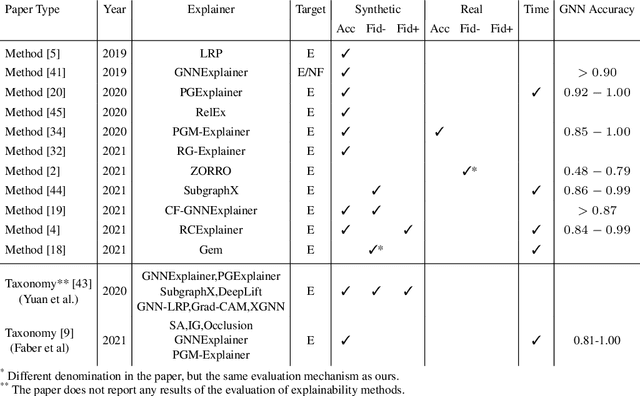
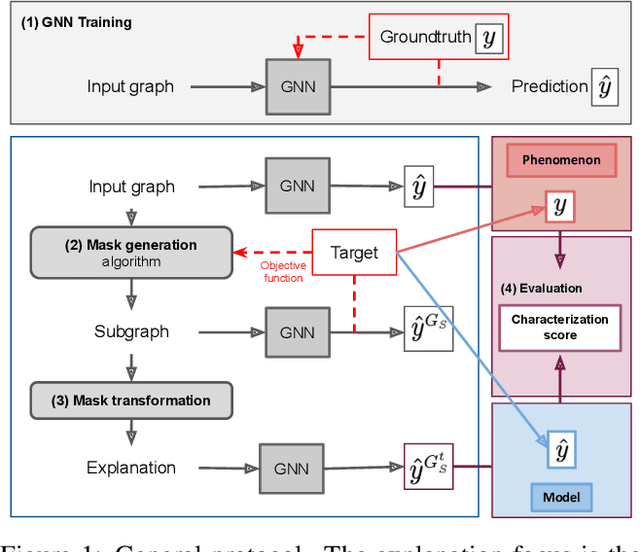
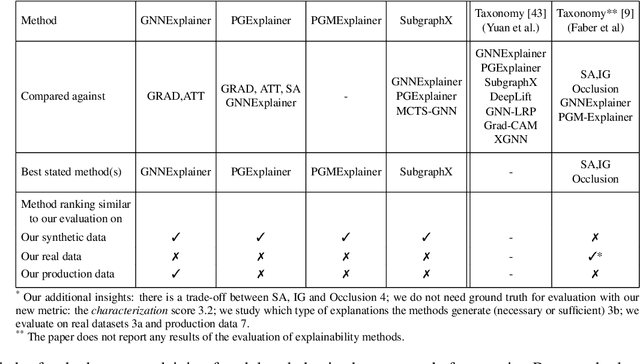
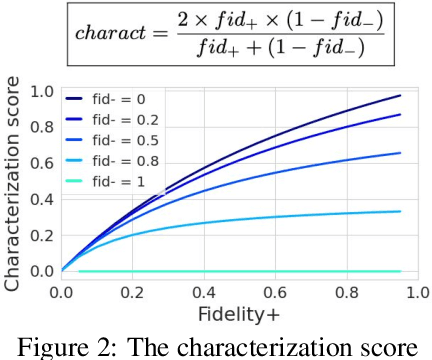
As one of the most popular machine learning models today, graph neural networks (GNNs) have attracted intense interest recently, and so does their explainability. Users are increasingly interested in a better understanding of GNN models and their outcomes. Unfortunately, today's evaluation frameworks for GNN explainability often rely on synthetic datasets, leading to conclusions of limited scope due to a lack of complexity in the problem instances. As GNN models are deployed to more mission-critical applications, we are in dire need for a common evaluation protocol of explainability methods of GNNs. In this paper, we propose, to our best knowledge, the first systematic evaluation framework for GNN explainability, considering explainability on three different "user needs:" explanation focus, mask nature, and mask transformation. We propose a unique metric that combines the fidelity measures and classify explanations based on their quality of being sufficient or necessary. We scope ourselves to node classification tasks and compare the most representative techniques in the field of input-level explainability for GNNs. For the widely used synthetic benchmarks, surprisingly shallow techniques such as personalized PageRank have the best performance for a minimum computation time. But when the graph structure is more complex and nodes have meaningful features, gradient-based methods, in particular Saliency, are the best according to our evaluation criteria. However, none dominates the others on all evaluation dimensions and there is always a trade-off. We further apply our evaluation protocol in a case study on eBay graphs to reflect the production environment.
Efficient End-to-End AutoML via Scalable Search Space Decomposition
Jun 24, 2022End-to-end AutoML has attracted intensive interests from both academia and industry which automatically searches for ML pipelines in a space induced by feature engineering, algorithm/model selection, and hyper-parameter tuning. Existing AutoML systems, however, suffer from scalability issues when applying to application domains with large, high-dimensional search spaces. We present VolcanoML, a scalable and extensible framework that facilitates systematic exploration of large AutoML search spaces. VolcanoML introduces and implements basic building blocks that decompose a large search space into smaller ones, and allows users to utilize these building blocks to compose an execution plan for the AutoML problem at hand. VolcanoML further supports a Volcano-style execution model -- akin to the one supported by modern database systems -- to execute the plan constructed. Our evaluation demonstrates that, not only does VolcanoML raise the level of expressiveness for search space decomposition in AutoML, it also leads to actual findings of decomposition strategies that are significantly more efficient than the ones employed by state-of-the-art AutoML systems such as auto-sklearn. This paper is the extended version of the initial VolcanoML paper appeared in VLDB 2021.
* This paper is an extended version of the initial VolcanoML paper (li et al. VLDB 2021). arXiv admin note: substantial text overlap with arXiv:2107.08861
FedHPO-B: A Benchmark Suite for Federated Hyperparameter Optimization
Jun 20, 2022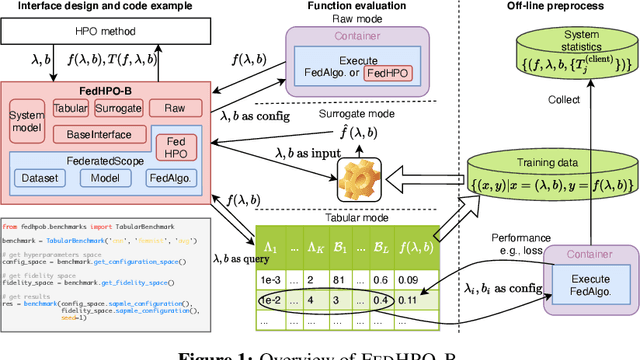
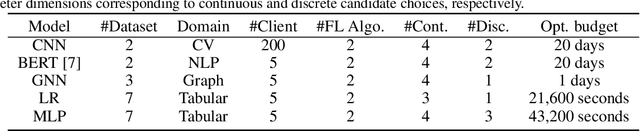
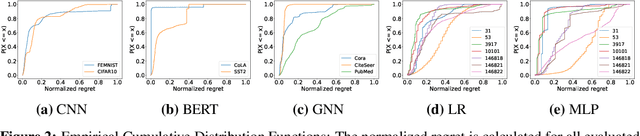

Hyperparameter optimization (HPO) is crucial for machine learning algorithms to achieve satisfactory performance, whose progress has been boosted by related benchmarks. Nonetheless, existing efforts in benchmarking all focus on HPO for traditional centralized learning while ignoring federated learning (FL), a promising paradigm for collaboratively learning models from dispersed data. In this paper, we first identify some uniqueness of HPO for FL algorithms from various aspects. Due to this uniqueness, existing HPO benchmarks no longer satisfy the need to compare HPO methods in the FL setting. To facilitate the research of HPO in the FL setting, we propose and implement a benchmark suite FedHPO-B that incorporates comprehensive FL tasks, enables efficient function evaluations, and eases continuing extensions. We also conduct extensive experiments based on FedHPO-B to benchmark a few HPO methods. We open-source FedHPO-B at https://github.com/alibaba/FederatedScope/tree/master/benchmark/FedHPOB.