 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation
Paper and Code
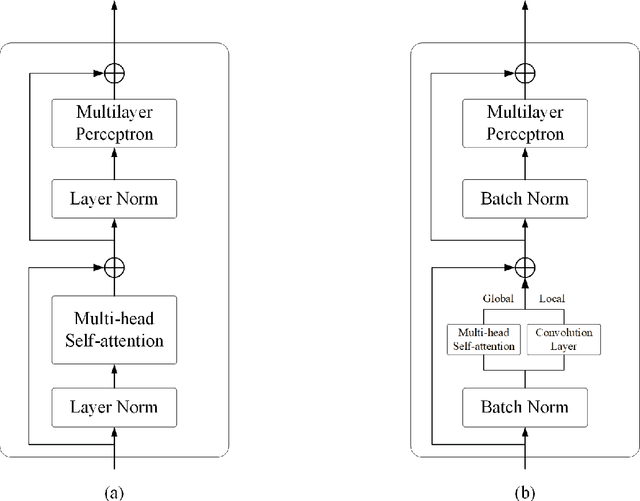

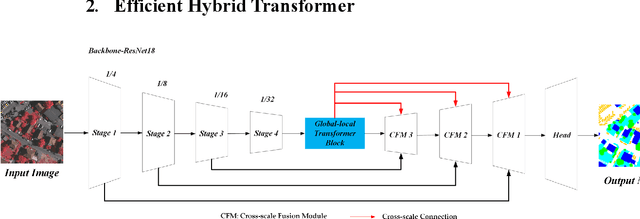
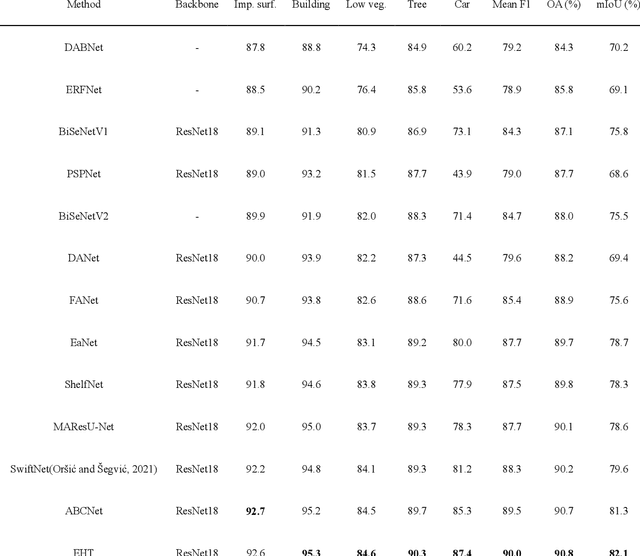
Semantic segmentation of fine-resolution urban scene images plays a vital role in extensive practical applications, such as land cover mapping, urban change detection, environmental protection and economic assessment. Driven by rapid developments in deep learning technologies, the convolutional neural network (CNN) has dominated the semantic segmentation task for many years. Convolutional neural networks adopt hierarchical feature representation, demonstrating strong local information extraction. However, the local property of the convolution layer limits the network from capturing global context that is crucial for precise segmentation. Recently, Transformer comprise a hot topic in the computer vision domain. Transformer demonstrates the great capability of global information modelling, boosting many vision tasks, such as image classification, object detection and especially semantic segmentation. In this paper, we propose an efficient hybrid Transformer (EHT) for real-time urban scene segmentation. The EHT adopts a hybrid structure with and CNN-based encoder and a transformer-based decoder, learning global-local context with lower computation. Extensive experiments demonstrate that our EHT has faster inference speed with competitive accuracy compared with state-of-the-art lightweight models. Specifically, the proposed EHT achieves a 66.9% mIoU on the UAVid test set and outperforms other benchmark networks significantly. The code will be available soon.