 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Small Area Change Detection from SAR Imagery Using Deep Learning
Nov 22, 2020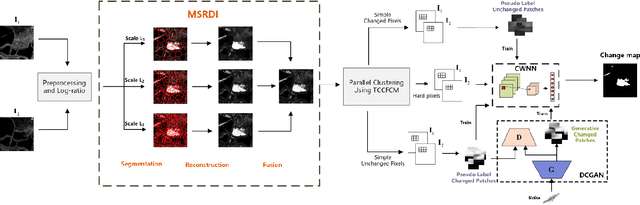
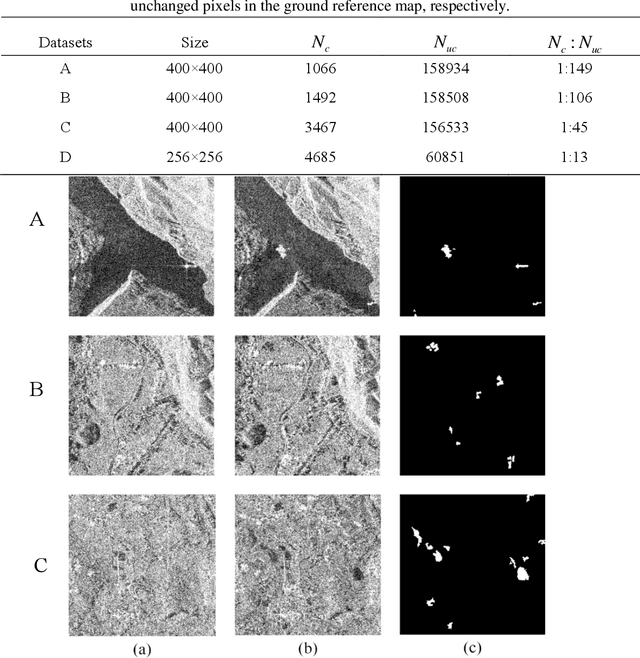
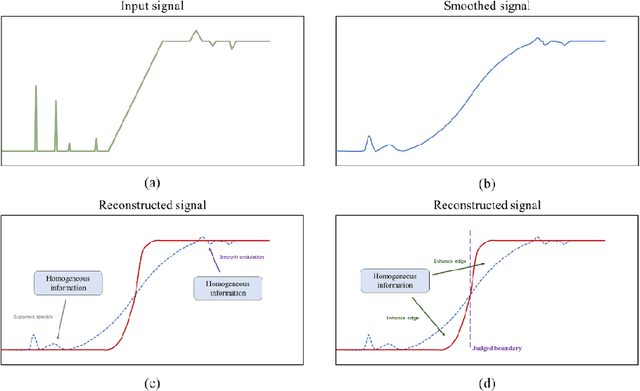
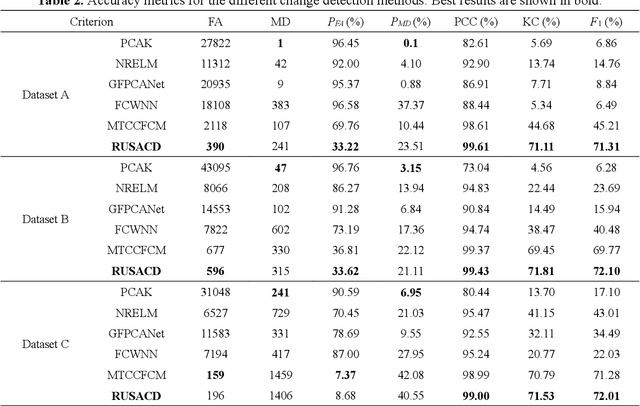
Small area change detection from synthetic aperture radar (SAR) is a highly challenging task. In this paper, a robust unsupervised approach is proposed for small area change detection from multi-temporal SAR images using deep learning. First, a multi-scale superpixel reconstruction method is developed to generate a difference image (DI), which can suppress the speckle noise effectively and enhance edges by exploiting local, spatially homogeneous information. Second, a two-stage centre-constrained fuzzy c-means clustering algorithm is proposed to divide the pixels of the DI into changed, unchanged and intermediate classes with a parallel clustering strategy. Image patches belonging to the first two classes are then constructed as pseudo-label training samples, and image patches of the intermediate class are treated as testing samples. Finally, a convolutional wavelet neural network (CWNN) is designed and trained to classify testing samples into changed or unchanged classes, coupled with a deep convolutional generative adversarial network (DCGAN) to increase the number of changed class within the pseudo-label training samples. Numerical experiments on four real SAR datasets demonstrate the validity and robustness of the proposed approach, achieving up to 99.61% accuracy for small area change detection.
Learning User Representations with Hypercuboids for Recommender Systems
Nov 11, 2020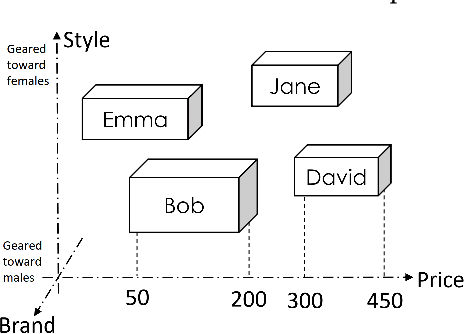
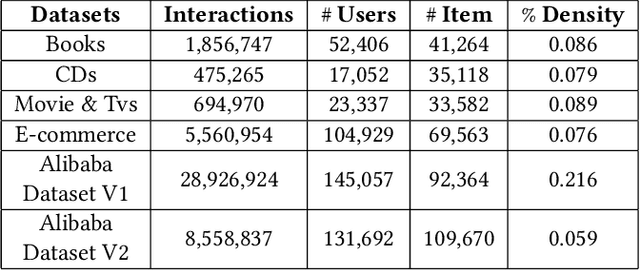
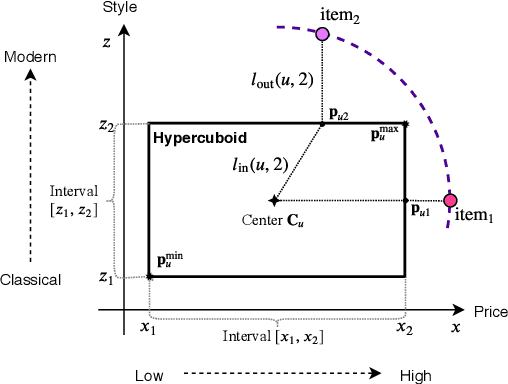
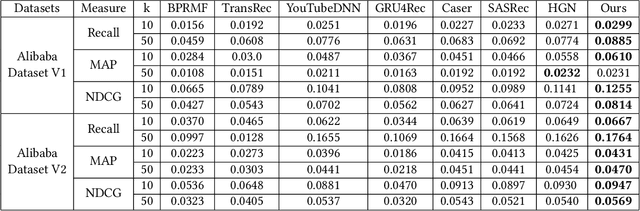
Modeling user interests is crucial in real-world recommender systems. In this paper, we present a new user interest representation model for personalized recommendation. Specifically, the key novelty behind our model is that it explicitly models user interests as a hypercuboid instead of a point in the space. In our approach, the recommendation score is learned by calculating a compositional distance between the user hypercuboid and the item. This helps to alleviate the potential geometric inflexibility of existing collaborative filtering approaches, enabling a greater extent of modeling capability. Furthermore, we present two variants of hypercuboids to enhance the capability in capturing the diversities of user interests. A neural architecture is also proposed to facilitate user hypercuboid learning by capturing the activity sequences (e.g., buy and rate) of users. We demonstrate the effectiveness of our proposed model via extensive experiments on both public and commercial datasets. Empirical results show that our approach achieves very promising results, outperforming existing state-of-the-art.
Online Active Model Selection for Pre-trained Classifiers
Oct 21, 2020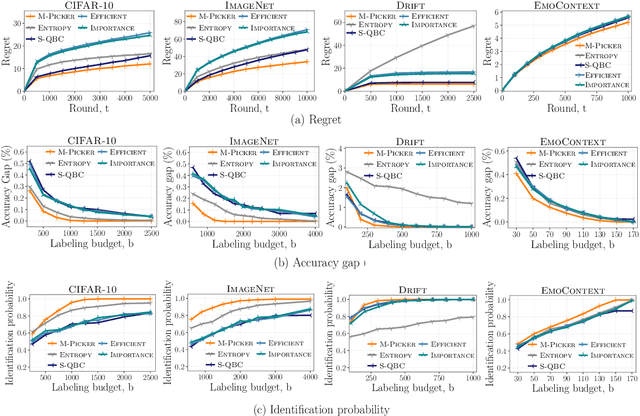
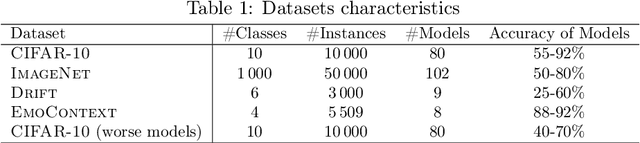

Given $k$ pre-trained classifiers and a stream of unlabeled data examples, how can we actively decide when to query a label so that we can distinguish the best model from the rest while making a small number of queries? Answering this question has a profound impact on a range of practical scenarios. In this work, we design an online selective sampling approach that actively selects informative examples to label and outputs the best model with high probability at any round. Our algorithm can be used for online prediction tasks for both adversarial and stochastic streams. We establish several theoretical guarantees for our algorithm and extensively demonstrate its effectiveness in our experimental studies.
On Automatic Feasibility Study for Machine Learning Application Development with ease.ml/snoopy
Oct 16, 2020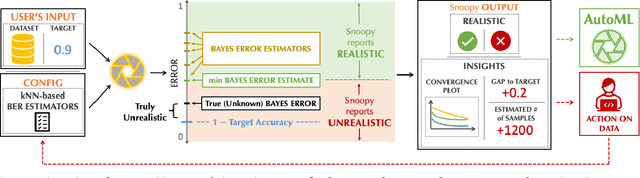
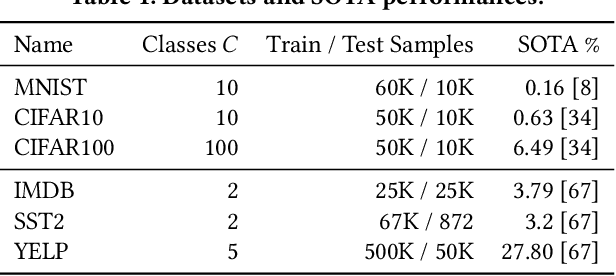
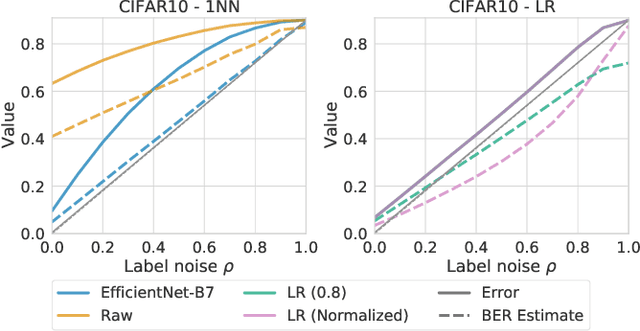

In our experience working with domain experts who are using today's AutoML systems, a common problem we encountered is what we call Unrealistic Expectation: When users have access to very noisy or challenging datasets, whilst being expected to achieve startlingly high accuracy with ML. Consequently, many computationally expensive AutoML runs and labour-intensive ML development processes are predestined to fail from the beginning. In traditional software engineering, this problem is addressed via a feasibility study, an indispensable step before developing any software system. In this paper we present ease.ml/snoopy with the goal of preforming an automatic feasibility study before building ML applications. A user provides inputs in the form of a dataset and a quality target (e.g., expected accuracy $>$ 0.8) and the system returns its deduction on whether this target is achievable using ML given the input data. We formulate this problem as estimating the irreducible error of the underlying task, also known as the Bayes error. The key contribution of this work is the study of this problem from a system's and empirical perspective -- we (1) propose practical "compromises" that enable the application of Bayes error estimators and (2) develop an evaluation framework that compares different estimators empirically on real-world data. We then systematically explore the design space by evaluating a range of estimators, reporting not only the improvements of our proposed estimator but also limitations of both our method and existing estimators.
On Convergence of Nearest Neighbor Classifiers over Feature Transformations
Oct 15, 2020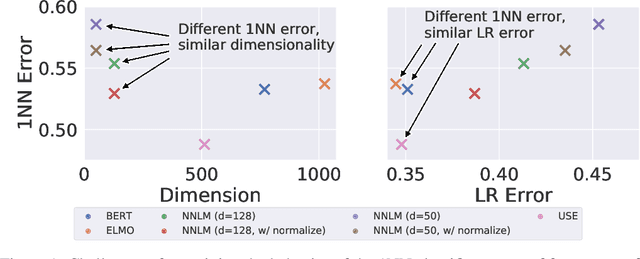
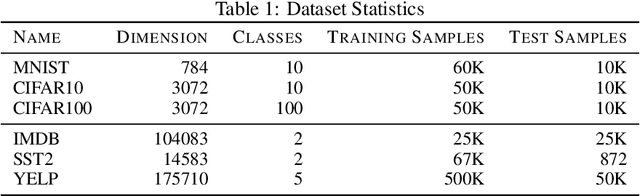
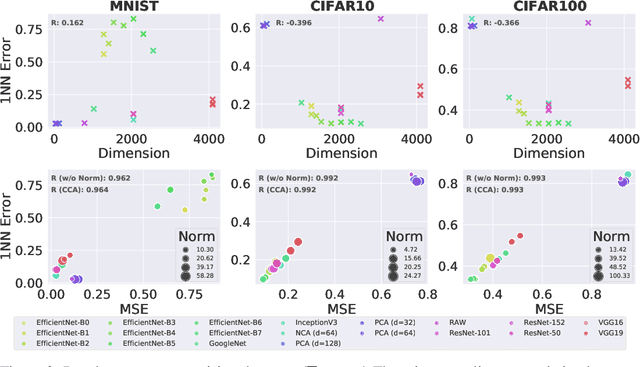
The k-Nearest Neighbors (kNN) classifier is a fundamental non-parametric machine learning algorithm. However, it is well known that it suffers from the curse of dimensionality, which is why in practice one often applies a kNN classifier on top of a (pre-trained) feature transformation. From a theoretical perspective, most, if not all theoretical results aimed at understanding the kNN classifier are derived for the raw feature space. This leads to an emerging gap between our theoretical understanding of kNN and its practical applications. In this paper, we take a first step towards bridging this gap. We provide a novel analysis on the convergence rates of a kNN classifier over transformed features. This analysis requires in-depth understanding of the properties that connect both the transformed space and the raw feature space. More precisely, we build our convergence bound upon two key properties of the transformed space: (1) safety -- how well can one recover the raw posterior from the transformed space, and (2) smoothness -- how complex this recovery function is. Based on our result, we are able to explain why some (pre-trained) feature transformations are better suited for a kNN classifier than other. We empirically validate that both properties have an impact on the kNN convergence on 30 feature transformations with 6 benchmark datasets spanning from the vision to the text domain.
Which Model to Transfer? Finding the Needle in the Growing Haystack
Oct 13, 2020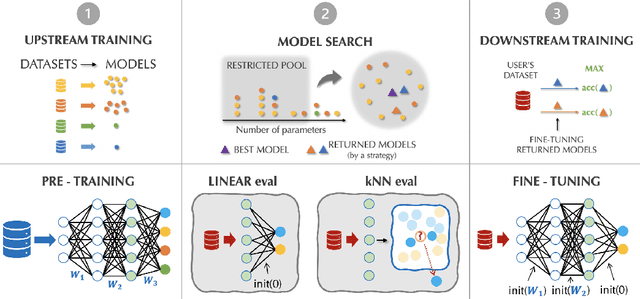
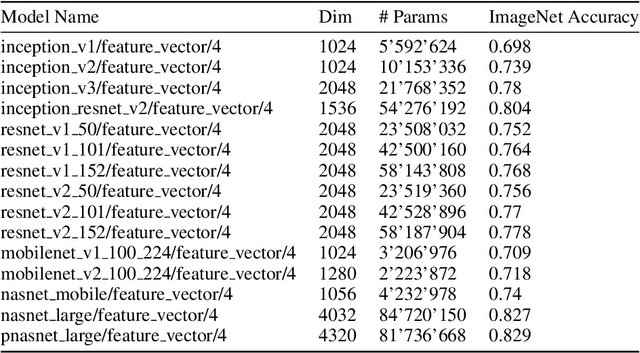
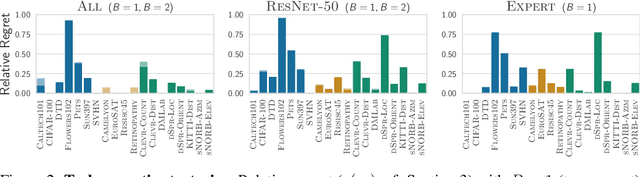
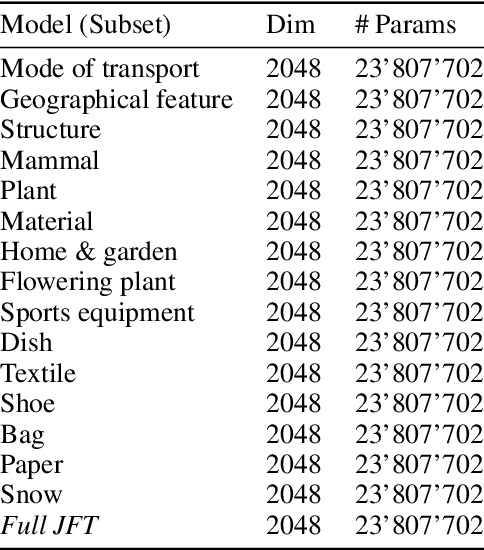
Transfer learning has been recently popularized as a data-efficient alternative to training models from scratch, in particular in vision and NLP where it provides a remarkably solid baseline. The emergence of rich model repositories, such as TensorFlow Hub, enables the practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. We provide a formalization of this problem through a familiar notion of regret and introduce the predominant strategies, namely task-agnostic (e.g. picking the highest scoring ImageNet model) and task-aware search strategies (such as linear or kNN evaluation). We conduct a large-scale empirical study and show that both task-agnostic and task-aware methods can yield high regret. We then propose a simple and computationally efficient hybrid search strategy which outperforms the existing approaches. We highlight the practical benefits of the proposed solution on a set of 19 diverse vision tasks.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020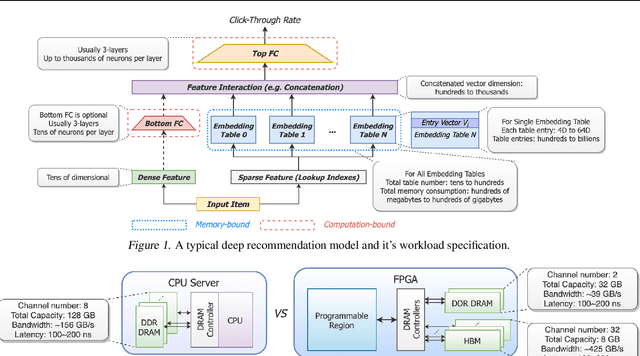
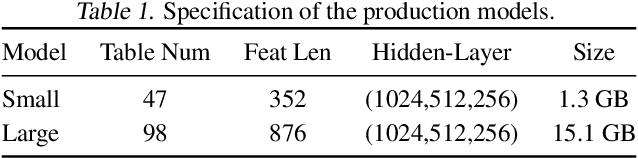
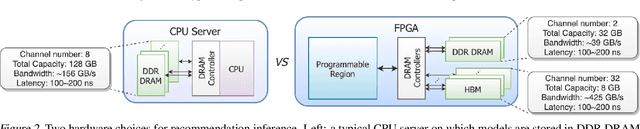
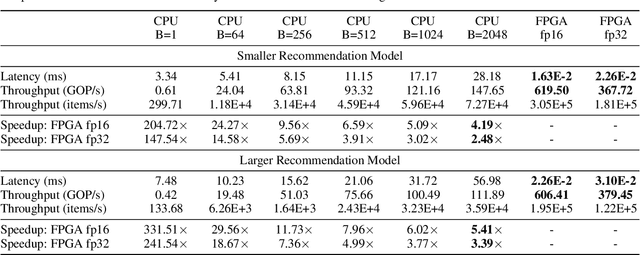
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.
Optimal Provable Robustness of Quantum Classification via Quantum Hypothesis Testing
Sep 21, 2020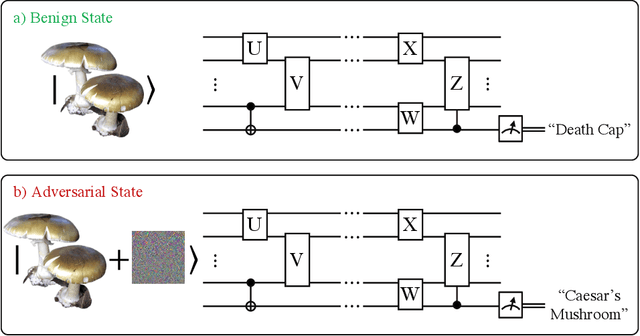
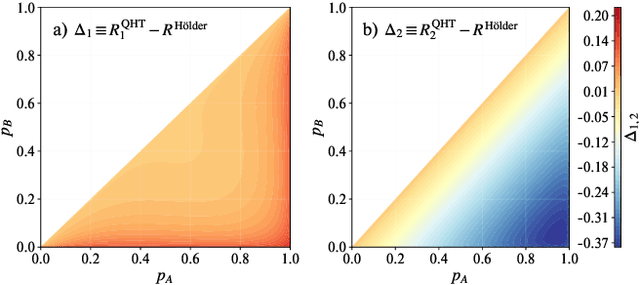

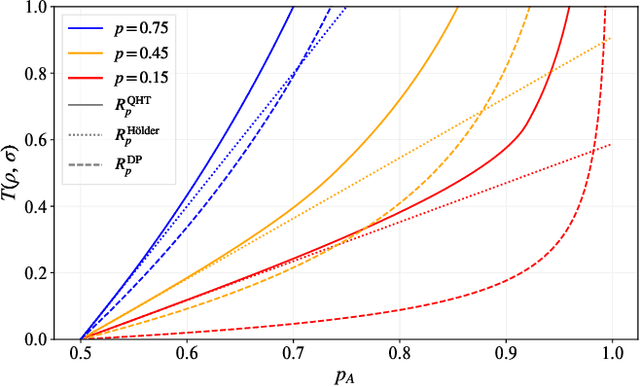
Quantum machine learning models have the potential to offer speedups and better predictive accuracy compared to their classical counterparts. However, these quantum algorithms, like their classical counterparts, have been shown to also be vulnerable to input perturbations, in particular for classification problems. These can arise either from noisy implementations or, as a worst-case type of noise, adversarial attacks. These attacks can undermine both the reliability and security of quantum classification algorithms. In order to develop defence mechanisms and to better understand the reliability of these algorithms, it is crucial to understand their robustness properties in presence of both natural noise sources and adversarial manipulation. From the observation that, unlike in the classical setting, measurements involved in quantum classification algorithms are naturally probabilistic, we uncover and formalize a fundamental link between binary quantum hypothesis testing (QHT) and provably robust quantum classification. Then from the optimality of QHT, we prove a robustness condition, which is tight under modest assumptions, and enables us to develop a protocol to certify robustness. Since this robustness condition is a guarantee against the worst-case noise scenarios, our result naturally extends to scenarios in which the noise source is known. Thus we also provide a framework to study the reliability of quantum classification protocols under more general settings.
A Principled Approach to Data Valuation for Federated Learning
Sep 14, 2020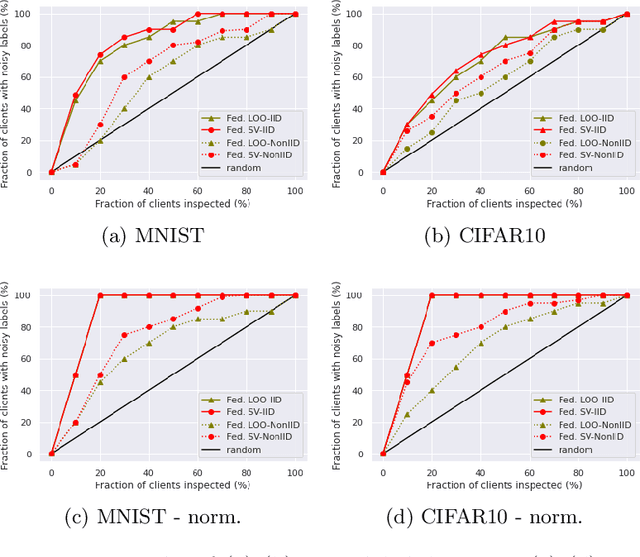

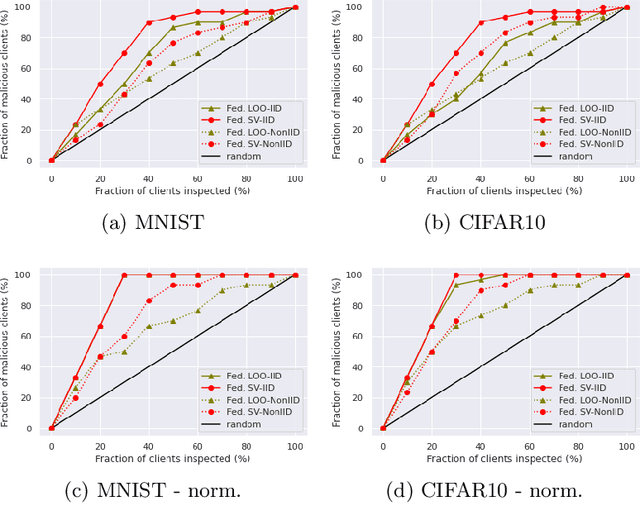
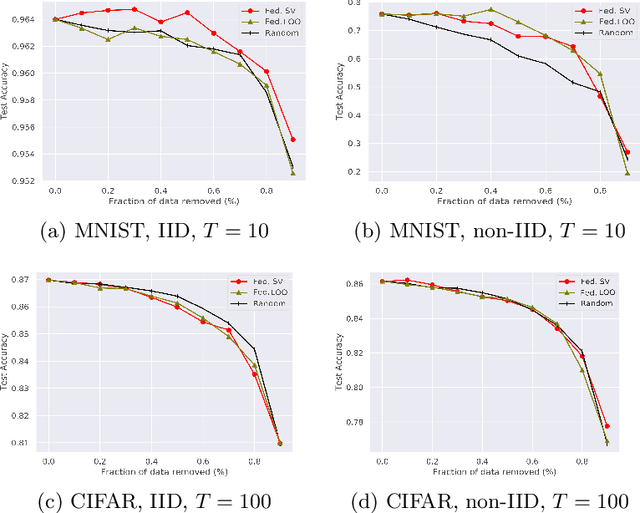
Federated learning (FL) is a popular technique to train machine learning (ML) models on decentralized data sources. In order to sustain long-term participation of data owners, it is important to fairly appraise each data source and compensate data owners for their contribution to the training process. The Shapley value (SV) defines a unique payoff scheme that satisfies many desiderata for a data value notion. It has been increasingly used for valuing training data in centralized learning. However, computing the SV requires exhaustively evaluating the model performance on every subset of data sources, which incurs prohibitive communication cost in the federated setting. Besides, the canonical SV ignores the order of data sources during training, which conflicts with the sequential nature of FL. This paper proposes a variant of the SV amenable to FL, which we call the federated Shapley value. The federated SV preserves the desirable properties of the canonical SV while it can be calculated without incurring extra communication cost and is also able to capture the effect of participation order on data value. We conduct a thorough empirical study of the federated SV on a range of tasks, including noisy label detection, adversarial participant detection, and data summarization on different benchmark datasets, and demonstrate that it can reflect the real utility of data sources for FL and has the potential to enhance system robustness, security, and efficiency. We also report and analyze "failure cases" and hope to stimulate future research.
APMSqueeze: A Communication Efficient Adam-Preconditioned Momentum SGD Algorithm
Aug 28, 2020
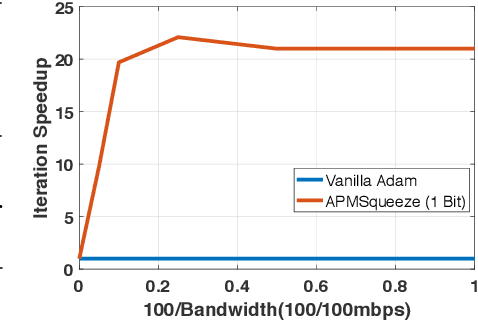
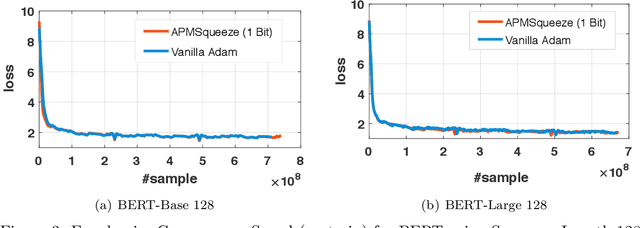
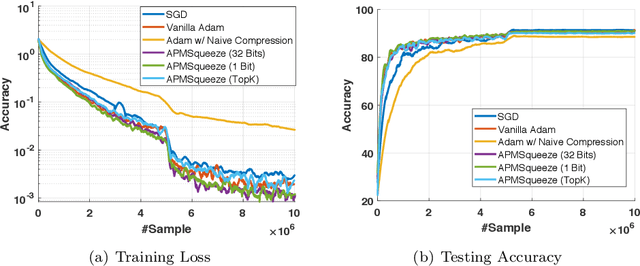
Adam is the important optimization algorithm to guarantee efficiency and accuracy for training many important tasks such as BERT and ImageNet. However, Adam is generally not compatible with information (gradient) compression technology. Therefore, the communication usually becomes the bottleneck for parallelizing Adam. In this paper, we propose a communication efficient {\bf A}DAM {\bf p}reconditioned {\bf M}omentum SGD algorithm-- named APMSqueeze-- through an error compensated method compressing gradients. The proposed algorithm achieves a similar convergence efficiency to Adam in term of epochs, but significantly reduces the running time per epoch. In terms of end-to-end performance (including the full-precision pre-condition step), APMSqueeze is able to provide {sometimes by up to $2-10\times$ speed-up depending on network bandwidth.} We also conduct theoretical analysis on the convergence and efficiency.