 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Sampling with Primal-Dual Langevin Monte Carlo
Nov 01, 2024This work considers the problem of sampling from a probability distribution known up to a normalization constant while satisfying a set of statistical constraints specified by the expected values of general nonlinear functions. This problem finds applications in, e.g., Bayesian inference, where it can constrain moments to evaluate counterfactual scenarios or enforce desiderata such as prediction fairness. Methods developed to handle support constraints, such as those based on mirror maps, barriers, and penalties, are not suited for this task. This work therefore relies on gradient descent-ascent dynamics in Wasserstein space to put forward a discrete-time primal-dual Langevin Monte Carlo algorithm (PD-LMC) that simultaneously constrains the target distribution and samples from it. We analyze the convergence of PD-LMC under standard assumptions on the target distribution and constraints, namely (strong) convexity and log-Sobolev inequalities. To do so, we bring classical optimization arguments for saddle-point algorithms to the geometry of Wasserstein space. We illustrate the relevance and effectiveness of PD-LMC in several applications.
Sinkhorn Flow: A Continuous-Time Framework for Understanding and Generalizing the Sinkhorn Algorithm
Nov 28, 2023Many problems in machine learning can be formulated as solving entropy-regularized optimal transport on the space of probability measures. The canonical approach involves the Sinkhorn iterates, renowned for their rich mathematical properties. Recently, the Sinkhorn algorithm has been recast within the mirror descent framework, thus benefiting from classical optimization theory insights. Here, we build upon this result by introducing a continuous-time analogue of the Sinkhorn algorithm. This perspective allows us to derive novel variants of Sinkhorn schemes that are robust to noise and bias. Moreover, our continuous-time dynamics not only generalize but also offer a unified perspective on several recently discovered dynamics in machine learning and mathematics, such as the "Wasserstein mirror flow" of (Deb et al. 2023) or the "mean-field Schr\"odinger equation" of (Claisse et al. 2023).
Riemannian stochastic optimization methods avoid strict saddle points
Nov 04, 2023

Many modern machine learning applications - from online principal component analysis to covariance matrix identification and dictionary learning - can be formulated as minimization problems on Riemannian manifolds, and are typically solved with a Riemannian stochastic gradient method (or some variant thereof). However, in many cases of interest, the resulting minimization problem is not geodesically convex, so the convergence of the chosen solver to a desirable solution - i.e., a local minimizer - is by no means guaranteed. In this paper, we study precisely this question, that is, whether stochastic Riemannian optimization algorithms are guaranteed to avoid saddle points with probability 1. For generality, we study a family of retraction-based methods which, in addition to having a potentially much lower per-iteration cost relative to Riemannian gradient descent, include other widely used algorithms, such as natural policy gradient methods and mirror descent in ordinary convex spaces. In this general setting, we show that, under mild assumptions for the ambient manifold and the oracle providing gradient information, the policies under study avoid strict saddle points / submanifolds with probability 1, from any initial condition. This result provides an important sanity check for the use of gradient methods on manifolds as it shows that, almost always, the limit state of a stochastic Riemannian algorithm can only be a local minimizer.
Isotropic Gaussian Processes on Finite Spaces of Graphs
Nov 03, 2022



We propose a principled way to define Gaussian process priors on various sets of unweighted graphs: directed or undirected, with or without loops. We endow each of these sets with a geometric structure, inducing the notions of closeness and symmetries, by turning them into a vertex set of an appropriate metagraph. Building on this, we describe the class of priors that respect this structure and are analogous to the Euclidean isotropic processes, like squared exponential or Mat\'ern. We propose an efficient computational technique for the ostensibly intractable problem of evaluating these priors' kernels, making such Gaussian processes usable within the usual toolboxes and downstream applications. We go further to consider sets of equivalence classes of unweighted graphs and define the appropriate versions of priors thereon. We prove a hardness result, showing that in this case, exact kernel computation cannot be performed efficiently. However, we propose a simple Monte Carlo approximation for handling moderately sized cases. Inspired by applications in chemistry, we illustrate the proposed techniques on a real molecular property prediction task in the small data regime.
A Dynamical System View of Langevin-Based Non-Convex Sampling
Oct 25, 2022

Non-convex sampling is a key challenge in machine learning, central to non-convex optimization in deep learning as well as to approximate probabilistic inference. Despite its significance, theoretically there remain many important challenges: Existing guarantees (1) typically only hold for the averaged iterates rather than the more desirable last iterates, (2) lack convergence metrics that capture the scales of the variables such as Wasserstein distances, and (3) mainly apply to elementary schemes such as stochastic gradient Langevin dynamics. In this paper, we develop a new framework that lifts the above issues by harnessing several tools from the theory of dynamical systems. Our key result is that, for a large class of state-of-the-art sampling schemes, their last-iterate convergence in Wasserstein distances can be reduced to the study of their continuous-time counterparts, which is much better understood. Coupled with standard assumptions of MCMC sampling, our theory immediately yields the last-iterate Wasserstein convergence of many advanced sampling schemes such as proximal, randomized mid-point, and Runge-Kutta integrators. Beyond existing methods, our framework also motivates more efficient schemes that enjoy the same rigorous guarantees.
The Dynamics of Riemannian Robbins-Monro Algorithms
Jun 16, 2022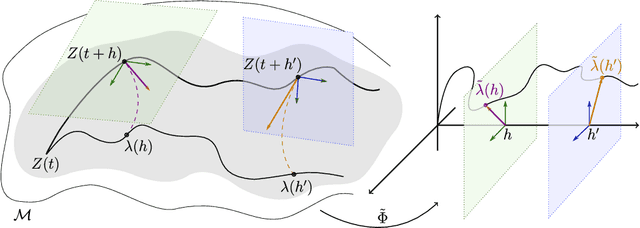
Many important learning algorithms, such as stochastic gradient methods, are often deployed to solve nonlinear problems on Riemannian manifolds. Motivated by these applications, we propose a family of Riemannian algorithms generalizing and extending the seminal stochastic approximation framework of Robbins and Monro. Compared to their Euclidean counterparts, Riemannian iterative algorithms are much less understood due to the lack of a global linear structure on the manifold. We overcome this difficulty by introducing an extended Fermi coordinate frame which allows us to map the asymptotic behavior of the proposed Riemannian Robbins-Monro (RRM) class of algorithms to that of an associated deterministic dynamical system under very mild assumptions on the underlying manifold. In so doing, we provide a general template of almost sure convergence results that mirrors and extends the existing theory for Euclidean Robbins-Monro schemes, albeit with a significantly more involved analysis that requires a number of new geometric ingredients. We showcase the flexibility of the proposed RRM framework by using it to establish the convergence of a retraction-based analogue of the popular optimistic / extra-gradient methods for solving minimization problems and games, and we provide a unified treatment for their convergence.
Online Active Model Selection for Pre-trained Classifiers
Oct 21, 2020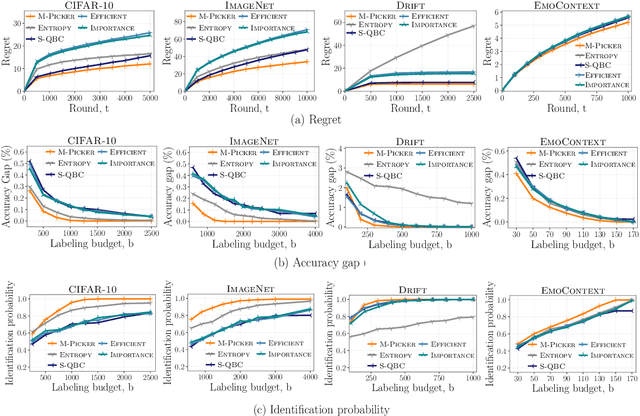

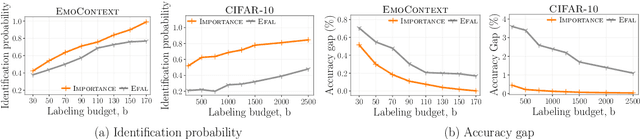
Given $k$ pre-trained classifiers and a stream of unlabeled data examples, how can we actively decide when to query a label so that we can distinguish the best model from the rest while making a small number of queries? Answering this question has a profound impact on a range of practical scenarios. In this work, we design an online selective sampling approach that actively selects informative examples to label and outputs the best model with high probability at any round. Our algorithm can be used for online prediction tasks for both adversarial and stochastic streams. We establish several theoretical guarantees for our algorithm and extensively demonstrate its effectiveness in our experimental studies.
Stochastic Submodular Maximization: The Case of Coverage Functions
Nov 05, 2017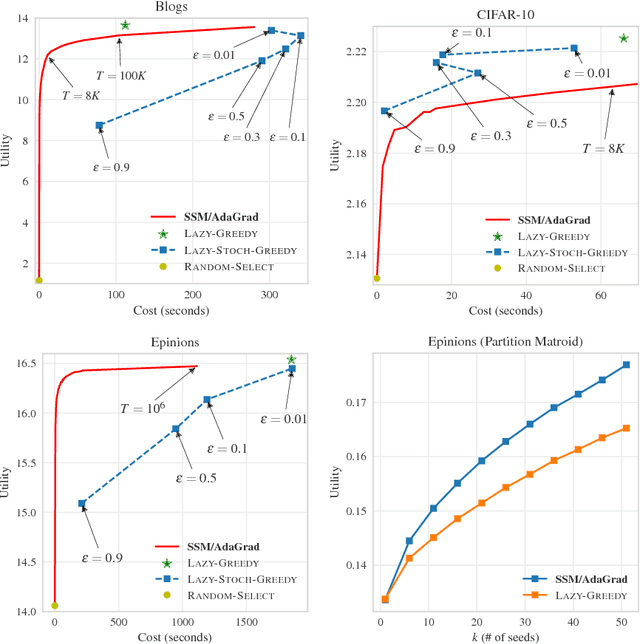
Stochastic optimization of continuous objectives is at the heart of modern machine learning. However, many important problems are of discrete nature and often involve submodular objectives. We seek to unleash the power of stochastic continuous optimization, namely stochastic gradient descent and its variants, to such discrete problems. We first introduce the problem of stochastic submodular optimization, where one needs to optimize a submodular objective which is given as an expectation. Our model captures situations where the discrete objective arises as an empirical risk (e.g., in the case of exemplar-based clustering), or is given as an explicit stochastic model (e.g., in the case of influence maximization in social networks). By exploiting that common extensions act linearly on the class of submodular functions, we employ projected stochastic gradient ascent and its variants in the continuous domain, and perform rounding to obtain discrete solutions. We focus on the rich and widely used family of weighted coverage functions. We show that our approach yields solutions that are guaranteed to match the optimal approximation guarantees, while reducing the computational cost by several orders of magnitude, as we demonstrate empirically.
Smart broadcasting: Do you want to be seen?
May 22, 2016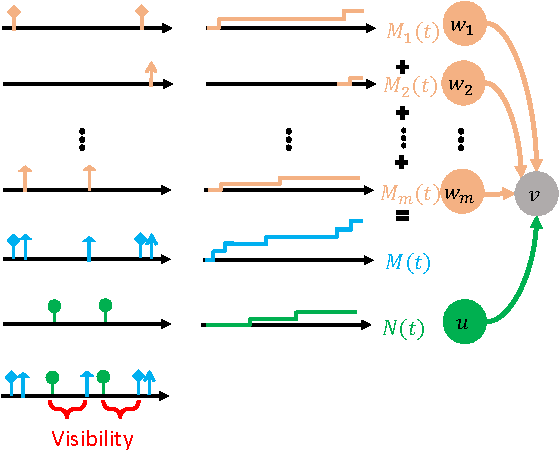
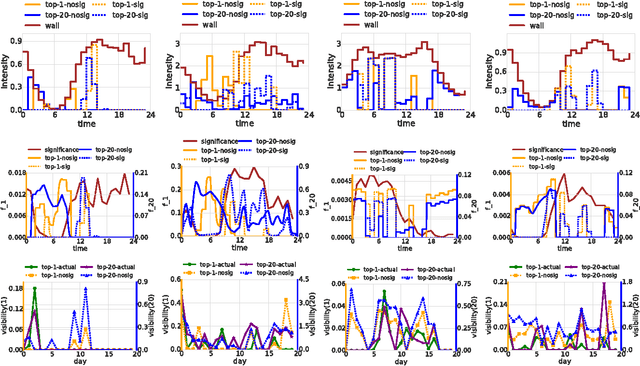
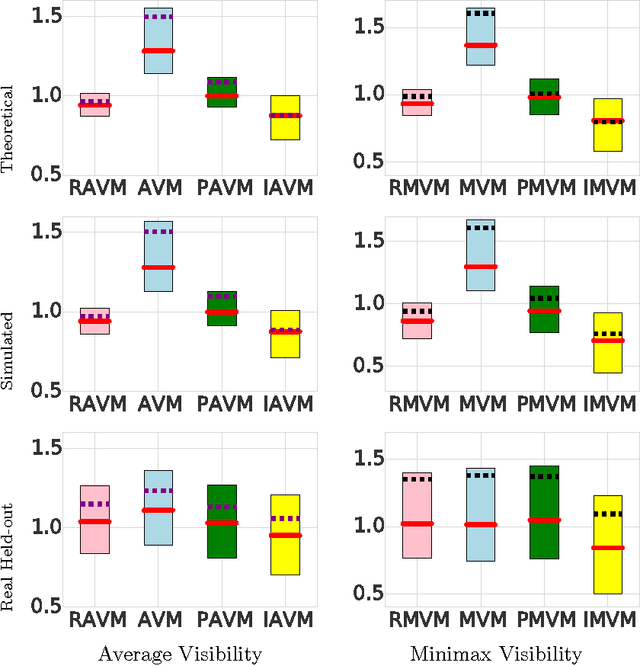
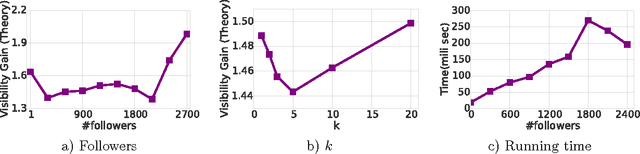
Many users in online social networks are constantly trying to gain attention from their followers by broadcasting posts to them. These broadcasters are likely to gain greater attention if their posts can remain visible for a longer period of time among their followers' most recent feeds. Then when to post? In this paper, we study the problem of smart broadcasting using the framework of temporal point processes, where we model users feeds and posts as discrete events occurring in continuous time. Based on such continuous-time model, then choosing a broadcasting strategy for a user becomes a problem of designing the conditional intensity of her posting events. We derive a novel formula which links this conditional intensity with the visibility of the user in her followers' feeds. Furthermore, by exploiting this formula, we develop an efficient convex optimization framework for the when-to-post problem. Our method can find broadcasting strategies that reach a desired visibility level with provable guarantees. We experimented with data gathered from Twitter, and show that our framework can consistently make broadcasters' post more visible than alternatives.