 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDLxGraph: Bridging Large Language Models and HDL Repositories via HDL Graph Databases
May 21, 2025Large Language Models (LLMs) have demonstrated their potential in hardware design tasks, such as Hardware Description Language (HDL) generation and debugging. Yet, their performance in real-world, repository-level HDL projects with thousands or even tens of thousands of code lines is hindered. To this end, we propose HDLxGraph, a novel framework that integrates Graph Retrieval Augmented Generation (Graph RAG) with LLMs, introducing HDL-specific graph representations by incorporating Abstract Syntax Trees (ASTs) and Data Flow Graphs (DFGs) to capture both code graph view and hardware graph view. HDLxGraph utilizes a dual-retrieval mechanism that not only mitigates the limited recall issues inherent in similarity-based semantic retrieval by incorporating structural information, but also enhances its extensibility to various real-world tasks by a task-specific retrieval finetuning. Additionally, to address the lack of comprehensive HDL search benchmarks, we introduce HDLSearch, a multi-granularity evaluation dataset derived from real-world repository-level projects. Experimental results demonstrate that HDLxGraph significantly improves average search accuracy, debugging efficiency and completion quality by 12.04%, 12.22% and 5.04% compared to similarity-based RAG, respectively. The code of HDLxGraph and collected HDLSearch benchmark are available at https://github.com/Nick-Zheng-Q/HDLxGraph.
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025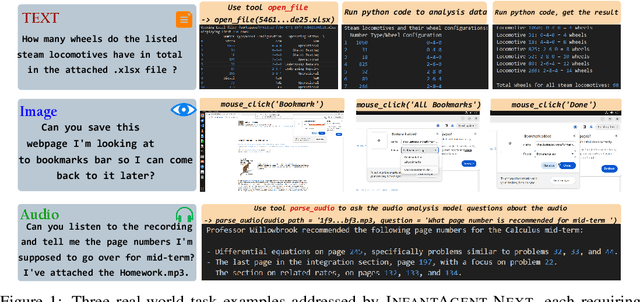

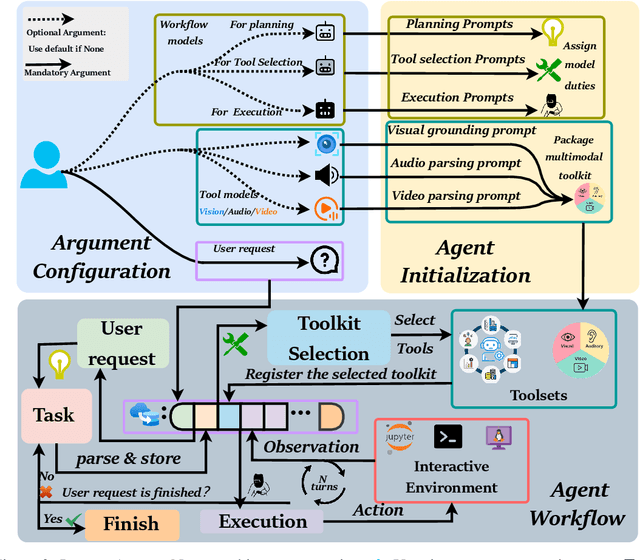
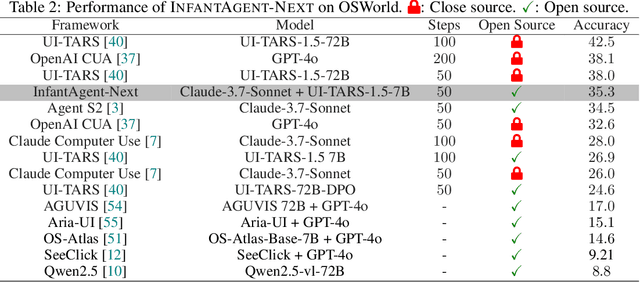
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
RankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025



In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
Fortran2CPP: Automating Fortran-to-C++ Migration using LLMs via Multi-Turn Dialogue and Dual-Agent Integration
Dec 27, 2024



Migrating Fortran code to C++ is a common task for many scientific computing teams, driven by the need to leverage modern programming paradigms, enhance cross-platform compatibility, and improve maintainability. Automating this translation process using large language models (LLMs) has shown promise, but the lack of high-quality, specialized datasets has hindered their effectiveness. In this paper, we address this challenge by introducing a novel multi-turn dialogue dataset, Fortran2CPP, specifically designed for Fortran-to-C++ code migration. Our dataset, significantly larger than existing alternatives, is generated using a unique LLM-driven, dual-agent pipeline incorporating iterative compilation, execution, and code repair to ensure high quality and functional correctness. To demonstrate the effectiveness of our dataset, we fine-tuned several open-weight LLMs on Fortran2CPP and evaluated their performance on two independent benchmarks. Fine-tuning on our dataset led to remarkable gains, with models achieving up to a 3.31x increase in CodeBLEU score and a 92\% improvement in compilation success rate. This highlights the dataset's ability to enhance both the syntactic accuracy and compilability of the translated C++ code. Our dataset and model have been open-sourced and are available on our public GitHub repository\footnote{\url{https://github.com/HPC-Fortran2CPP/Fortran2Cpp}}.
HiVeGen -- Hierarchical LLM-based Verilog Generation for Scalable Chip Design
Dec 06, 2024



With Large Language Models (LLMs) recently demonstrating impressive proficiency in code generation, it is promising to extend their abilities to Hardware Description Language (HDL). However, LLMs tend to generate single HDL code blocks rather than hierarchical structures for hardware designs, leading to hallucinations, particularly in complex designs like Domain-Specific Accelerators (DSAs). To address this, we propose HiVeGen, a hierarchical LLM-based Verilog generation framework that decomposes generation tasks into LLM-manageable hierarchical submodules. HiVeGen further harnesses the advantages of such hierarchical structures by integrating automatic Design Space Exploration (DSE) into hierarchy-aware prompt generation, introducing weight-based retrieval to enhance code reuse, and enabling real-time human-computer interaction to lower error-correction cost, significantly improving the quality of generated designs.
Theoretical Corrections and the Leveraging of Reinforcement Learning to Enhance Triangle Attack
Nov 18, 2024



Adversarial examples represent a serious issue for the application of machine learning models in many sensitive domains. For generating adversarial examples, decision based black-box attacks are one of the most practical techniques as they only require query access to the model. One of the most recently proposed state-of-the-art decision based black-box attacks is Triangle Attack (TA). In this paper, we offer a high-level description of TA and explain potential theoretical limitations. We then propose a new decision based black-box attack, Triangle Attack with Reinforcement Learning (TARL). Our new attack addresses the limits of TA by leveraging reinforcement learning. This creates an attack that can achieve similar, if not better, attack accuracy than TA with half as many queries on state-of-the-art classifiers and defenses across ImageNet and CIFAR-10.
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Jul 25, 2024



Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
AdaPI: Facilitating DNN Model Adaptivity for Efficient Private Inference in Edge Computing
Jul 08, 2024



Private inference (PI) has emerged as a promising solution to execute computations on encrypted data, safeguarding user privacy and model parameters in edge computing. However, existing PI methods are predominantly developed considering constant resource constraints, overlooking the varied and dynamic resource constraints in diverse edge devices, like energy budgets. Consequently, model providers have to design specialized models for different devices, where all of them have to be stored on the edge server, resulting in inefficient deployment. To fill this gap, this work presents AdaPI, a novel approach that achieves adaptive PI by allowing a model to perform well across edge devices with diverse energy budgets. AdaPI employs a PI-aware training strategy that optimizes the model weights alongside weight-level and feature-level soft masks. These soft masks are subsequently transformed into multiple binary masks to enable adjustments in communication and computation workloads. Through sequentially training the model with increasingly dense binary masks, AdaPI attains optimal accuracy for each energy budget, which outperforms the state-of-the-art PI methods by 7.3\% in terms of test accuracy on CIFAR-100. The code of AdaPI can be accessed via https://github.com/jiahuiiiiii/AdaPI.
SSNet: A Lightweight Multi-Party Computation Scheme for Practical Privacy-Preserving Machine Learning Service in the Cloud
Jun 04, 2024



As privacy-preserving becomes a pivotal aspect of deep learning (DL) development, multi-party computation (MPC) has gained prominence for its efficiency and strong security. However, the practice of current MPC frameworks is limited, especially when dealing with large neural networks, exemplified by the prolonged execution time of 25.8 seconds for secure inference on ResNet-152. The primary challenge lies in the reliance of current MPC approaches on additive secret sharing, which incurs significant communication overhead with non-linear operations such as comparisons. Furthermore, additive sharing suffers from poor scalability on party size. In contrast, the evolving landscape of MPC necessitates accommodating a larger number of compute parties and ensuring robust performance against malicious activities or computational failures. In light of these challenges, we propose SSNet, which for the first time, employs Shamir's secret sharing (SSS) as the backbone of MPC-based ML framework. We meticulously develop all framework primitives and operations for secure DL models tailored to seamlessly integrate with the SSS scheme. SSNet demonstrates the ability to scale up party numbers straightforwardly and embeds strategies to authenticate the computation correctness without incurring significant performance overhead. Additionally, SSNet introduces masking strategies designed to reduce communication overhead associated with non-linear operations. We conduct comprehensive experimental evaluations on commercial cloud computing infrastructure from Amazon AWS, as well as across diverse prevalent DNN models and datasets. SSNet demonstrates a substantial performance boost, achieving speed-ups ranging from 3x to 14x compared to SOTA MPC frameworks. Moreover, SSNet also represents the first framework that is evaluated on a five-party computation setup, in the context of secure DL inference.
Weakly Supervised Change Detection via Knowledge Distillation and Multiscale Sigmoid Inference
Mar 09, 2024Change detection, which aims to detect spatial changes from a pair of multi-temporal images due to natural or man-made causes, has been widely applied in remote sensing, disaster management, urban management, etc. Most existing change detection approaches, however, are fully supervised and require labor-intensive pixel-level labels. To address this, we develop a novel weakly supervised change detection technique via Knowledge Distillation and Multiscale Sigmoid Inference (KD-MSI) that leverages image-level labels. In our approach, the Class Activation Maps (CAM) are utilized not only to derive a change probability map but also to serve as a foundation for the knowledge distillation process. This is done through a joint training strategy of the teacher and student networks, enabling the student network to highlight potential change areas more accurately than teacher network based on image-level labels. Moreover, we designed a Multiscale Sigmoid Inference (MSI) module as a post processing step to further refine the change probability map from the trained student network. Empirical results on three public datasets, i.e., WHU-CD, DSIFN-CD, and LEVIR-CD, demonstrate that our proposed technique, with its integrated training strategy, significantly outperforms the state-of-the-art.