 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Progressive Distillation: Resolving Overfitting under Pretrain-and-Finetune Paradigm
Oct 18, 2021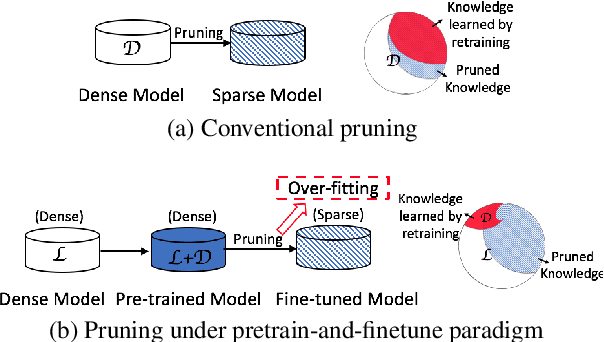
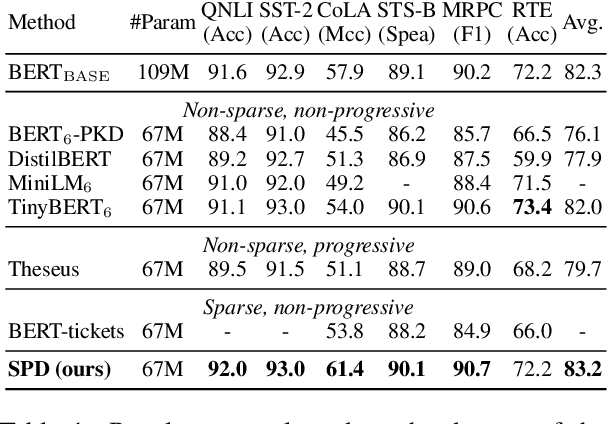
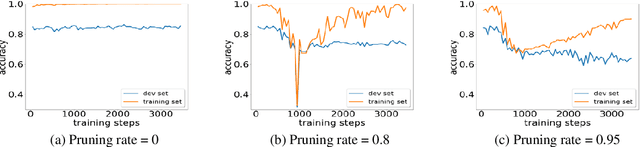
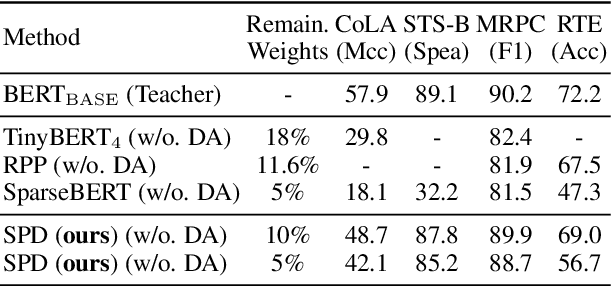
Various pruning approaches have been proposed to reduce the footprint requirements of Transformer-based language models. Conventional wisdom is that pruning reduces the model expressiveness and thus is more likely to underfit than overfit compared to the original model. However, under the trending pretrain-and-finetune paradigm, we argue that pruning increases the risk of overfitting if pruning was performed at the fine-tuning phase, as it increases the amount of information a model needs to learn from the downstream task, resulting in relative data deficiency. In this paper, we aim to address the overfitting issue under the pretrain-and-finetune paradigm to improve pruning performance via progressive knowledge distillation (KD) and sparse pruning. Furthermore, to mitigate the interference between different strategies of learning rate, pruning and distillation, we propose a three-stage learning framework. We show for the first time that reducing the risk of overfitting can help the effectiveness of pruning under the pretrain-and-finetune paradigm. Experiments on multiple datasets of GLUE benchmark show that our method achieves highly competitive pruning performance over the state-of-the-art competitors across different pruning ratio constraints.
Detecting Gender Bias in Transformer-based Models: A Case Study on BERT
Oct 15, 2021
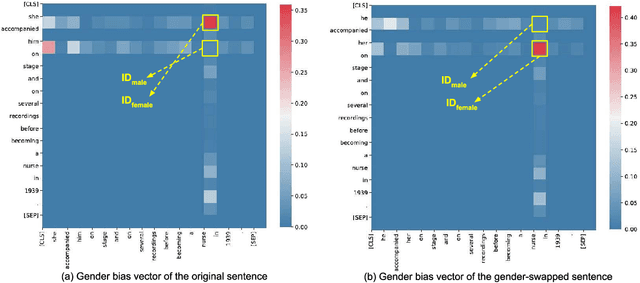
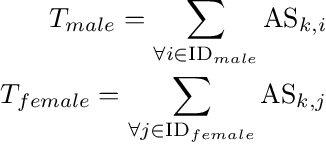
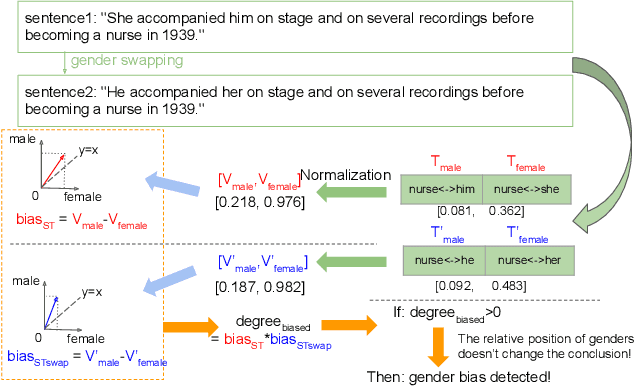
In this paper, we propose a novel gender bias detection method by utilizing attention map for transformer-based models. We 1) give an intuitive gender bias judgement method by comparing the different relation degree between the genders and the occupation according to the attention scores, 2) design a gender bias detector by modifying the attention module, 3) insert the gender bias detector into different positions of the model to present the internal gender bias flow, and 4) draw the consistent gender bias conclusion by scanning the entire Wikipedia, a BERT pretraining dataset. We observe that 1) the attention matrices, Wq and Wk introduce much more gender bias than other modules (including the embedding layer) and 2) the bias degree changes periodically inside of the model (attention matrix Q, K, V, and the remaining part of the attention layer (including the fully-connected layer, the residual connection, and the layer normalization module) enhance the gender bias while the averaged attentions reduces the bias).
Dr. Top-k: Delegate-Centric Top-k on GPUs
Sep 16, 2021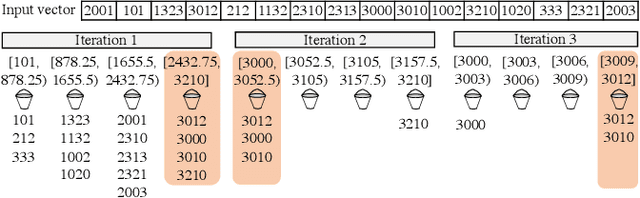
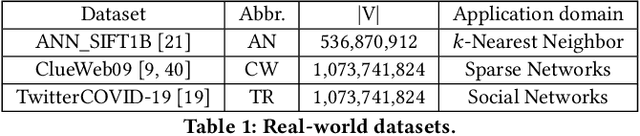


Recent top-$k$ computation efforts explore the possibility of revising various sorting algorithms to answer top-$k$ queries on GPUs. These endeavors, unfortunately, perform significantly more work than needed. This paper introduces Dr. Top-k, a Delegate-centric top-$k$ system on GPUs that can reduce the top-$k$ workloads significantly. Particularly, it contains three major contributions: First, we introduce a comprehensive design of the delegate-centric concept, including maximum delegate, delegate-based filtering, and $\beta$ delegate mechanisms to help reduce the workload for top-$k$ up to more than 99%. Second, due to the difficulty and importance of deriving a proper subrange size, we perform a rigorous theoretical analysis, coupled with thorough experimental validations to identify the desirable subrange size. Third, we introduce four key system optimizations to enable fast multi-GPU top-$k$ computation. Taken together, this work constantly outperforms the state-of-the-art.
Exploration of Quantum Neural Architecture by Mixing Quantum Neuron Designs
Sep 08, 2021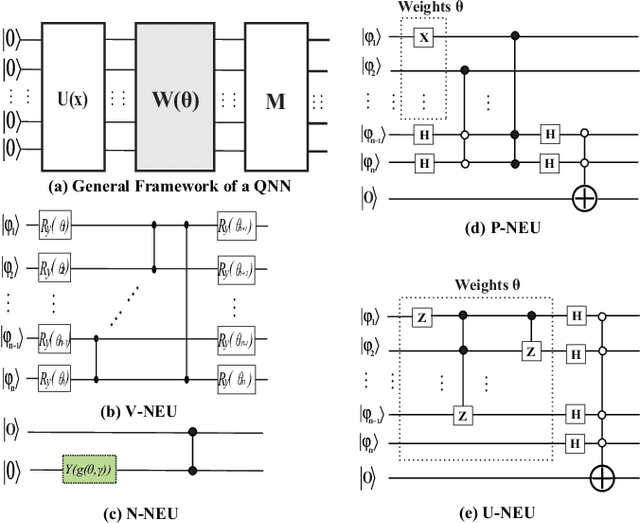

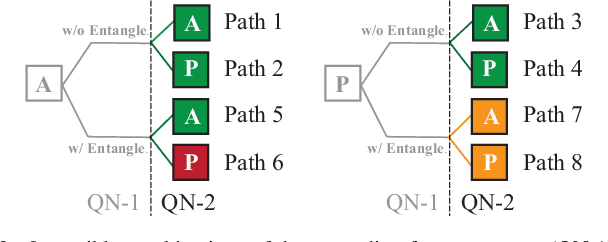
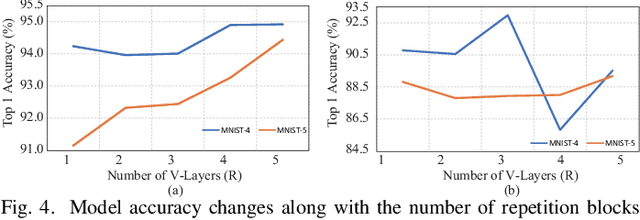
With the constant increase of the number of quantum bits (qubits) in the actual quantum computers, implementing and accelerating the prevalent deep learning on quantum computers are becoming possible. Along with this trend, there emerge quantum neural architectures based on different designs of quantum neurons. A fundamental question in quantum deep learning arises: what is the best quantum neural architecture? Inspired by the design of neural architectures for classical computing which typically employs multiple types of neurons, this paper makes the very first attempt to mix quantum neuron designs to build quantum neural architectures. We observe that the existing quantum neuron designs may be quite different but complementary, such as neurons from variation quantum circuits (VQC) and Quantumflow. More specifically, VQC can apply real-valued weights but suffer from being extended to multiple layers, while QuantumFlow can build a multi-layer network efficiently, but is limited to use binary weights. To take their respective advantages, we propose to mix them together and figure out a way to connect them seamlessly without additional costly measurement. We further investigate the design principles to mix quantum neurons, which can provide guidance for quantum neural architecture exploration in the future. Experimental results demonstrate that the identified quantum neural architectures with mixed quantum neurons can achieve 90.62% of accuracy on the MNIST dataset, compared with 52.77% and 69.92% on the VQC and QuantumFlow, respectively.
Binary Complex Neural Network Acceleration on FPGA
Aug 10, 2021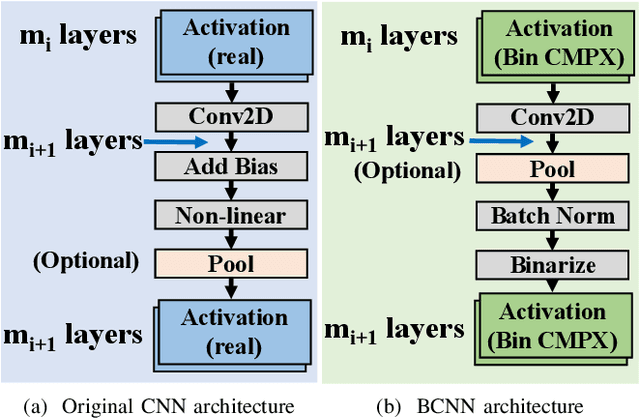
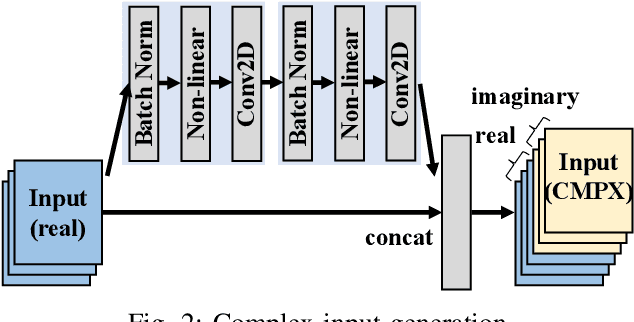

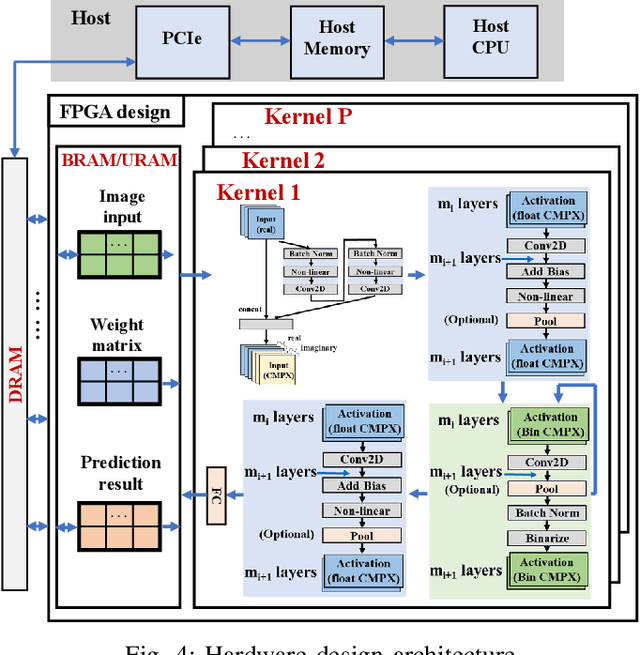
Being able to learn from complex data with phase information is imperative for many signal processing applications. Today' s real-valued deep neural networks (DNNs) have shown efficiency in latent information analysis but fall short when applied to the complex domain. Deep complex networks (DCN), in contrast, can learn from complex data, but have high computational costs; therefore, they cannot satisfy the instant decision-making requirements of many deployable systems dealing with short observations or short signal bursts. Recent, Binarized Complex Neural Network (BCNN), which integrates DCNs with binarized neural networks (BNN), shows great potential in classifying complex data in real-time. In this paper, we propose a structural pruning based accelerator of BCNN, which is able to provide more than 5000 frames/s inference throughput on edge devices. The high performance comes from both the algorithm and hardware sides. On the algorithm side, we conduct structural pruning to the original BCNN models and obtain 20 $\times$ pruning rates with negligible accuracy loss; on the hardware side, we propose a novel 2D convolution operation accelerator for the binary complex neural network. Experimental results show that the proposed design works with over 90% utilization and is able to achieve the inference throughput of 5882 frames/s and 4938 frames/s for complex NIN-Net and ResNet-18 using CIFAR-10 dataset and Alveo U280 Board.
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021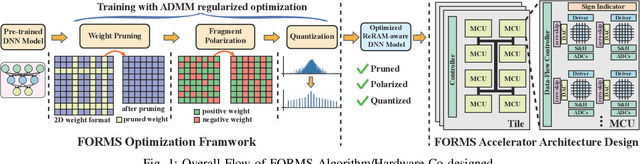
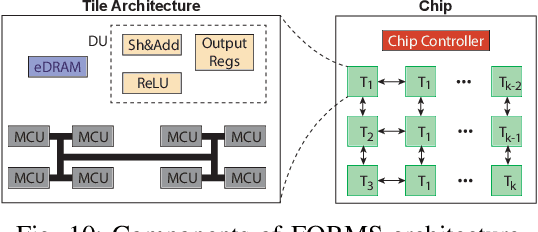
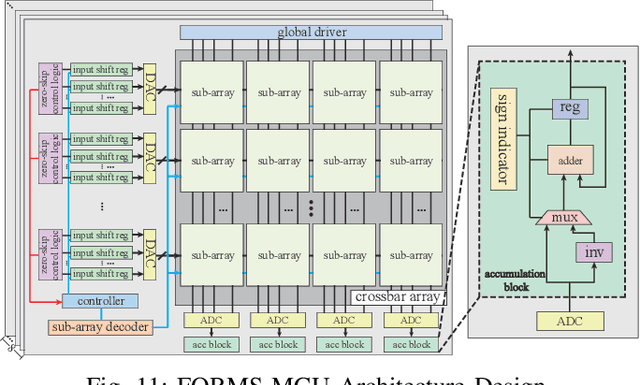

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.
A Compression-Compilation Framework for On-mobile Real-time BERT Applications
Jun 06, 2021


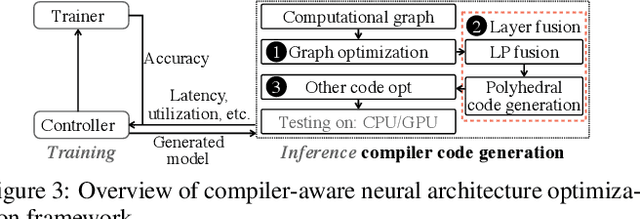
Transformer-based deep learning models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. In this paper, we propose a compression-compilation co-design framework that can guarantee the identified model to meet both resource and real-time specifications of mobile devices. Our framework applies a compiler-aware neural architecture optimization method (CANAO), which can generate the optimal compressed model that balances both accuracy and latency. We are able to achieve up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss. We present two types of BERT applications on mobile devices: Question Answering (QA) and Text Generation. Both can be executed in real-time with latency as low as 45ms. Videos for demonstrating the framework can be found on https://www.youtube.com/watch?v=_WIRvK_2PZI
Dancing along Battery: Enabling Transformer with Run-time Reconfigurability on Mobile Devices
Feb 12, 2021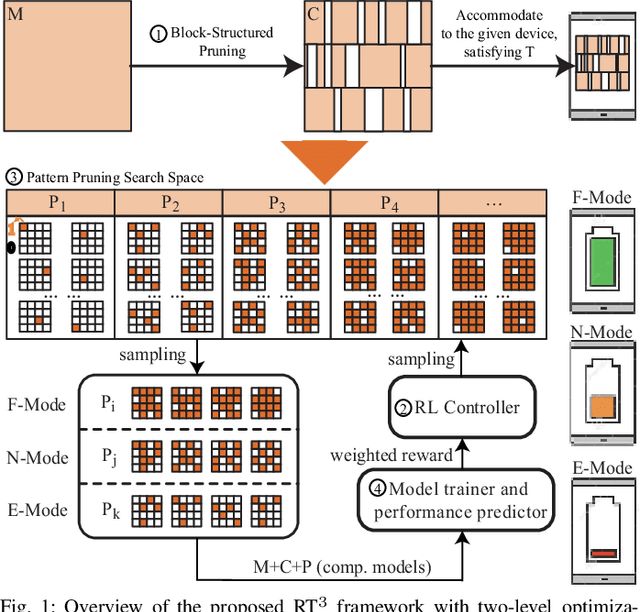
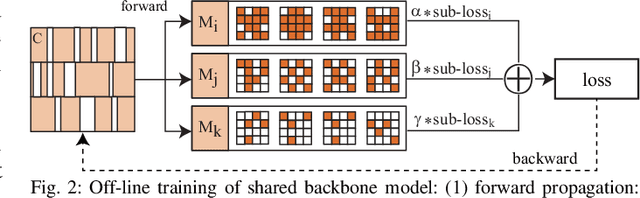
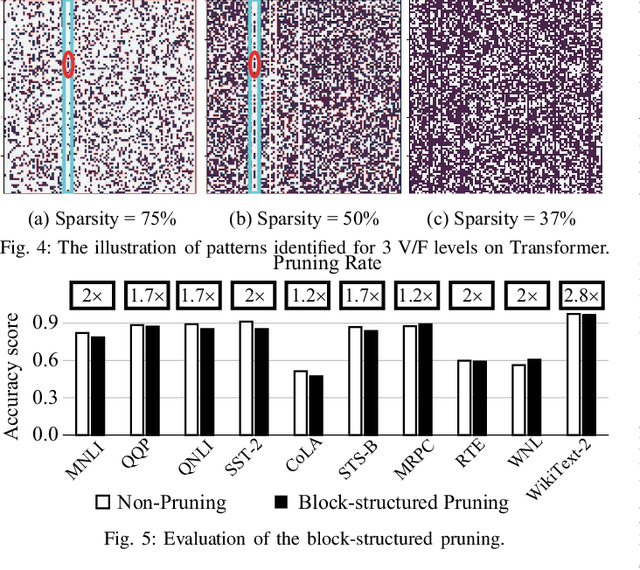

A pruning-based AutoML framework for run-time reconfigurability, namely RT3, is proposed in this work. This enables Transformer-based large Natural Language Processing (NLP) models to be efficiently executed on resource-constrained mobile devices and reconfigured (i.e., switching models for dynamic hardware conditions) at run-time. Such reconfigurability is the key to save energy for battery-powered mobile devices, which widely use dynamic voltage and frequency scaling (DVFS) technique for hardware reconfiguration to prolong battery life. In this work, we creatively explore a hybrid block-structured pruning (BP) and pattern pruning (PP) for Transformer-based models and first attempt to combine hardware and software reconfiguration to maximally save energy for battery-powered mobile devices. Specifically, RT3 integrates two-level optimizations: First, it utilizes an efficient BP as the first-step compression for resource-constrained mobile devices; then, RT3 heuristically generates a shrunken search space based on the first level optimization and searches multiple pattern sets with diverse sparsity for PP via reinforcement learning to support lightweight software reconfiguration, which corresponds to available frequency levels of DVFS (i.e., hardware reconfiguration). At run-time, RT3 can switch the lightweight pattern sets within 45ms to guarantee the required real-time constraint at different frequency levels. Results further show that RT3 can prolong battery life over 4x improvement with less than 1% accuracy loss for Transformer and 1.5% score decrease for DistilBERT.
A Surrogate Lagrangian Relaxation-based Model Compression for Deep Neural Networks
Dec 18, 2020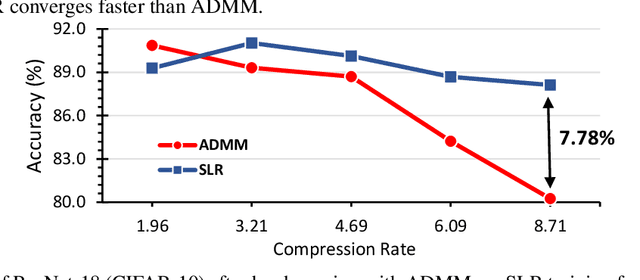
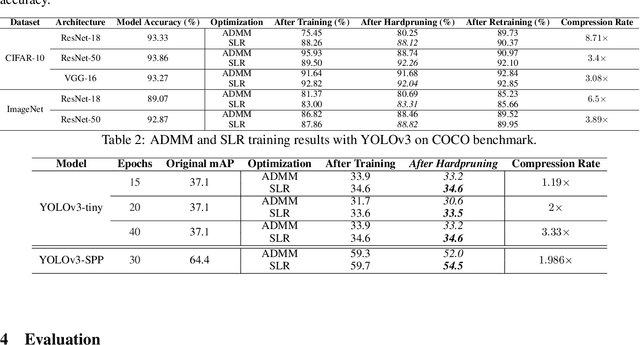
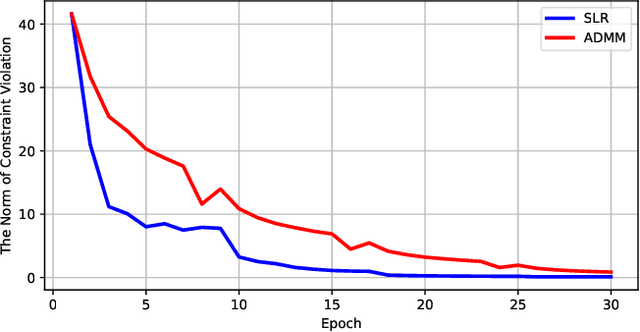
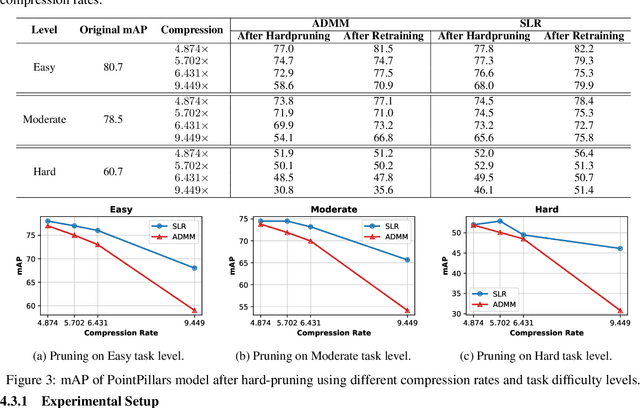
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline, i.e., training, pruning and retraining (fine-tuning) significantly increases the overall training trails. For instance, the retraining process could take up to 80 epochs for ResNet-18 on ImageNet, that is 70% of the original model training trails. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation (SLR), which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem while ensuring fast convergence. We decompose the weight-pruning problem into subproblems, which are coordinated by updating Lagrangian multipliers. Convergence is then accelerated by using quadratic penalty terms. We evaluate the proposed method on image classification tasks, i.e., ResNet-18, ResNet-50 and VGG-16 using ImageNet and CIFAR-10, as well as object detection tasks, i.e., YOLOv3 and YOLOv3-tiny using COCO 2014, PointPillars using KITTI 2017, and Ultra-Fast-Lane-Detection using TuSimple lane detection dataset. Numerical testing results demonstrate that with the adoption of the Surrogate Lagrangian Relaxation method, our SLR-based weight-pruning optimization approach achieves a high model accuracy even at the hard-pruning stage without retraining for many epochs, such as on PointPillars object detection model on KITTI dataset where we achieve 9.44x compression rate by only retraining for 3 epochs with less than 1% accuracy loss. As the compression rate increases, SLR starts to perform better than ADMM and the accuracy gap between them increases. SLR achieves 15.2% better accuracy than ADMM on PointPillars after pruning under 9.49x compression. Given a limited budget of retraining epochs, our approach quickly recovers the model accuracy.
Efficient Transformer-based Large Scale Language Representations using Hardware-friendly Block Structured Pruning
Oct 08, 2020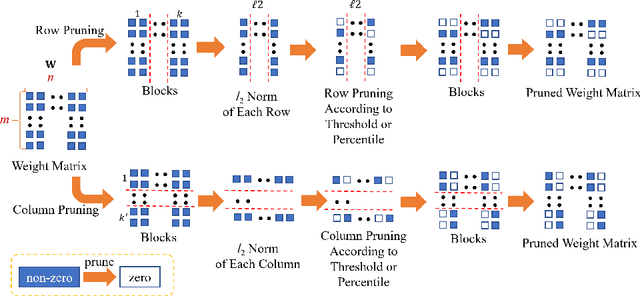
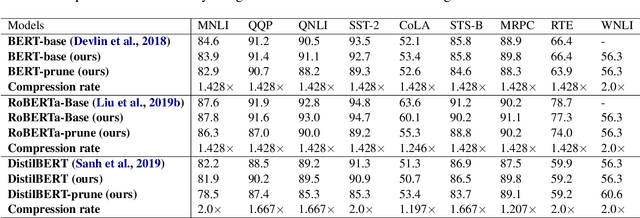
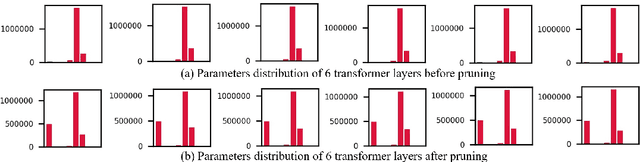
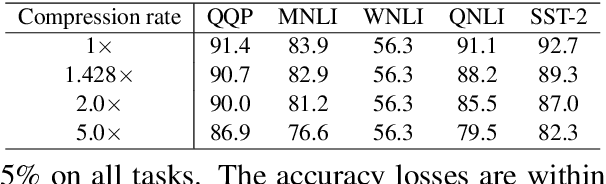
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this work, we propose an efficient transformer-based large-scale language representation using hardware-friendly block structure pruning. We incorporate the reweighted group Lasso into block-structured pruning for optimization. Besides the significantly reduced weight storage and computation, the proposed approach achieves high compression rates. Experimental results on different models (BERT, RoBERTa, and DistilBERT) on the General Language Understanding Evaluation (GLUE) benchmark tasks show that we achieve up to 5.0x with zero or minor accuracy degradation on certain task(s). Our proposed method is also orthogonal to existing compact pre-trained language models such as DistilBERT using knowledge distillation, since a further 1.79x average compression rate can be achieved on top of DistilBERT with zero or minor accuracy degradation. It is suitable to deploy the final compressed model on resource-constrained edge devices.