 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStein Variational Model Predictive Control
Dec 09, 2020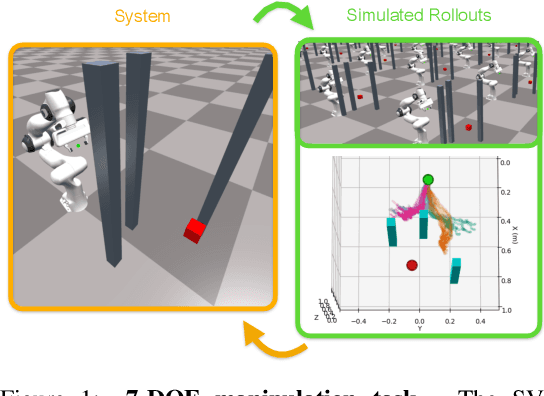

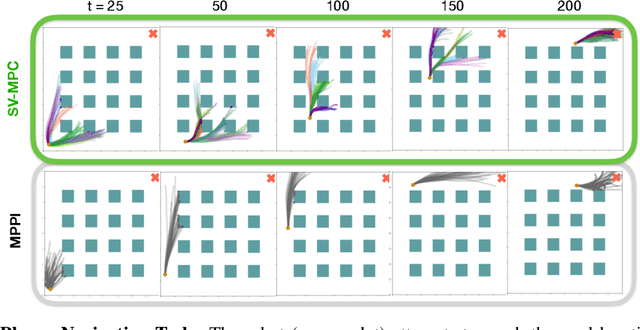
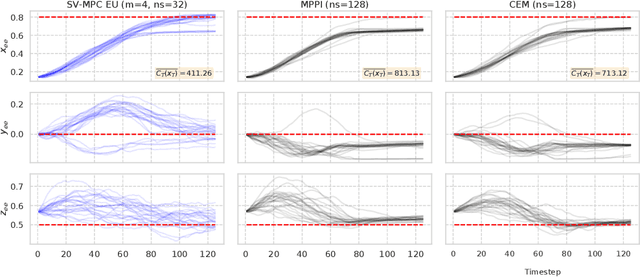
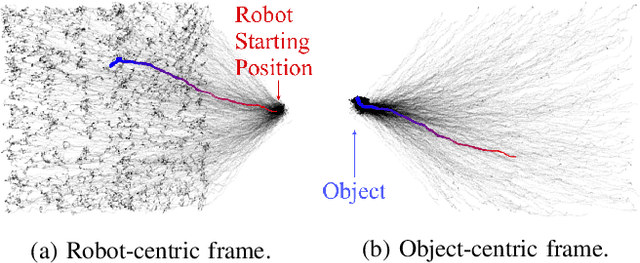
Decision making under uncertainty is critical to real-world, autonomous systems. Model Predictive Control (MPC) methods have demonstrated favorable performance in practice, but remain limited when dealing with complex probability distributions. In this paper, we propose a generalization of MPC that represents a multitude of solutions as posterior distributions. By casting MPC as a Bayesian inference problem, we employ variational methods for posterior computation, naturally encoding the complexity and multi-modality of the decision making problem. We propose a Stein variational gradient descent method to estimate the posterior directly over control parameters, given a cost function and observed state trajectories. We show that this framework leads to successful planning in challenging, non-convex optimal control problems.
Grasping with Chopsticks: Combating Covariate Shift in Model-free Imitation Learning for Fine Manipulation
Nov 13, 2020
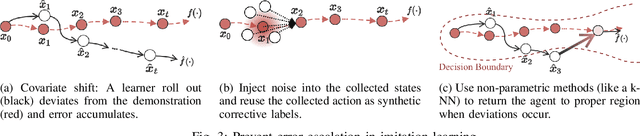

Billions of people use chopsticks, a simple yet versatile tool, for fine manipulation of everyday objects. The small, curved, and slippery tips of chopsticks pose a challenge for picking up small objects, making them a suitably complex test case. This paper leverages human demonstrations to develop an autonomous chopsticks-equipped robotic manipulator. Due to the lack of accurate models for fine manipulation, we explore model-free imitation learning, which traditionally suffers from the covariate shift phenomenon that causes poor generalization. We propose two approaches to reduce covariate shift, neither of which requires access to an interactive expert or a model, unlike previous approaches. First, we alleviate single-step prediction errors by applying an invariant operator to increase the data support at critical steps for grasping. Second, we generate synthetic corrective labels by adding bounded noise and combining parametric and non-parametric methods to prevent error accumulation. We demonstrate our methods on a real chopstick-equipped robot that we built, and observe the agent's success rate increase from 37.3% to 80%, which is comparable to the human expert performance of 82.6%.
Geometric Fabrics for the Acceleration-based Design of Robotic Motion
Nov 11, 2020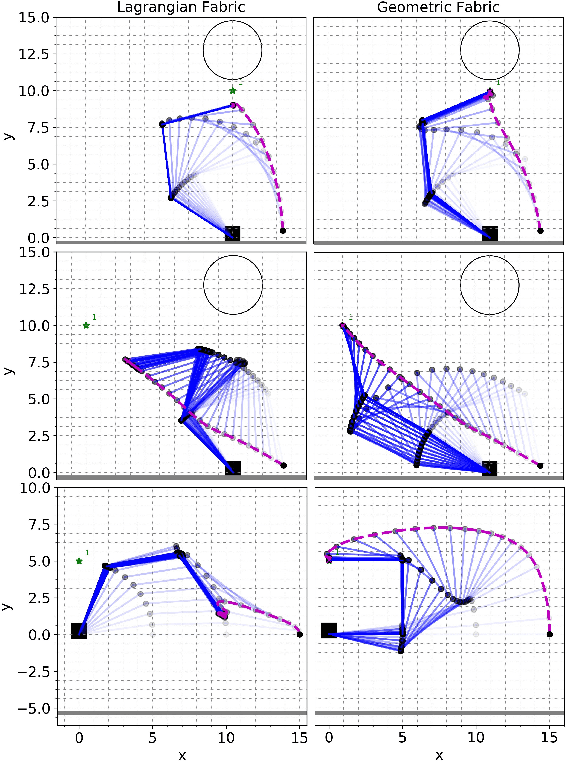

This paper describes the pragmatic design and construction of geometric fabrics for shaping a robot's task-independent nominal behavior, capturing behavioral components such as obstacle avoidance, joint limit avoidance, redundancy resolution, global navigation heuristics, etc. Geometric fabrics constitute the most concrete incarnation of a new mathematical formulation for reactive behavior called optimization fabrics. Fabrics generalize recent work on Riemannian Motion Policies (RMPs); they add provable stability guarantees and improve design consistency while promoting the intuitive acceleration-based principles of modular design that make RMPs successful. We describe a suite of mathematical modeling tools that practitioners can employ in practice and demonstrate both how to mitigate system complexity by constructing behaviors layer-wise and how to employ these tools to design robust, strongly-generalizing, policies that solve practical problems one would expect to find in industry applications. Our system exhibits intelligent global navigation behaviors expressed entirely as fabrics with zero planning or state machine governance.
Quantum Tensor Networks, Stochastic Processes, and Weighted Automata
Oct 20, 2020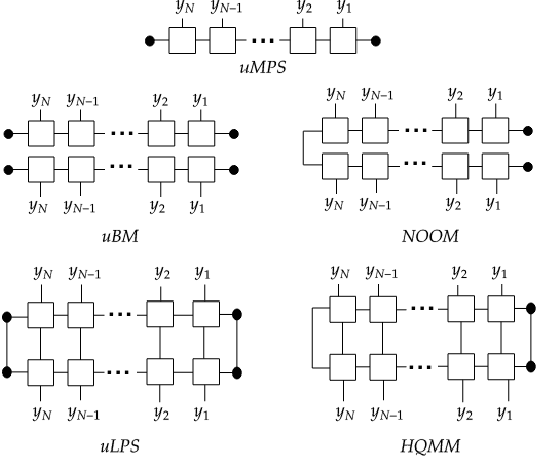
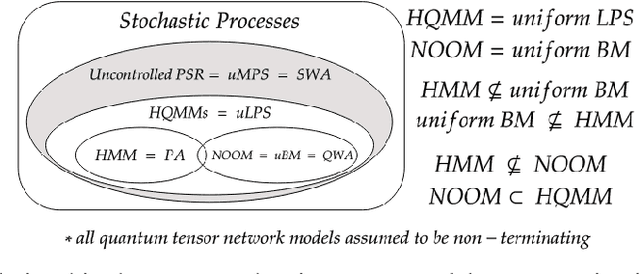
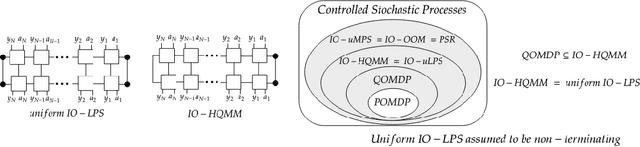
Modeling joint probability distributions over sequences has been studied from many perspectives. The physics community developed matrix product states, a tensor-train decomposition for probabilistic modeling, motivated by the need to tractably model many-body systems. But similar models have also been studied in the stochastic processes and weighted automata literature, with little work on how these bodies of work relate to each other. We address this gap by showing how stationary or uniform versions of popular quantum tensor network models have equivalent representations in the stochastic processes and weighted automata literature, in the limit of infinitely long sequences. We demonstrate several equivalence results between models used in these three communities: (i) uniform variants of matrix product states, Born machines and locally purified states from the quantum tensor networks literature, (ii) predictive state representations, hidden Markov models, norm-observable operator models and hidden quantum Markov models from the stochastic process literature,and (iii) stochastic weighted automata, probabilistic automata and quadratic automata from the formal languages literature. Such connections may open the door for results and methods developed in one area to be applied in another.
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
Oct 05, 2020
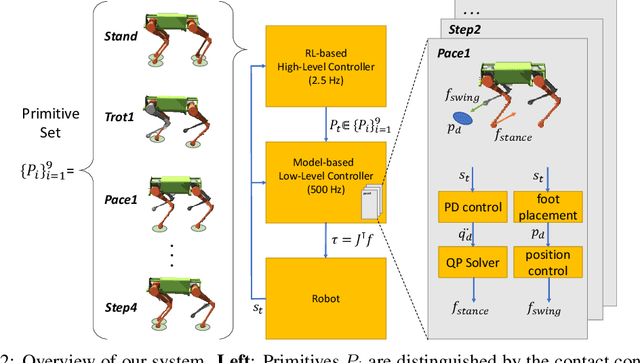

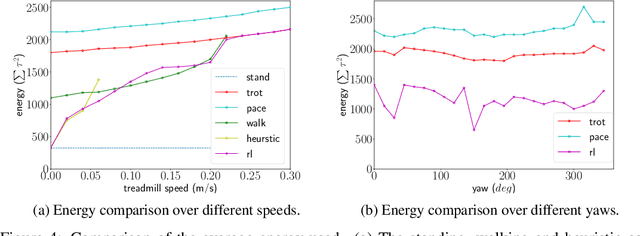
We present a hierarchical framework that combines model-based control and reinforcement learning (RL) to synthesize robust controllers for a quadruped (the Unitree Laikago). The system consists of a high-level controller that learns to choose from a set of primitives in response to changes in the environment and a low-level controller that utilizes an established control method to robustly execute the primitives. Our framework learns a controller that can adapt to challenging environmental changes on the fly, including novel scenarios not seen during training. The learned controller is up to 85~percent more energy efficient and is more robust compared to baseline methods. We also deploy the controller on a physical robot without any randomization or adaptation scheme.
RMPflow: A Geometric Framework for Generation of Multi-Task Motion Policies
Jul 25, 2020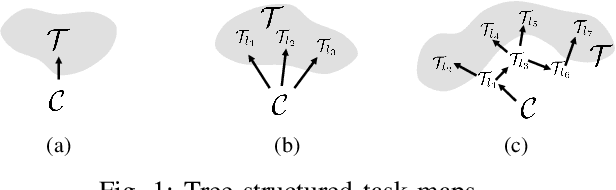
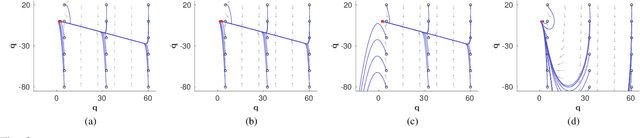
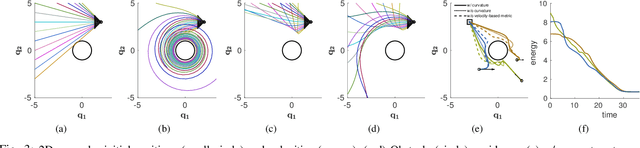
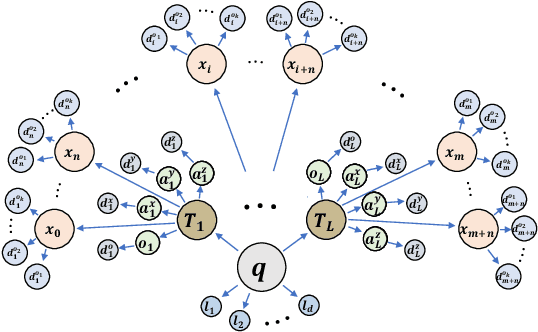
Generating robot motion for multiple tasks in dynamic environments is challenging, requiring an algorithm to respond reactively while accounting for complex nonlinear relationships between tasks. In this paper, we develop a novel policy synthesis algorithm, RMPflow, based on geometrically consistent transformations of Riemannian Motion Policies (RMPs). RMPs are a class of reactive motion policies that parameterize non-Euclidean behaviors as dynamical systems in intrinsically nonlinear task spaces. Given a set of RMPs designed for individual tasks, RMPflow can combine these policies to generate an expressive global policy, while simultaneously exploiting sparse structure for computational efficiency. We study the geometric properties of RMPflow and provide sufficient conditions for stability. Finally, we experimentally demonstrate that accounting for the natural Riemannian geometry of task policies can simplify classically difficult problems, such as planning through clutter on high-DOF manipulation systems.
Explaining Fast Improvement in Online Policy Optimization
Jul 08, 2020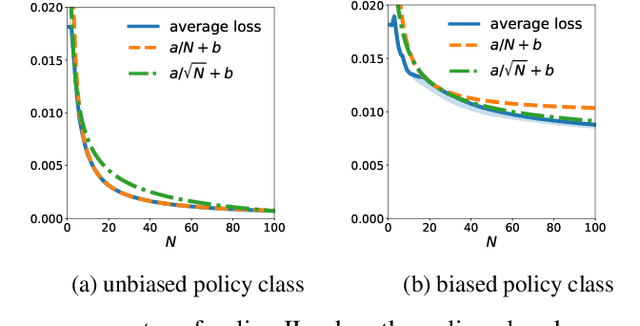
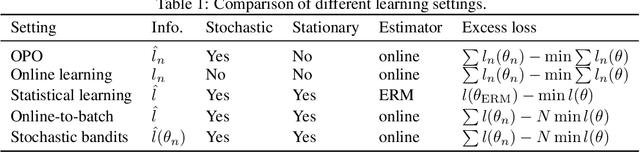
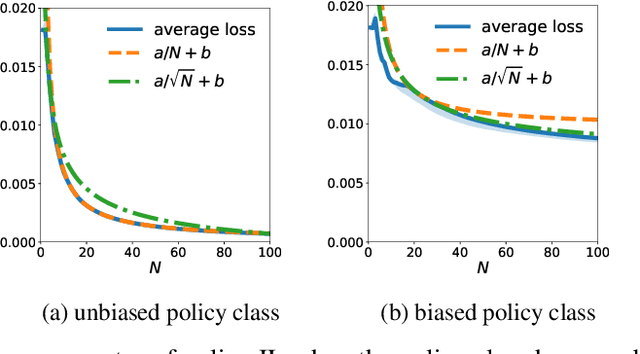
Online policy optimization (OPO) views policy optimization for sequential decision making as an online learning problem. In this framework, the algorithm designer defines a sequence of online loss functions such that the regret rate in online learning implies the policy convergence rate and the minimal loss witnessed by the policy class determines the policy performance bias. This reduction technique has been successfully applied to solving various policy optimization problems, including imitation learning, structured prediction, and system identification. Interestingly, the policy improvement speed observed in practice is usually much faster than existing theory suggests. In this work, we provide an explanation of this fast policy improvement phenomenon. Let $\epsilon$ denote the policy class bias and assume the online loss functions are convex, smooth, and non-negative. We prove that, after $N$ rounds of OPO with stochastic feedback, the policy converges in $\tilde{O}(1/N + \sqrt{\epsilon/N})$ in both expectation and high probability. In other words, we show that adopting a sufficiently expressive policy class in OPO has two benefits: both the convergence rate increases and the performance bias decreases, as the policy class becomes reasonably rich. This new theoretical insight is further verified in an online imitation learning experiment.
Euclideanizing Flows: Diffeomorphic Reduction for Learning Stable Dynamical Systems
May 27, 2020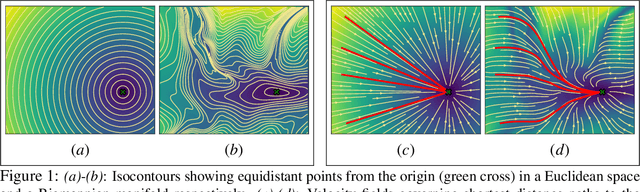
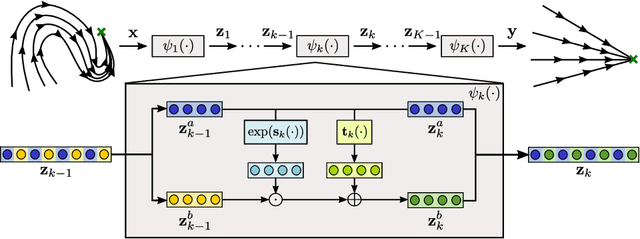
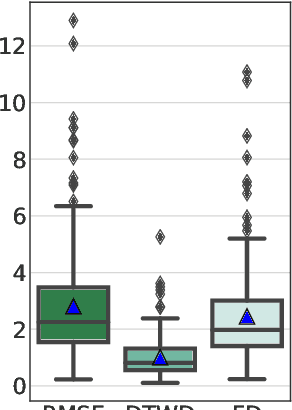
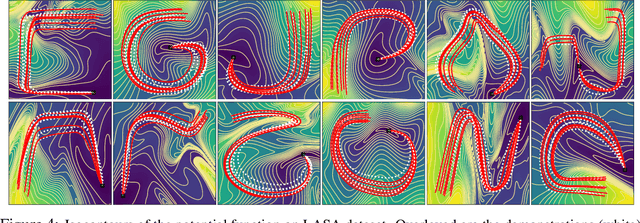
Robotic tasks often require motions with complex geometric structures. We present an approach to learn such motions from a limited number of human demonstrations by exploiting the regularity properties of human motions e.g. stability, smoothness, and boundedness. The complex motions are encoded as rollouts of a stable dynamical system, which, under a change of coordinates defined by a diffeomorphism, is equivalent to a simple, hand-specified dynamical system. As an immediate result of using diffeomorphisms, the stability property of the hand-specified dynamical system directly carry over to the learned dynamical system. Inspired by recent works in density estimation, we propose to represent the diffeomorphism as a composition of simple parameterized diffeomorphisms. Additional structure is imposed to provide guarantees on the smoothness of the generated motions. The efficacy of this approach is demonstrated through validation on an established benchmark as well demonstrations collected on a real-world robotic system.
In Defense of Graph Inference Algorithms for Weakly Supervised Object Localization
Mar 18, 2020
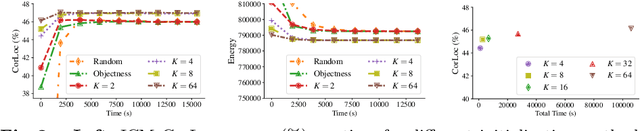


Weakly Supervised Object Localization (WSOL) methods have become increasingly popular since they only require image level labels as opposed to expensive bounding box annotations required by fully supervised algorithms. Typically, a WSOL model is first trained to predict class generic objectness scores on an off-the-shelf fully supervised source dataset and then it is progressively adapted to learn the objects in the weakly supervised target dataset. In this work, we argue that learning only an objectness function is a weak form of knowledge transfer and propose to learn a classwise pairwise similarity function that directly compares two input proposals as well. The combined localization model and the estimated object annotations are jointly learned in an alternating optimization paradigm as is typically done in standard WSOL methods. In contrast to the existing work that learns pairwise similarities, our proposed approach optimizes a unified objective with convergence guarantee and it is computationally efficient for large-scale applications. Experiments on the COCO and ILSVRC 2013 detection datasets show that the performance of the localization model improves significantly with the inclusion of pairwise similarity function. For instance, in the ILSVRC dataset, the Correct Localization (CorLoc) performance improves from 72.7% to 78.2% which is a new state-of-the-art for weakly supervised object localization task.
Intra Order-preserving Functions for Calibration of Multi-Class Neural Networks
Mar 15, 2020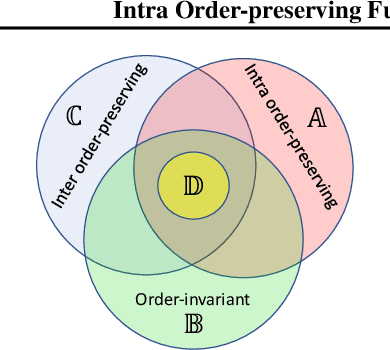

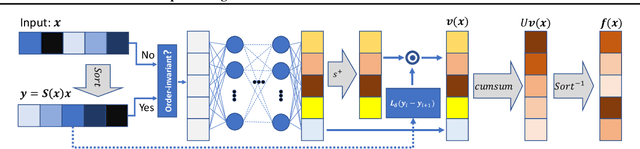
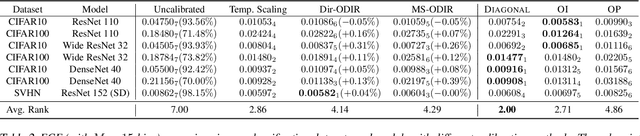
Predicting calibrated confidence scores for multi-class deep networks is important for avoiding rare but costly mistakes. A common approach is to learn a post-hoc calibration function that transforms the output of the original network into calibrated confidence scores while maintaining the network's accuracy. However, previous post-hoc calibration techniques work only with simple calibration functions, potentially lacking sufficient representation to calibrate the complex function landscape of deep networks. In this work, we aim to learn general post-hoc calibration functions that can preserve the top-k predictions of any deep network. We call this family of functions intra order-preserving functions. We propose a new neural network architecture that represents a class of intra order-preserving functions by combining common neural network components. Additionally, we introduce order-invariant and diagonal sub-families, which can act as regularization for better generalization when the training data size is small. We show the effectiveness of the proposed method across a wide range of datasets and classifiers. Our method outperforms state-of-the-art post-hoc calibration methods, namely temperature scaling and Dirichlet calibration, in multiple settings.