 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
May 22, 2020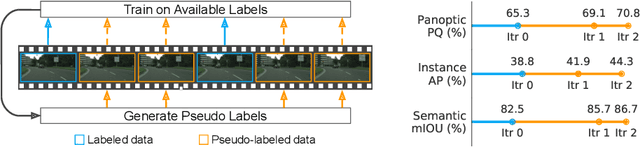

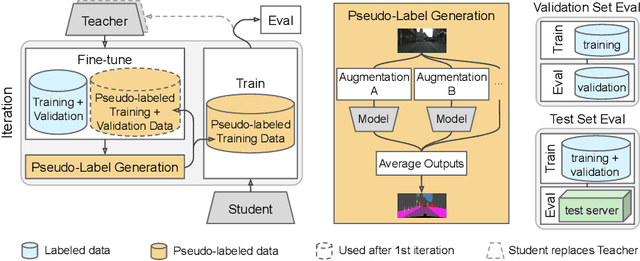
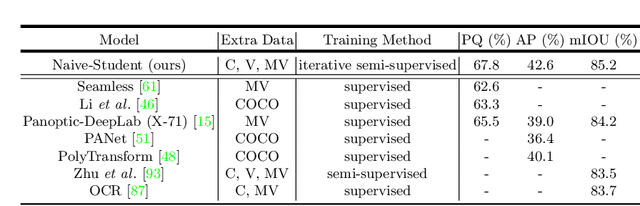
Supervised learning in large discriminative models is a mainstay for modern computer vision. Such an approach necessitates investing in large-scale human-annotated datasets for achieving state-of-the-art results. In turn, the efficacy of supervised learning may be limited by the size of the human annotated dataset. This limitation is particularly notable for image segmentation tasks, where the expense of human annotation is especially large, yet large amounts of unlabeled data may exist. In this work, we ask if we may leverage semi-supervised learning in unlabeled video sequences to improve the performance on urban scene segmentation, simultaneously tackling semantic, instance, and panoptic segmentation. The goal of this work is to avoid the construction of sophisticated, learned architectures specific to label propagation (e.g., patch matching and optical flow). Instead, we simply predict pseudo-labels for the unlabeled data and train subsequent models with both human-annotated and pseudo-labeled data. The procedure is iterated for several times. As a result, our Naive-Student model, trained with such simple yet effective iterative semi-supervised learning, attains state-of-the-art results at all three Cityscapes benchmarks, reaching the performance of 67.8% PQ, 42.6% AP, and 85.2% mIOU on the test set. We view this work as a notable step towards building a simple procedure to harness unlabeled video sequences to surpass state-of-the-art performance on core computer vision tasks.
Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
Dec 06, 2019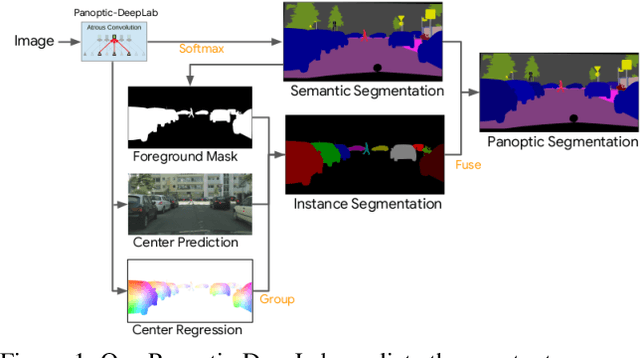

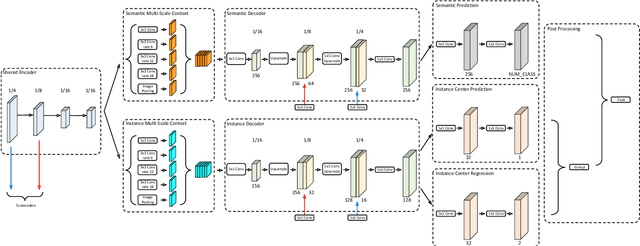
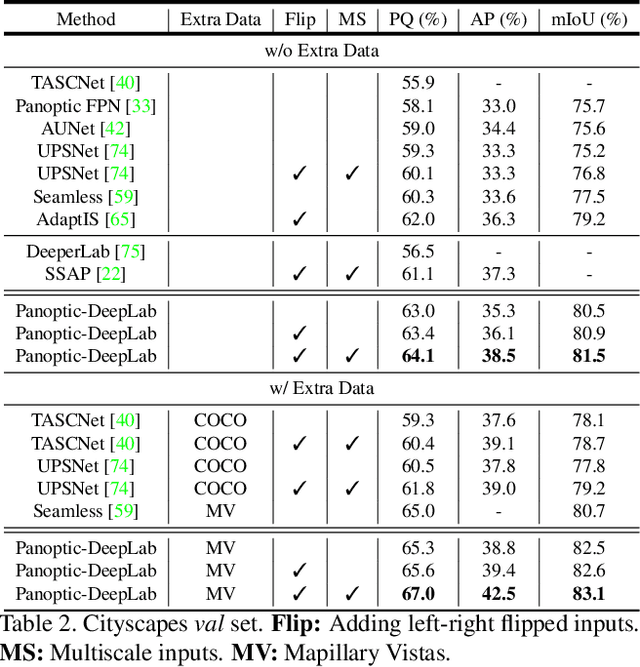
In this work, we introduce Panoptic-DeepLab, a simple, strong, and fast system for panoptic segmentation, aiming to establish a solid baseline for bottom-up methods that can achieve comparable performance of two-stage methods while yielding fast inference speed. In particular, PanopticDeepLab adopts the dual-ASPP and dual-decoder structures specific to semantic, and instance segmentation, respectively. The semantic segmentation branch is the same as the typical design of any semantic segmentation model (e.g., DeepLab), while the instance segmentation branch is class-agnostic, involving a simple instance center regression. As a result, our single Panoptic-DeepLab simultaneously ranks first at all three Cityscapes benchmarks, setting the new state-of-art of 84.2% mIoU, 39.0% AP, and 65.5% PQ on test set. Additionally, equipped with MobileNetV3, Panoptic-DeepLab runs nearly in real-time with a single 1025 x 2049 image (15.8 frames per second), while achieving a competitive performance on Cityscapes (54.1 PQ% on test set). On Mapillary Vistas test set, our ensemble of six models attains 42.7% PQ, outperforming the challenge winner in 2018 by a healthy margin of 1.5%. Finally, our Panoptic-DeepLab also performs on par with several topdown approaches on the challenging COCO dataset. For the first time, we demonstrate a bottom-up approach could deliver state-of-the-art results on panoptic segmentation.
Panoptic-DeepLab
Oct 24, 2019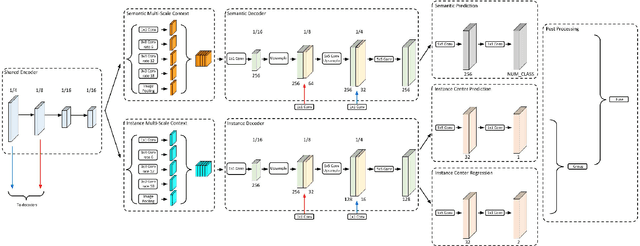
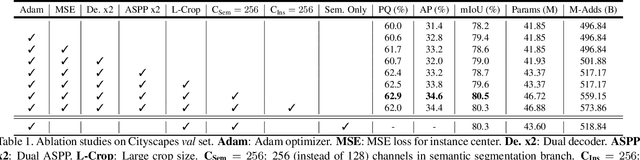
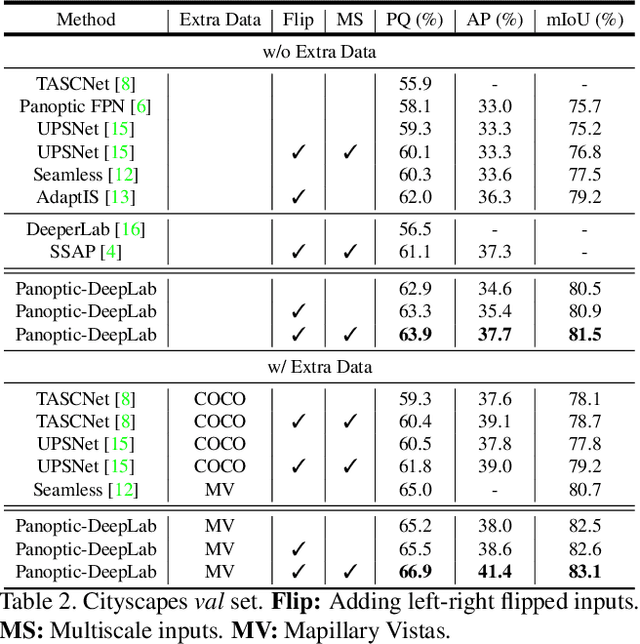
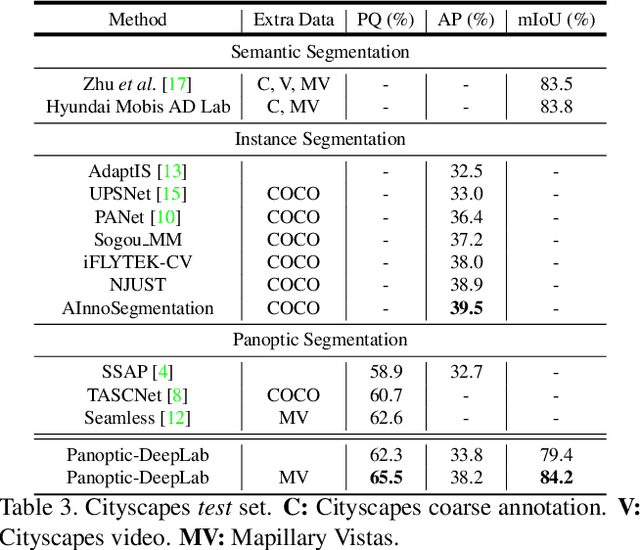
We present Panoptic-DeepLab, a bottom-up and single-shot approach for panoptic segmentation. Our Panoptic-DeepLab is conceptually simple and delivers state-of-the-art results. In particular, we adopt the dual-ASPP and dual-decoder structures specific to semantic, and instance segmentation, respectively. The semantic segmentation branch is the same as the typical design of any semantic segmentation model (e.g., DeepLab), while the instance segmentation branch is class-agnostic, involving a simple instance center regression. Our single Panoptic-DeepLab sets the new state-of-art at all three Cityscapes benchmarks, reaching 84.2% mIoU, 39.0% AP, and 65.5% PQ on test set, and advances results on the other challenging Mapillary Vistas.
SkyNet: a Hardware-Efficient Method for Object Detection and Tracking on Embedded Systems
Sep 20, 2019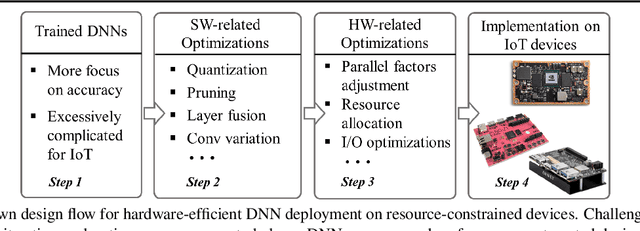
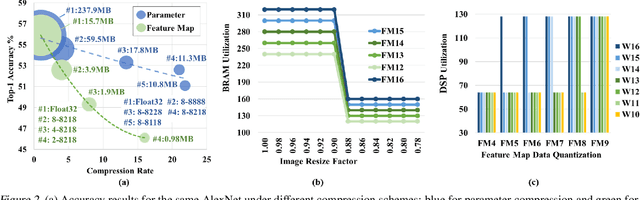

Developing object detection and tracking on resource-constrained embedded systems is challenging. While object detection is one of the most compute-intensive tasks from the artificial intelligence domain, it is only allowed to use limited computation and memory resources on embedded devices. In the meanwhile, such resource-constrained implementations are often required to satisfy additional demanding requirements such as real-time response, high-throughput performance, and reliable inference accuracy. To overcome these challenges, we propose SkyNet, a hardware-efficient method to deliver the state-of-the-art detection accuracy and speed for embedded systems. Instead of following the common top-down flow for compact DNN design, SkyNet provides a bottom-up DNN design approach with comprehensive understanding of the hardware constraints at the very beginning to deliver hardware-efficient DNNs. The effectiveness of SkyNet is demonstrated by winning the extremely competitive System Design Contest for low power object detection in the 56th IEEE/ACM Design Automation Conference (DAC-SDC), where our SkyNet significantly outperforms all other 100+ competitors: it delivers 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 embedded GPU; and 0.716 IoU and 25.05 FPS on an Ultra96 embedded FPGA. The evaluation of SkyNet is also extended to GOT-10K, a recent large-scale high-diversity benchmark for generic object tracking in the wild. For state-of-the-art object trackers SiamRPN++ and SiamMask, where ResNet-50 is employed as the backbone, implementations using our SkyNet as the backbone DNN are 1.60X and 1.73X faster with better or similar accuracy when running on a 1080Ti GPU, and 37.20X smaller in terms of parameter size for significantly better memory and storage footprint.
Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation
Aug 27, 2019
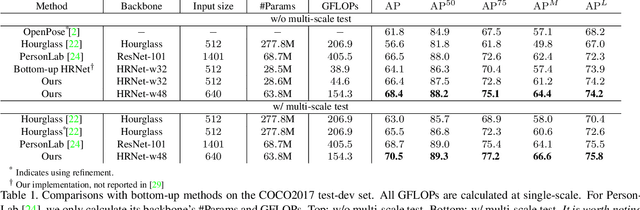
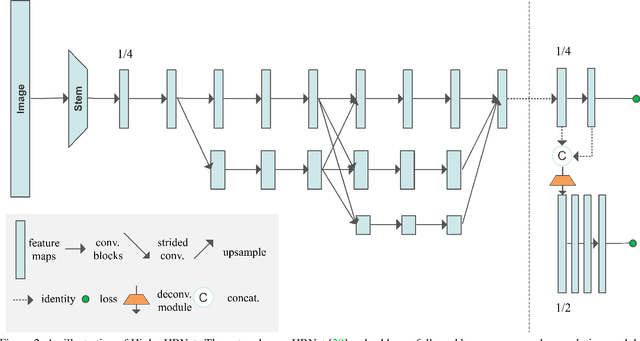
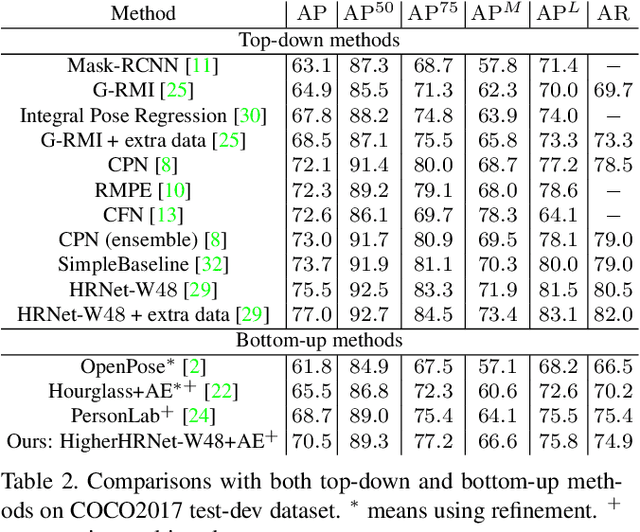
In this paper, we are interested in bottom-up multi-person human pose estimation. A typical bottom-up pipeline consists of two main steps: heatmap prediction and keypoint grouping. We mainly focus on the first step for improving heatmap prediction accuracy. We propose Higher-Resolution Network (HigherHRNet), which is a simple extension of the High-Resolution Network (HRNet). HigherHRNet generates higher-resolution feature maps by deconvolving the high-resolution feature maps outputted by HRNet, which are spatially more accurate for small and medium persons. Then, we build high-quality multi-level features and perform multi-scale pose prediction. The extra computation overhead is marginal and negligible in comparison to existing bottom-up methods that rely on multi-scale image pyramids or large input image size to generate accurate pose heatmaps. HigherHRNet surpasses all existing bottom-up methods on the COCO dataset without using multi-scale test. The code and models will be released.
SPGNet: Semantic Prediction Guidance for Scene Parsing
Aug 26, 2019
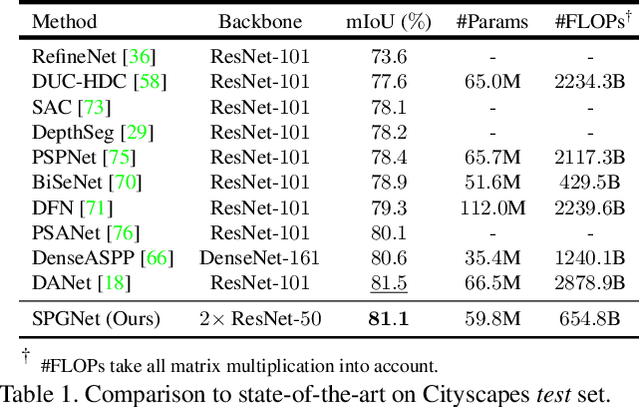
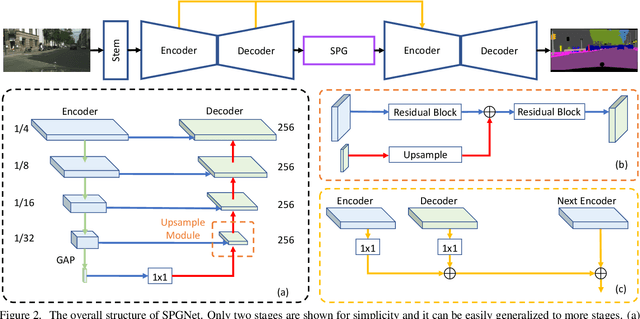

Multi-scale context module and single-stage encoder-decoder structure are commonly employed for semantic segmentation. The multi-scale context module refers to the operations to aggregate feature responses from a large spatial extent, while the single-stage encoder-decoder structure encodes the high-level semantic information in the encoder path and recovers the boundary information in the decoder path. In contrast, multi-stage encoder-decoder networks have been widely used in human pose estimation and show superior performance than their single-stage counterpart. However, few efforts have been attempted to bring this effective design to semantic segmentation. In this work, we propose a Semantic Prediction Guidance (SPG) module which learns to re-weight the local features through the guidance from pixel-wise semantic prediction. We find that by carefully re-weighting features across stages, a two-stage encoder-decoder network coupled with our proposed SPG module can significantly outperform its one-stage counterpart with similar parameters and computations. Finally, we report experimental results on the semantic segmentation benchmark Cityscapes, in which our SPGNet attains 81.1% on the test set using only 'fine' annotations.
High Frequency Residual Learning for Multi-Scale Image Classification
May 07, 2019

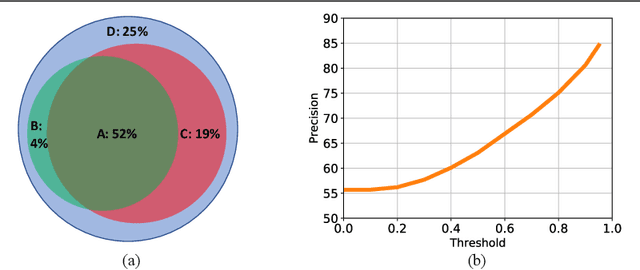
We present a novel high frequency residual learning framework, which leads to a highly efficient multi-scale network (MSNet) architecture for mobile and embedded vision problems. The architecture utilizes two networks: a low resolution network to efficiently approximate low frequency components and a high resolution network to learn high frequency residuals by reusing the upsampled low resolution features. With a classifier calibration module, MSNet can dynamically allocate computation resources during inference to achieve a better speed and accuracy trade-off. We evaluate our methods on the challenging ImageNet-1k dataset and observe consistent improvements over different base networks. On ResNet-18 and MobileNet with alpha=1.0, MSNet gains 1.5% accuracy over both architectures without increasing computations. On the more efficient MobileNet with alpha=0.25, our method gains 3.8% accuracy with the same amount of computations.
Revisiting Pre-training: An Efficient Training Method for Image Classification
Nov 23, 2018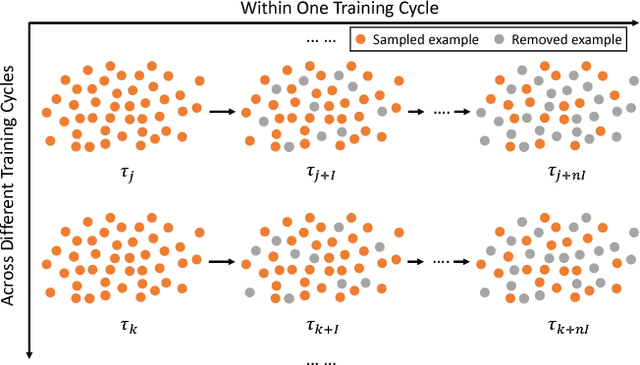

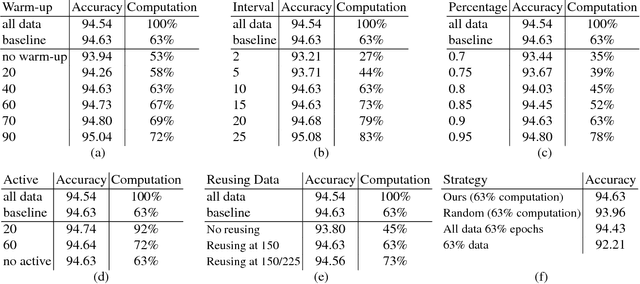

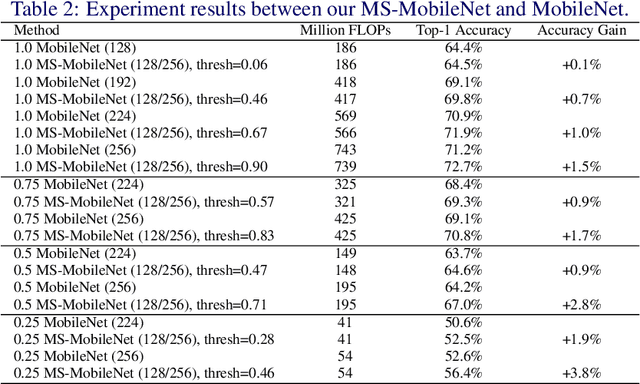
The training method of repetitively feeding all samples into a pre-defined network for image classification has been widely adopted by current state-of-the-art. In this work, we provide a new method, which can be leveraged to train classification networks in a more efficient way. Starting with a warm-up step, we propose to continually repeat a Drop-and-Pick (DaP) learning strategy. In particular, we drop those easy samples to encourage the network to focus on studying hard ones. Meanwhile, by picking up all samples periodically during training, we aim to recall the memory of the networks to prevent catastrophic forgetting of previously learned knowledge. Our DaP learning method can recover 99.88%, 99.60%, 99.83% top-1 accuracy on ImageNet for ResNet-50, DenseNet-121, and MobileNet-V1 but only requires 75% computation in training compared to those using the classic training schedule. Furthermore, our pre-trained models are equipped with strong knowledge transferability when used for downstream tasks, especially for hard cases. Extensive experiments on object detection, instance segmentation and pose estimation can well demonstrate the effectiveness of our DaP training method.
Revisit Multinomial Logistic Regression in Deep Learning: Data Dependent Model Initialization for Image Recognition
Sep 17, 2018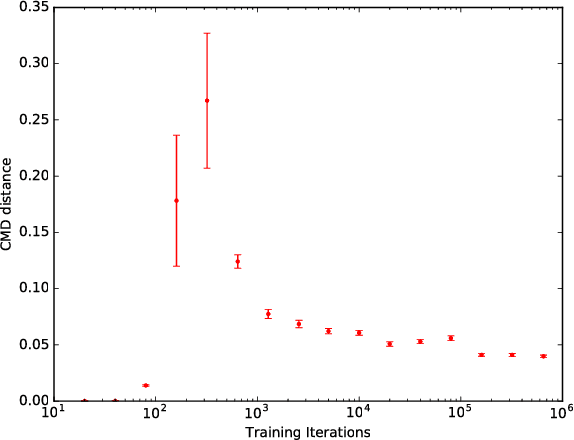
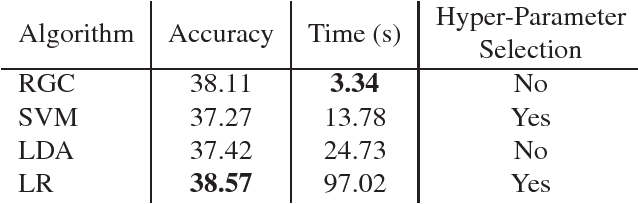
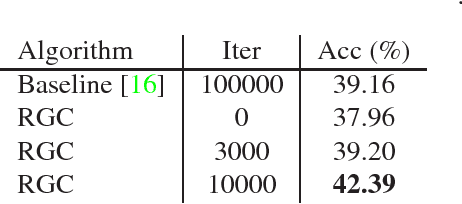
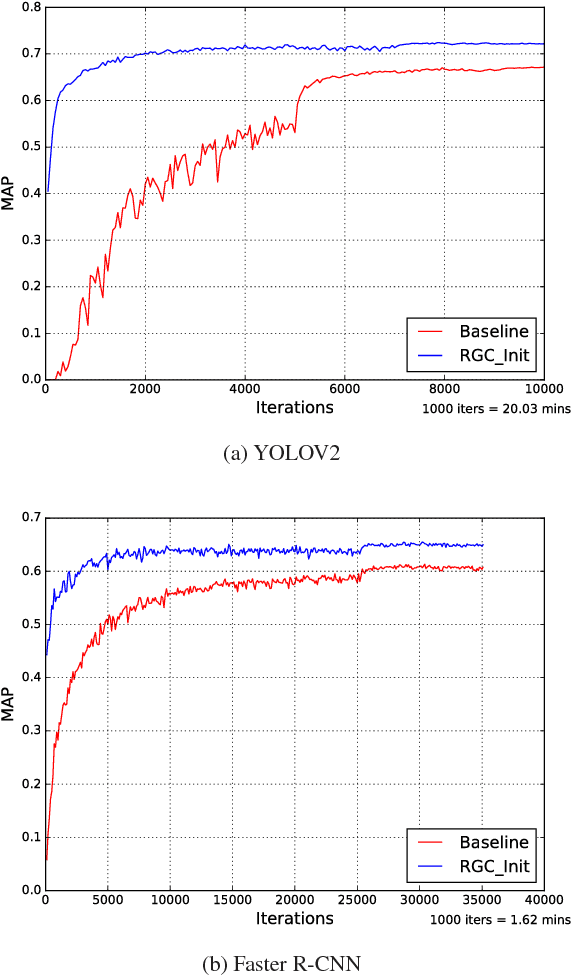
We study in this paper how to initialize the parameters of multinomial logistic regression (a fully connected layer followed with softmax and cross entropy loss), which is widely used in deep neural network (DNN) models for classification problems. As logistic regression is widely known not having a closed-form solution, it is usually randomly initialized, leading to several deficiencies especially in transfer learning where all the layers except for the last task-specific layer are initialized using a pre-trained model. The deficiencies include slow convergence speed, possibility of stuck in local minimum, and the risk of over-fitting. To address those deficiencies, we first study the properties of logistic regression and propose a closed-form approximate solution named regularized Gaussian classifier (RGC). Then we adopt this approximate solution to initialize the task-specific linear layer and demonstrate superior performance over random initialization in terms of both accuracy and convergence speed on various tasks and datasets. For example, for image classification, our approach can reduce the training time by 10 times and achieve 3.2% gain in accuracy for Flickr-style classification. For object detection, our approach can also be 10 times faster in training for the same accuracy, or 5% better in terms of mAP for VOC 2007 with slightly longer training.
Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
Jul 14, 2018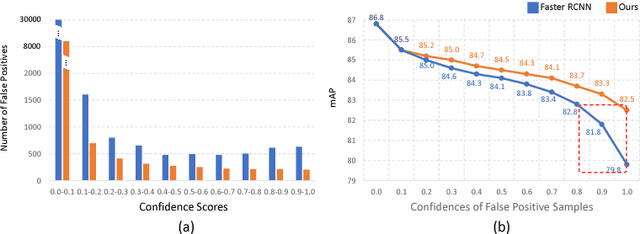
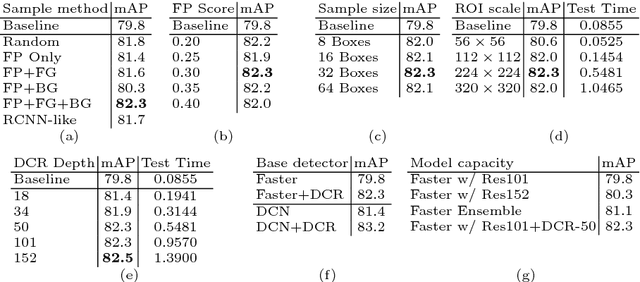
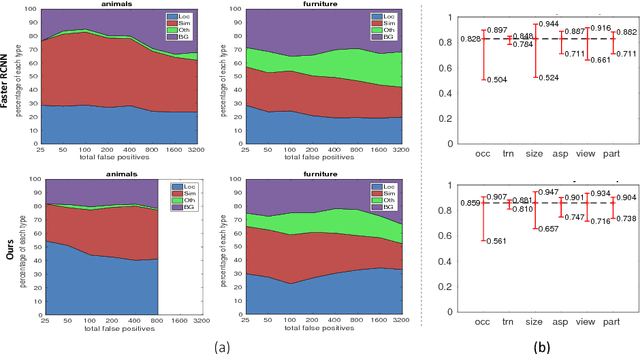
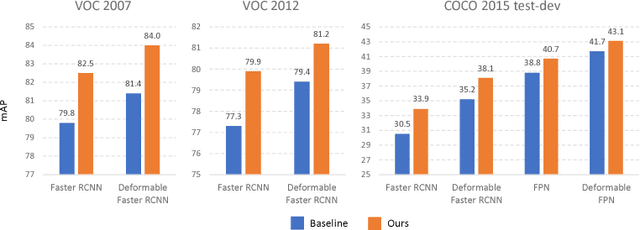
Recent region-based object detectors are usually built with separate classification and localization branches on top of shared feature extraction networks. In this paper, we analyze failure cases of state-of-the-art detectors and observe that most hard false positives result from classification instead of localization. We conjecture that: (1) Shared feature representation is not optimal due to the mismatched goals of feature learning for classification and localization; (2) multi-task learning helps, yet optimization of the multi-task loss may result in sub-optimal for individual tasks; (3) large receptive field for different scales leads to redundant context information for small objects.We demonstrate the potential of detector classification power by a simple, effective, and widely-applicable Decoupled Classification Refinement (DCR) network. DCR samples hard false positives from the base classifier in Faster RCNN and trains a RCNN-styled strong classifier. Experiments show new state-of-the-art results on PASCAL VOC and COCO without any bells and whistles.