 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Latent Reasoning via Looped Language Models
Oct 29, 2025



Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
VGR: Visual Grounded Reasoning
Jun 16, 2025In the field of multimodal chain-of-thought (CoT) reasoning, existing approaches predominantly rely on reasoning on pure language space, which inherently suffers from language bias and is largely confined to math or science domains. This narrow focus limits their ability to handle complex visual reasoning tasks that demand comprehensive understanding of image details. To address these limitations, this paper introduces VGR, a novel reasoning multimodal large language model (MLLM) with enhanced fine-grained visual perception capabilities. Unlike traditional MLLMs that answer the question or reasoning solely on the language space, our VGR first detects relevant regions that may help to solve problems, and then provides precise answers based on replayed image regions. To achieve this, we conduct a large-scale SFT dataset called VGR -SFT that contains reasoning data with mixed vision grounding and language deduction. The inference pipeline of VGR allows the model to choose bounding boxes for visual reference and a replay stage is introduced to integrates the corresponding regions into the reasoning process, enhancing multimodel comprehension. Experiments on the LLaVA-NeXT-7B baseline show that VGR achieves superior performance on multi-modal benchmarks requiring comprehensive image detail understanding. Compared to the baseline, VGR uses only 30\% of the image token count while delivering scores of +4.1 on MMStar, +7.1 on AI2D, and a +12.9 improvement on ChartQA.
Efficient Pretraining Length Scaling
Apr 21, 2025Recent advances in large language models have demonstrated the effectiveness of length scaling during post-training, yet its potential in pre-training remains underexplored. We present the Parallel Hidden Decoding Transformer (\textit{PHD}-Transformer), a novel framework that enables efficient length scaling during pre-training while maintaining inference efficiency. \textit{PHD}-Transformer achieves this through an innovative KV cache management strategy that distinguishes between original tokens and hidden decoding tokens. By retaining only the KV cache of original tokens for long-range dependencies while immediately discarding hidden decoding tokens after use, our approach maintains the same KV cache size as the vanilla transformer while enabling effective length scaling. To further enhance performance, we introduce two optimized variants: \textit{PHD-SWA} employs sliding window attention to preserve local dependencies, while \textit{PHD-CSWA} implements chunk-wise sliding window attention to eliminate linear growth in pre-filling time. Extensive experiments demonstrate consistent improvements across multiple benchmarks.
World to Code: Multi-modal Data Generation via Self-Instructed Compositional Captioning and Filtering
Sep 30, 2024



Recent advances in Vision-Language Models (VLMs) and the scarcity of high-quality multi-modal alignment data have inspired numerous researches on synthetic VLM data generation. The conventional norm in VLM data construction uses a mixture of specialists in caption and OCR, or stronger VLM APIs and expensive human annotation. In this paper, we present World to Code (W2C), a meticulously curated multi-modal data construction pipeline that organizes the final generation output into a Python code format. The pipeline leverages the VLM itself to extract cross-modal information via different prompts and filter the generated outputs again via a consistency filtering strategy. Experiments have demonstrated the high quality of W2C by improving various existing visual question answering and visual grounding benchmarks across different VLMs. Further analysis also demonstrates that the new code parsing ability of VLMs presents better cross-modal equivalence than the commonly used detail caption ability. Our code is available at https://github.com/foundation-multimodal-models/World2Code.
Benchmarking and Improving Detail Image Caption
May 29, 2024



Image captioning has long been regarded as a fundamental task in visual understanding. Recently, however, few large vision-language model (LVLM) research discusses model's image captioning performance because of the outdated short-caption benchmarks and unreliable evaluation metrics. In this work, we propose to benchmark detail image caption task by curating high-quality evaluation datasets annotated by human experts, GPT-4V and Gemini-1.5-Pro. We also design a more reliable caption evaluation metric called CAPTURE (CAPtion evaluation by exTracting and coUpling coRE information). CAPTURE extracts visual elements, e.g., objects, attributes and relations from captions, and then matches these elements through three stages, achieving the highest consistency with expert judgements over other rule-based or model-based caption metrics. The proposed benchmark and metric provide reliable evaluation for LVLM's detailed image captioning ability. Guided by this evaluation, we further explore to unleash LVLM's detail caption capabilities by synthesizing high-quality data through a five-stage data construction pipeline. Our pipeline only uses a given LVLM itself and other open-source tools, without any human or GPT-4V annotation in the loop. Experiments show that the proposed data construction strategy significantly improves model-generated detail caption data quality for LVLMs with leading performance, and the data quality can be further improved in a self-looping paradigm. All code and dataset will be publicly available at https://github.com/foundation-multimodal-models/CAPTURE.
Seeing the Image: Prioritizing Visual Correlation by Contrastive Alignment
May 28, 2024



Existing image-text modality alignment in Vision Language Models (VLMs) treats each text token equally in an autoregressive manner. Despite being simple and effective, this method results in sub-optimal cross-modal alignment by over-emphasizing the text tokens that are less correlated with or even contradictory with the input images. In this paper, we advocate for assigning distinct contributions for each text token based on its visual correlation. Specifically, we present by contrasting image inputs, the difference in prediction logits on each text token provides strong guidance of visual correlation. We therefore introduce Contrastive ALignment (CAL), a simple yet effective re-weighting strategy that prioritizes training visually correlated tokens. Our experimental results demonstrate that CAL consistently improves different types of VLMs across different resolutions and model sizes on various benchmark datasets. Importantly, our method incurs minimal additional computational overhead, rendering it highly efficient compared to alternative data scaling strategies. Codes are available at https://github.com/foundation-multimodal-models/CAL.
Extrapolating Multilingual Understanding Models as Multilingual Generators
May 22, 2023



Multilingual understanding models (or encoder-based), pre-trained via masked language modeling, have achieved promising results on many language understanding tasks (e.g., mBERT). However, these non-autoregressive (NAR) models still struggle to generate high-quality texts compared with autoregressive (AR) models. Considering that encoder-based models have the advantage of efficient generation and self-correction abilities, this paper explores methods to empower multilingual understanding models the generation abilities to get a unified model. Specifically, we start from a multilingual encoder (XLM-R) and propose a \textbf{S}emantic-\textbf{G}uided \textbf{A}lignment-then-Denoising (SGA) approach to adapt an encoder to a multilingual generator with a small number of new parameters. Experiments show that the proposed approach is an effective adaption method, outperforming widely-used initialization-based methods with gains of 9.4 BLEU on machine translation, 8.1 Rouge-L on question generation, and 5.5 METEOR on story generation on XLM-R$_{large}$. On the other hand, we observe that XLM-R is still inferior to mBART in supervised settings despite better results on zero-shot settings, indicating that more exploration is required to make understanding models strong generators.
Sentence Representation Learning with Generative Objective rather than Contrastive Objective
Oct 16, 2022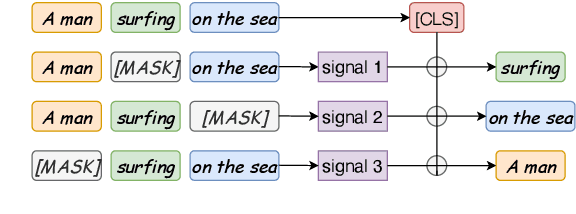
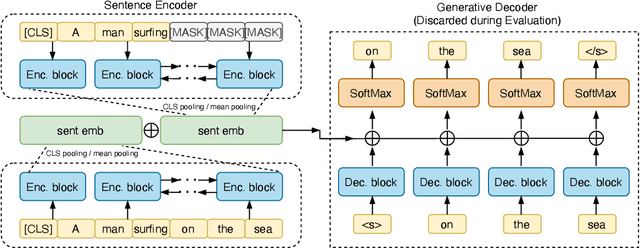
Though offering amazing contextualized token-level representations, current pre-trained language models take less attention on accurately acquiring sentence-level representation during their self-supervised pre-training. However, contrastive objectives which dominate the current sentence representation learning bring little linguistic interpretability and no performance guarantee on downstream semantic tasks. We instead propose a novel generative self-supervised learning objective based on phrase reconstruction. To overcome the drawbacks of previous generative methods, we carefully model intra-sentence structure by breaking down one sentence into pieces of important phrases. Empirical studies show that our generative learning achieves powerful enough performance improvement and outperforms the current state-of-the-art contrastive methods not only on the STS benchmarks, but also on downstream semantic retrieval and reranking tasks. Our code is available at https://github.com/chengzhipanpan/PaSeR.
Generative or Contrastive? Phrase Reconstruction for Better Sentence Representation Learning
Apr 20, 2022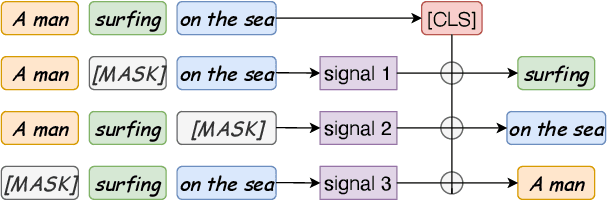
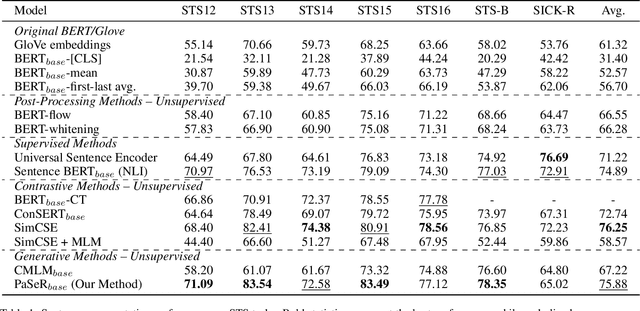
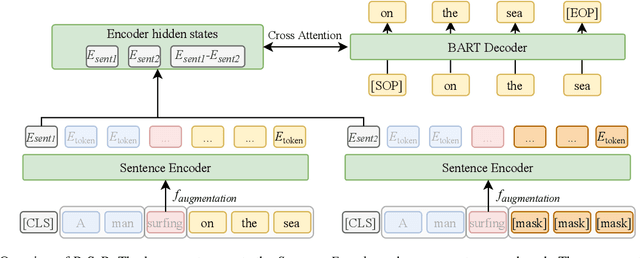
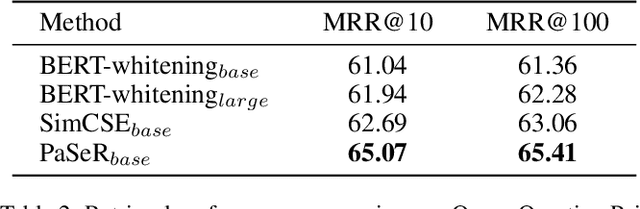
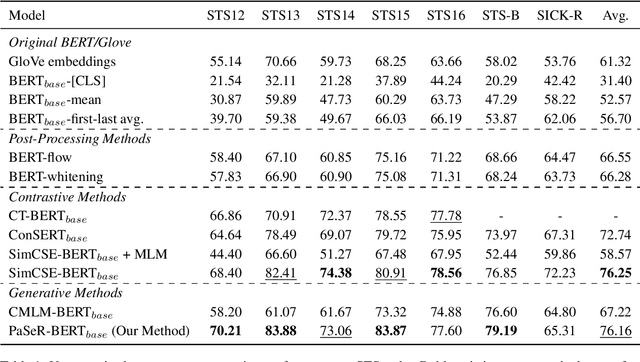
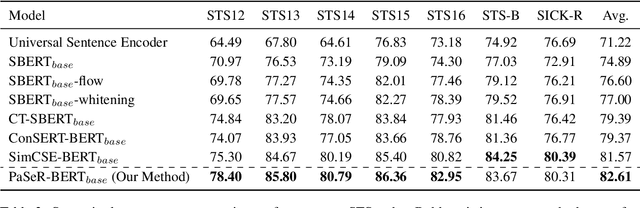
Though offering amazing contextualized token-level representations, current pre-trained language models actually take less attention on acquiring sentence-level representation during its self-supervised pre-training. If self-supervised learning can be distinguished into two subcategories, generative and contrastive, then most existing studies show that sentence representation learning may more benefit from the contrastive methods but not the generative methods. However, contrastive learning cannot be well compatible with the common token-level generative self-supervised learning, and does not guarantee good performance on downstream semantic retrieval tasks. Thus, to alleviate such obvious inconveniences, we instead propose a novel generative self-supervised learning objective based on phrase reconstruction. Empirical studies show that our generative learning may yield powerful enough sentence representation and achieve performance in Sentence Textual Similarity (STS) tasks on par with contrastive learning. Further, in terms of unsupervised setting, our generative method outperforms previous state-of-the-art SimCSE on the benchmark of downstream semantic retrieval tasks.
Representation Decoupling for Open-Domain Passage Retrieval
Oct 14, 2021
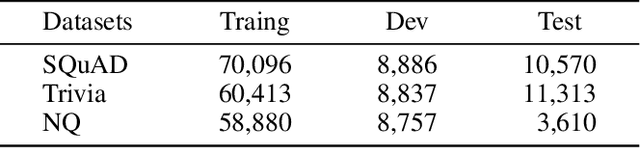
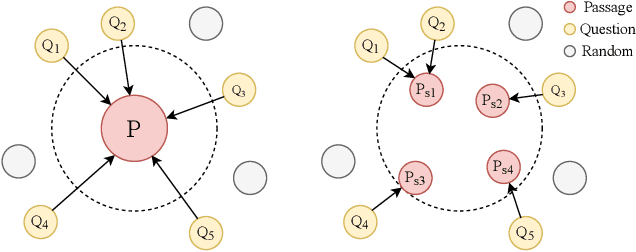

Training dense passage representations via contrastive learning (CL) has been shown effective for Open-Domain Passage Retrieval (ODPR). Recent studies mainly focus on optimizing this CL framework by improving the sampling strategy or extra pretraining. Different from previous studies, this work devotes itself to investigating the influence of conflicts in the widely used CL strategy in ODPR, motivated by our observation that a passage can be organized by multiple semantically different sentences, thus modeling such a passage as a unified dense vector is not optimal. We call such conflicts Contrastive Conflicts. In this work, we propose to solve it with a representation decoupling method, by decoupling the passage representations into contextual sentence-level ones, and design specific CL strategies to mediate these conflicts. Experiments on widely used datasets including Natural Questions, Trivia QA, and SQuAD verify the effectiveness of our method, especially on the dataset where the conflicting problem is severe. Our method also presents good transferability across the datasets, which further supports our idea of mediating Contrastive Conflicts.