 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
Self-prompted Chain-of-Thought on Large Language Models for Open-domain Multi-hop Reasoning
Oct 23, 2023



In open-domain question-answering (ODQA), most existing questions require single-hop reasoning on commonsense. To further extend this task, we officially introduce open-domain multi-hop reasoning (ODMR) by answering multi-hop questions with explicit reasoning steps in open-domain setting. Recently, large language models (LLMs) have found significant utility in facilitating ODQA without external corpus. Furthermore, chain-of-thought (CoT) prompting boosts the reasoning capability of LLMs to a greater extent with manual or automated paradigms. However, existing automated methods lack of quality assurance, while manual approaches suffer from limited scalability and poor diversity, hindering the capabilities of LLMs. In this paper, we propose Self-prompted Chain-of-Thought (SP-CoT), an automated framework to mass-produce high quality CoTs of LLMs, by LLMs and for LLMs. SP-CoT introduces an automated generation pipeline of high quality ODMR datasets, an adaptive sampler for in-context CoT selection and self-prompted inference via in-context learning. Extensive experiments on four multi-hop question-answering benchmarks show that our proposed SP-CoT not only significantly surpasses the previous SOTA methods on large-scale (175B) LLMs, but also nearly doubles the zero-shot performance of small-scale (13B) LLMs. Further analysis reveals the remarkable capability of SP-CoT to elicit direct and concise intermediate reasoning steps by recalling $\sim$50\% of intermediate answers on MuSiQue-Ans dataset.
CSPRD: A Financial Policy Retrieval Dataset for Chinese Stock Market
Sep 11, 2023



In recent years, great advances in pre-trained language models (PLMs) have sparked considerable research focus and achieved promising performance on the approach of dense passage retrieval, which aims at retrieving relative passages from massive corpus with given questions. However, most of existing datasets mainly benchmark the models with factoid queries of general commonsense, while specialised fields such as finance and economics remain unexplored due to the deficiency of large-scale and high-quality datasets with expert annotations. In this work, we propose a new task, policy retrieval, by introducing the Chinese Stock Policy Retrieval Dataset (CSPRD), which provides 700+ prospectus passages labeled by experienced experts with relevant articles from 10k+ entries in our collected Chinese policy corpus. Experiments on lexical, embedding and fine-tuned bi-encoder models show the effectiveness of our proposed CSPRD yet also suggests ample potential for improvement. Our best performing baseline achieves 56.1% MRR@10, 28.5% NDCG@10, 37.5% Recall@10 and 80.6% Precision@10 on dev set.
Representation Decoupling for Open-Domain Passage Retrieval
Oct 14, 2021
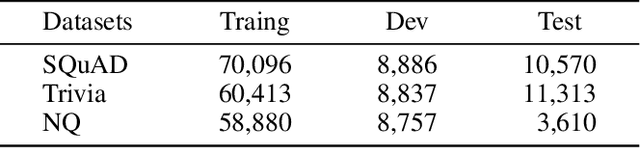
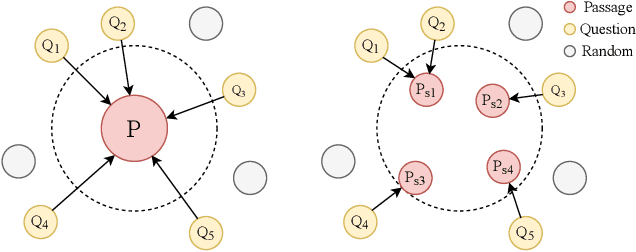

Training dense passage representations via contrastive learning (CL) has been shown effective for Open-Domain Passage Retrieval (ODPR). Recent studies mainly focus on optimizing this CL framework by improving the sampling strategy or extra pretraining. Different from previous studies, this work devotes itself to investigating the influence of conflicts in the widely used CL strategy in ODPR, motivated by our observation that a passage can be organized by multiple semantically different sentences, thus modeling such a passage as a unified dense vector is not optimal. We call such conflicts Contrastive Conflicts. In this work, we propose to solve it with a representation decoupling method, by decoupling the passage representations into contextual sentence-level ones, and design specific CL strategies to mediate these conflicts. Experiments on widely used datasets including Natural Questions, Trivia QA, and SQuAD verify the effectiveness of our method, especially on the dataset where the conflicting problem is severe. Our method also presents good transferability across the datasets, which further supports our idea of mediating Contrastive Conflicts.