 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashBlock: Attention Caching for Efficient Long-Context Block Diffusion
Feb 05, 2026Generating long-form content, such as minute-long videos and extended texts, is increasingly important for modern generative models. Block diffusion improves inference efficiency via KV caching and block-wise causal inference and has been widely adopted in diffusion language models and video generation. However, in long-context settings, block diffusion still incurs substantial overhead from repeatedly computing attention over a growing KV cache. We identify an underexplored property of block diffusion: cross-step redundancy of attention within a block. Our analysis shows that attention outputs from tokens outside the current block remain largely stable across diffusion steps, while block-internal attention varies significantly. Based on this observation, we propose FlashBlock, a cached block-external attention mechanism that reuses stable attention output, reducing attention computation and KV cache access without modifying the diffusion process. Moreover, FlashBlock is orthogonal to sparse attention and can be combined as a complementary residual reuse strategy, substantially improving model accuracy under aggressive sparsification. Experiments on diffusion language models and video generation demonstrate up to 1.44$\times$ higher token throughput and up to 1.6$\times$ reduction in attention time, with negligible impact on generation quality. Project page: https://caesarhhh.github.io/FlashBlock/.
CoV: Chain-of-View Prompting for Spatial Reasoning
Jan 08, 2026Embodied question answering (EQA) in 3D environments often requires collecting context that is distributed across multiple viewpoints and partially occluded. However, most recent vision--language models (VLMs) are constrained to a fixed and finite set of input views, which limits their ability to acquire question-relevant context at inference time and hinders complex spatial reasoning. We propose Chain-of-View (CoV) prompting, a training-free, test-time reasoning framework that transforms a VLM into an active viewpoint reasoner through a coarse-to-fine exploration process. CoV first employs a View Selection agent to filter redundant frames and identify question-aligned anchor views. It then performs fine-grained view adjustment by interleaving iterative reasoning with discrete camera actions, obtaining new observations from the underlying 3D scene representation until sufficient context is gathered or a step budget is reached. We evaluate CoV on OpenEQA across four mainstream VLMs and obtain an average +11.56\% improvement in LLM-Match, with a maximum gain of +13.62\% on Qwen3-VL-Flash. CoV further exhibits test-time scaling: increasing the minimum action budget yields an additional +2.51\% average improvement, peaking at +3.73\% on Gemini-2.5-Flash. On ScanQA and SQA3D, CoV delivers strong performance (e.g., 116 CIDEr / 31.9 EM@1 on ScanQA and 51.1 EM@1 on SQA3D). Overall, these results suggest that question-aligned view selection coupled with open-view search is an effective, model-agnostic strategy for improving spatial reasoning in 3D EQA without additional training.
Few-Step Distillation for Text-to-Image Generation: A Practical Guide
Dec 15, 2025Diffusion distillation has dramatically accelerated class-conditional image synthesis, but its applicability to open-ended text-to-image (T2I) generation is still unclear. We present the first systematic study that adapts and compares state-of-the-art distillation techniques on a strong T2I teacher model, FLUX.1-lite. By casting existing methods into a unified framework, we identify the key obstacles that arise when moving from discrete class labels to free-form language prompts. Beyond a thorough methodological analysis, we offer practical guidelines on input scaling, network architecture, and hyperparameters, accompanied by an open-source implementation and pretrained student models. Our findings establish a solid foundation for deploying fast, high-fidelity, and resource-efficient diffusion generators in real-world T2I applications. Code is available on github.com/alibaba-damo-academy/T2I-Distill.
OmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
Where and What Matters: Sensitivity-Aware Task Vectors for Many-Shot Multimodal In-Context Learning
Nov 11, 2025Large Multimodal Models (LMMs) have shown promising in-context learning (ICL) capabilities, but scaling to many-shot settings remains difficult due to limited context length and high inference cost. To address these challenges, task-vector-based methods have been explored by inserting compact representations of many-shot in-context demonstrations into model activations. However, existing task-vector-based methods either overlook the importance of where to insert task vectors or struggle to determine suitable values for each location. To this end, we propose a novel Sensitivity-aware Task Vector insertion framework (STV) to figure out where and what to insert. Our key insight is that activation deltas across query-context pairs exhibit consistent structural patterns, providing a reliable cue for insertion. Based on the identified sensitive-aware locations, we construct a pre-clustered activation bank for each location by clustering the activation values, and then apply reinforcement learning to choose the most suitable one to insert. We evaluate STV across a range of multimodal models (e.g., Qwen-VL, Idefics-2) and tasks (e.g., VizWiz, OK-VQA), demonstrating its effectiveness and showing consistent improvements over previous task-vector-based methods with strong generalization.
RAPID^3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformer
Sep 26, 2025Diffusion Transformers (DiTs) excel at visual generation yet remain hampered by slow sampling. Existing training-free accelerators - step reduction, feature caching, and sparse attention - enhance inference speed but typically rely on a uniform heuristic or a manually designed adaptive strategy for all images, leaving quality on the table. Alternatively, dynamic neural networks offer per-image adaptive acceleration, but their high fine-tuning costs limit broader applicability. To address these limitations, we introduce RAPID3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformers, a framework that delivers image-wise acceleration with zero updates to the base generator. Specifically, three lightweight policy heads - Step-Skip, Cache-Reuse, and Sparse-Attention - observe the current denoising state and independently decide their corresponding speed-up at each timestep. All policy parameters are trained online via Group Relative Policy Optimization (GRPO) while the generator remains frozen. Meanwhile, an adversarially learned discriminator augments the reward signal, discouraging reward hacking by boosting returns only when generated samples stay close to the original model's distribution. Across state-of-the-art DiT backbones, including Stable Diffusion 3 and FLUX, RAPID3 achieves nearly 3x faster sampling with competitive generation quality.
Frequency-Aware Autoregressive Modeling for Efficient High-Resolution Image Synthesis
Jul 28, 2025
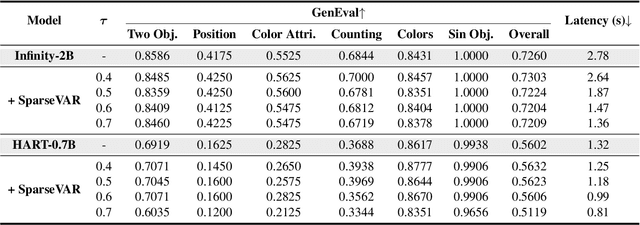


Visual autoregressive modeling, based on the next-scale prediction paradigm, exhibits notable advantages in image quality and model scalability over traditional autoregressive and diffusion models. It generates images by progressively refining resolution across multiple stages. However, the computational overhead in high-resolution stages remains a critical challenge due to the substantial number of tokens involved. In this paper, we introduce SparseVAR, a plug-and-play acceleration framework for next-scale prediction that dynamically excludes low-frequency tokens during inference without requiring additional training. Our approach is motivated by the observation that tokens in low-frequency regions have a negligible impact on image quality in high-resolution stages and exhibit strong similarity with neighboring tokens. Additionally, we observe that different blocks in the next-scale prediction model focus on distinct regions, with some concentrating on high-frequency areas. SparseVAR leverages these insights by employing lightweight MSE-based metrics to identify low-frequency tokens while preserving the fidelity of excluded regions through a small set of uniformly sampled anchor tokens. By significantly reducing the computational cost while maintaining high image generation quality, SparseVAR achieves notable acceleration in both HART and Infinity. Specifically, SparseVAR achieves up to a 2 times speedup with minimal quality degradation in Infinity-2B.
R-Stitch: Dynamic Trajectory Stitching for Efficient Reasoning
Jul 23, 2025Chain-of-thought (CoT) reasoning enhances the problem-solving capabilities of large language models by encouraging step-by-step intermediate reasoning during inference. While effective, CoT introduces substantial computational overhead due to its reliance on autoregressive decoding over long token sequences. Existing acceleration strategies either reduce sequence length through early stopping or compressive reward designs, or improve decoding speed via speculative decoding with smaller models. However, speculative decoding suffers from limited speedup when the agreement between small and large models is low, and fails to exploit the potential advantages of small models in producing concise intermediate reasoning. In this paper, we present R-Stitch, a token-level, confidence-based hybrid decoding framework that accelerates CoT inference by switching between a small language model (SLM) and a large language model (LLM) along the reasoning trajectory. R-Stitch uses the SLM to generate tokens by default and delegates to the LLM only when the SLM's confidence falls below a threshold. This design avoids full-sequence rollback and selectively invokes the LLM on uncertain steps, preserving both efficiency and answer quality. R-Stitch is model-agnostic, training-free, and compatible with standard decoding pipelines. Experiments on math reasoning benchmarks demonstrate that R-Stitch achieves up to 85\% reduction in inference latency with negligible accuracy drop, highlighting its practical effectiveness in accelerating CoT reasoning.
FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
Jun 06, 2025Diffusion generative models have become the standard for producing high-quality, coherent video content, yet their slow inference speeds and high computational demands hinder practical deployment. Although both quantization and sparsity can independently accelerate inference while maintaining generation quality, naively combining these techniques in existing training-free approaches leads to significant performance degradation due to the lack of joint optimization. We introduce FPSAttention, a novel training-aware co-design of FP8 quantization and sparsity for video generation, with a focus on the 3D bi-directional attention mechanism. Our approach features three key innovations: 1) A unified 3D tile-wise granularity that simultaneously supports both quantization and sparsity; 2) A denoising step-aware strategy that adapts to the noise schedule, addressing the strong correlation between quantization/sparsity errors and denoising steps; 3) A native, hardware-friendly kernel that leverages FlashAttention and is implemented with optimized Hopper architecture features for highly efficient execution. Trained on Wan2.1's 1.3B and 14B models and evaluated on the VBench benchmark, FPSAttention achieves a 7.09x kernel speedup for attention operations and a 4.96x end-to-end speedup for video generation compared to the BF16 baseline at 720p resolution-without sacrificing generation quality.
Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting
Jun 05, 2025Depth maps are widely used in feed-forward 3D Gaussian Splatting (3DGS) pipelines by unprojecting them into 3D point clouds for novel view synthesis. This approach offers advantages such as efficient training, the use of known camera poses, and accurate geometry estimation. However, depth discontinuities at object boundaries often lead to fragmented or sparse point clouds, degrading rendering quality -- a well-known limitation of depth-based representations. To tackle this issue, we introduce PM-Loss, a novel regularization loss based on a pointmap predicted by a pre-trained transformer. Although the pointmap itself may be less accurate than the depth map, it effectively enforces geometric smoothness, especially around object boundaries. With the improved depth map, our method significantly improves the feed-forward 3DGS across various architectures and scenes, delivering consistently better rendering results. Our project page: https://aim-uofa.github.io/PMLoss