 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Reward Uncertainty to Induce Diverse Behaviour in Reinforcement Learning
Jun 02, 2026Classical reinforcement learning (RL) typically seeks a deterministic policy that maximizes the expected sum of a scalar reward. Yet, modern applications such as language model fine-tuning or scientific discovery demand diversity. Existing remedies such as entropy regularization or diversity bonuses often require fragile trade-offs that sacrifice performance for stochasticity or rely on heuristic metrics that can misalign policy rankings. We argue that diversity is more naturally understood as the rational response to uncertainty in the reward. When the reward function is not perfectly known--as is the case with ambiguous preferences or imperfect reward models--committing to a single action can be sub-optimal. Building on this, we propose a fundamental reformulation of the RL objective by replacing the scalar reward with a distribution over reward functions, and applying a non-linear objective over sets of actions. The result is a framework in which calibrated behavioural diversity emerges naturally, remains controllable through the reward function distribution, and is obtained without sacrificing expected reward. Focusing on the contextual bandit setting, we derive a principled gradient estimator for this objective and prove that our formulation naturally generalizes both vanilla policy gradient and more recently developed action-set approaches. Our empirical results demonstrate that this framework offers a robust and theoretically grounded alternative for complex RL tasks where the traditional formulation of the problem fails to induce the desired breadth of agent behaviour.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Constructing an Optimal Behavior Basis for the Option Keyboard
May 01, 2025Multi-task reinforcement learning aims to quickly identify solutions for new tasks with minimal or no additional interaction with the environment. Generalized Policy Improvement (GPI) addresses this by combining a set of base policies to produce a new one that is at least as good -- though not necessarily optimal -- as any individual base policy. Optimality can be ensured, particularly in the linear-reward case, via techniques that compute a Convex Coverage Set (CCS). However, these are computationally expensive and do not scale to complex domains. The Option Keyboard (OK) improves upon GPI by producing policies that are at least as good -- and often better. It achieves this through a learned meta-policy that dynamically combines base policies. However, its performance critically depends on the choice of base policies. This raises a key question: is there an optimal set of base policies -- an optimal behavior basis -- that enables zero-shot identification of optimal solutions for any linear tasks? We solve this open problem by introducing a novel method that efficiently constructs such an optimal behavior basis. We show that it significantly reduces the number of base policies needed to ensure optimality in new tasks. We also prove that it is strictly more expressive than a CCS, enabling particular classes of non-linear tasks to be solved optimally. We empirically evaluate our technique in challenging domains and show that it outperforms state-of-the-art approaches, increasingly so as task complexity increases.
Capturing Individual Human Preferences with Reward Features
Mar 21, 2025



Reinforcement learning from human feedback usually models preferences using a reward model that does not distinguish between people. We argue that this is unlikely to be a good design choice in contexts with high potential for disagreement, like in the training of large language models. We propose a method to specialise a reward model to a person or group of people. Our approach builds on the observation that individual preferences can be captured as a linear combination of a set of general reward features. We show how to learn such features and subsequently use them to quickly adapt the reward model to a specific individual, even if their preferences are not reflected in the training data. We present experiments with large language models comparing the proposed architecture with a non-adaptive reward model and also adaptive counterparts, including models that do in-context personalisation. Depending on how much disagreement there is in the training data, our model either significantly outperforms the baselines or matches their performance with a simpler architecture and more stable training.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
A Distributional Analogue to the Successor Representation
Feb 13, 2024



This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
On the Convergence of Bounded Agents
Jul 20, 2023When has an agent converged? Standard models of the reinforcement learning problem give rise to a straightforward definition of convergence: An agent converges when its behavior or performance in each environment state stops changing. However, as we shift the focus of our learning problem from the environment's state to the agent's state, the concept of an agent's convergence becomes significantly less clear. In this paper, we propose two complementary accounts of agent convergence in a framing of the reinforcement learning problem that centers around bounded agents. The first view says that a bounded agent has converged when the minimal number of states needed to describe the agent's future behavior cannot decrease. The second view says that a bounded agent has converged just when the agent's performance only changes if the agent's internal state changes. We establish basic properties of these two definitions, show that they accommodate typical views of convergence in standard settings, and prove several facts about their nature and relationship. We take these perspectives, definitions, and analysis to bring clarity to a central idea of the field.
A Definition of Continual Reinforcement Learning
Jul 20, 2023In this paper we develop a foundation for continual reinforcement learning.
Deep Reinforcement Learning with Plasticity Injection
May 24, 2023A growing body of evidence suggests that neural networks employed in deep reinforcement learning (RL) gradually lose their plasticity, the ability to learn from new data; however, the analysis and mitigation of this phenomenon is hampered by the complex relationship between plasticity, exploration, and performance in RL. This paper introduces plasticity injection, a minimalistic intervention that increases the network plasticity without changing the number of trainable parameters or biasing the predictions. The applications of this intervention are two-fold: first, as a diagnostic tool $\unicode{x2014}$ if injection increases the performance, we may conclude that an agent's network was losing its plasticity. This tool allows us to identify a subset of Atari environments where the lack of plasticity causes performance plateaus, motivating future studies on understanding and combating plasticity loss. Second, plasticity injection can be used to improve the computational efficiency of RL training if the agent has to re-learn from scratch due to exhausted plasticity or by growing the agent's network dynamically without compromising performance. The results on Atari show that plasticity injection attains stronger performance compared to alternative methods while being computationally efficient.
Generalised Policy Improvement with Geometric Policy Composition
Jun 17, 2022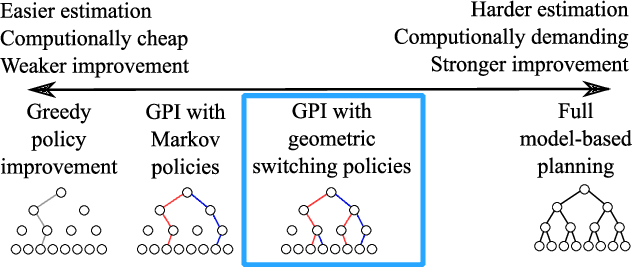

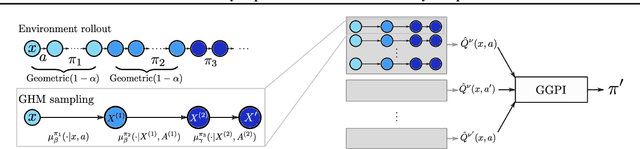
We introduce a method for policy improvement that interpolates between the greedy approach of value-based reinforcement learning (RL) and the full planning approach typical of model-based RL. The new method builds on the concept of a geometric horizon model (GHM, also known as a gamma-model), which models the discounted state-visitation distribution of a given policy. We show that we can evaluate any non-Markov policy that switches between a set of base Markov policies with fixed probability by a careful composition of the base policy GHMs, without any additional learning. We can then apply generalised policy improvement (GPI) to collections of such non-Markov policies to obtain a new Markov policy that will in general outperform its precursors. We provide a thorough theoretical analysis of this approach, develop applications to transfer and standard RL, and empirically demonstrate its effectiveness over standard GPI on a challenging deep RL continuous control task. We also provide an analysis of GHM training methods, proving a novel convergence result regarding previously proposed methods and showing how to train these models stably in deep RL settings.