 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainFusionNet: a deep learning and XAI model to understand local, global, and sequential features of MRI images for improved brain tumour detection
Jun 17, 2026The noise of Magnetic Resonance Imaging MRI poses challenges for Deep Learning DL when tumor boundaries are obscured tumor location and appearance are complex Therefore we develop BrainFusionNet that combines Convolutional Neural Networks CNNs Vision Transformers ViT and Gated Recurrent Units GRUs to extract spatial contextual and sequential features from MRI images for improved brain tumor classification Furthermore explainable AI such as SHAP LIME and GradCAM are integrated to visualise and highlight image regions that contribute to BrainFusionNets decisionmaking process The proposed BrainFusionNet model is evaluated on two publicly available MRI datasets Kfold validation suggests 98 accuracy on both datasets The model was compared with the six stateoftheart SOTA CNNs and transfer learning Among the SOTA CNNs DenseNet121 and VGG16 achieved the highest accuracy of 96 The novelty of BrainFusionNet is that the hybrid model effectively extracts local and global features from MRI images even in smallscale tumor regions and small tumor sizes The model has a balanced sequential CNN architecture to capture lowlevel and deeperlayer features a customized ViT that captures local features stabilizes gradient flow and reduces the risk of vanishing gradients during MRI image training The CNN and ViT outputs are fed into a GRU for final classification Furthermore we analyze pixel intensities to determine whether MRI image quality affects image classification Our findings are very novel in image interpretation as we found that the distribution of pixel intensities in MRI images affects DL performance
Enhancing 3D Semantic Scene Completion with a Refinement Module
Dec 20, 2025



We propose ESSC-RM, a plug-and-play Enhancing framework for Semantic Scene Completion with a Refinement Module, which can be seamlessly integrated into existing SSC models. ESSC-RM operates in two phases: a baseline SSC network first produces a coarse voxel prediction, which is subsequently refined by a 3D U-Net-based Prediction Noise-Aware Module (PNAM) and Voxel-level Local Geometry Module (VLGM) under multiscale supervision. Experiments on SemanticKITTI show that ESSC-RM consistently improves semantic prediction performance. When integrated into CGFormer and MonoScene, the mean IoU increases from 16.87% to 17.27% and from 11.08% to 11.51%, respectively. These results demonstrate that ESSC-RM serves as a general refinement framework applicable to a wide range of SSC models.
A comprehensive study on Blood Cancer detection and classification using Convolutional Neural Network
Sep 10, 2024Over the years in object detection several efficient Convolutional Neural Networks (CNN) networks, such as DenseNet201, InceptionV3, ResNet152v2, SEresNet152, VGG19, Xception gained significant attention due to their performance. Moreover, CNN paradigms have expanded to transfer learning and ensemble models from original CNN architectures. Research studies suggest that transfer learning and ensemble models are capable of increasing the accuracy of deep learning (DL) models. However, very few studies have conducted comprehensive experiments utilizing these techniques in detecting and localizing blood malignancies. Realizing the gap, this study conducted three experiments; in the first experiment -- six original CNNs were used, in the second experiment -- transfer learning and, in the third experiment a novel ensemble model DIX (DenseNet201, InceptionV3, and Xception) was developed to detect and classify blood cancer. The statistical result suggests that DIX outperformed the original and transfer learning performance, providing an accuracy of 99.12%. However, this study also provides a negative result in the case of transfer learning, as the transfer learning did not increase the accuracy of the original CNNs. Like many other cancers, blood cancer diseases require timely identification for effective treatment plans and increased survival possibilities. The high accuracy in detecting and categorization blood cancer detection using CNN suggests that the CNN model is promising in blood cancer disease detection. This research is significant in the fields of biomedical engineering, computer-aided disease diagnosis, and ML-based disease detection.
Automating the Training and Deployment of Models in MLOps by Integrating Systems with Machine Learning
May 16, 2024



This article introduces the importance of machine learning in real-world applications and explores the rise of MLOps (Machine Learning Operations) and its importance for solving challenges such as model deployment and performance monitoring. By reviewing the evolution of MLOps and its relationship to traditional software development methods, the paper proposes ways to integrate the system into machine learning to solve the problems faced by existing MLOps and improve productivity. This paper focuses on the importance of automated model training, and the method to ensure the transparency and repeatability of the training process through version control system. In addition, the challenges of integrating machine learning components into traditional CI/CD pipelines are discussed, and solutions such as versioning environments and containerization are proposed. Finally, the paper emphasizes the importance of continuous monitoring and feedback loops after model deployment to maintain model performance and reliability. Using case studies and best practices from Netflix, the article presents key strategies and lessons learned for successful implementation of MLOps practices, providing valuable references for other organizations to build and optimize their own MLOps practices.
ViTCN: Vision Transformer Contrastive Network For Reasoning
Mar 15, 2024


Machine learning models have achieved significant milestones in various domains, for example, computer vision models have an exceptional result in object recognition, and in natural language processing, where Large Language Models (LLM) like GPT can start a conversation with human-like proficiency. However, abstract reasoning remains a challenge for these models, Can AI really thinking like a human? still be a question yet to be answered. Raven Progressive Matrices (RPM) is a metric designed to assess human reasoning capabilities. It presents a series of eight images as a problem set, where the participant should try to discover the underlying rules among these images and select the most appropriate image from eight possible options that best completes the sequence. This task always be used to test human reasoning abilities and IQ. Zhang et al proposed a dataset called RAVEN which can be used to test Machine Learning model abstract reasoning ability. In this paper, we purposed Vision Transformer Contrastive Network which build on previous work with the Contrastive Perceptual Inference network (CoPiNet), which set a new benchmark for permutationinvariant models Raven Progressive Matrices by incorporating contrast effects from psychology, cognition, and education, and extends this foundation by leveraging the cutting-edge Vision Transformer architecture. This integration aims to further refine the machine ability to process and reason about spatial-temporal information from pixel-level inputs and global wise features on RAVEN dataset.
CircleFormer: Circular Nuclei Detection in Whole Slide Images with Circle Queries and Attention
Aug 31, 2023



Both CNN-based and Transformer-based object detection with bounding box representation have been extensively studied in computer vision and medical image analysis, but circular object detection in medical images is still underexplored. Inspired by the recent anchor free CNN-based circular object detection method (CircleNet) for ball-shape glomeruli detection in renal pathology, in this paper, we present CircleFormer, a Transformer-based circular medical object detection with dynamic anchor circles. Specifically, queries with circle representation in Transformer decoder iteratively refine the circular object detection results, and a circle cross attention module is introduced to compute the similarity between circular queries and image features. A generalized circle IoU (gCIoU) is proposed to serve as a new regression loss of circular object detection as well. Moreover, our approach is easy to generalize to the segmentation task by adding a simple segmentation branch to CircleFormer. We evaluate our method in circular nuclei detection and segmentation on the public MoNuSeg dataset, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well. Our code is released at https://github.com/zhanghx-iim-ahu/CircleFormer.
BadLabel: A Robust Perspective on Evaluating and Enhancing Label-noise Learning
May 28, 2023Label-noise learning (LNL) aims to increase the model's generalization given training data with noisy labels. To facilitate practical LNL algorithms, researchers have proposed different label noise types, ranging from class-conditional to instance-dependent noises. In this paper, we introduce a novel label noise type called BadLabel, which can significantly degrade the performance of existing LNL algorithms by a large margin. BadLabel is crafted based on the label-flipping attack against standard classification, where specific samples are selected and their labels are flipped to other labels so that the loss values of clean and noisy labels become indistinguishable. To address the challenge posed by BadLabel, we further propose a robust LNL method that perturbs the labels in an adversarial manner at each epoch to make the loss values of clean and noisy labels again distinguishable. Once we select a small set of (mostly) clean labeled data, we can apply the techniques of semi-supervised learning to train the model accurately. Empirically, our experimental results demonstrate that existing LNL algorithms are vulnerable to the newly introduced BadLabel noise type, while our proposed robust LNL method can effectively improve the generalization performance of the model under various types of label noise. The new dataset of noisy labels and the source codes of robust LNL algorithms are available at https://github.com/zjfheart/BadLabels.
Relay Hindsight Experience Replay: Continual Reinforcement Learning for Robot Manipulation Tasks with Sparse Rewards
Aug 01, 2022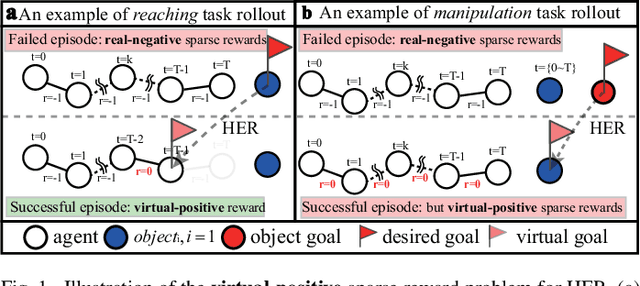
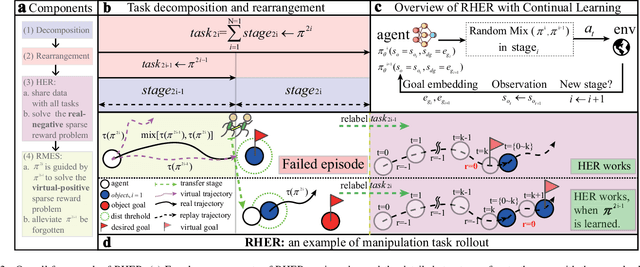
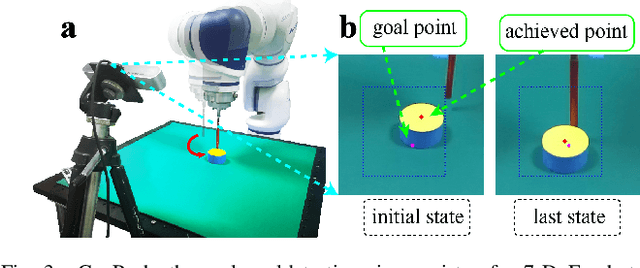
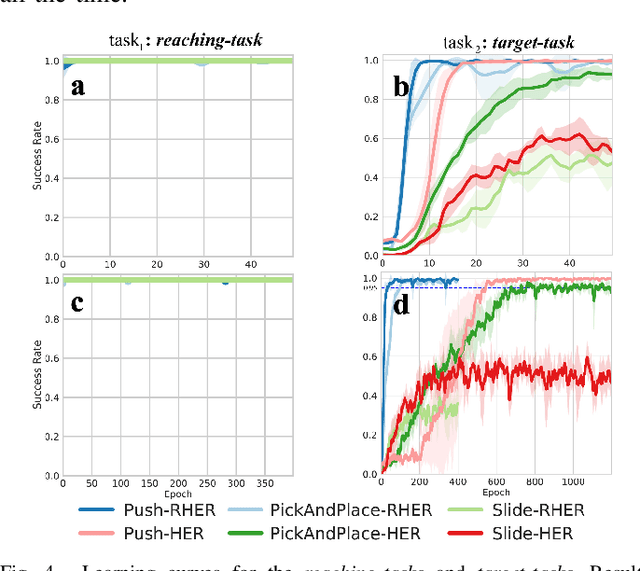
Learning with sparse rewards is usually inefficient in Reinforcement Learning (RL). Hindsight Experience Replay (HER) has been shown an effective solution to handle the low sample efficiency that results from sparse rewards by goal relabeling. However, the HER still has an implicit virtual-positive sparse reward problem caused by invariant achieved goals, especially for robot manipulation tasks. To solve this problem, we propose a novel model-free continual RL algorithm, called Relay-HER (RHER). The proposed method first decomposes and rearranges the original long-horizon task into new sub-tasks with incremental complexity. Subsequently, a multi-task network is designed to learn the sub-tasks in ascending order of complexity. To solve the virtual-positive sparse reward problem, we propose a Random-Mixed Exploration Strategy (RMES), in which the achieved goals of the sub-task with higher complexity are quickly changed under the guidance of the one with lower complexity. The experimental results indicate the significant improvements in sample efficiency of RHER compared to vanilla-HER in five typical robot manipulation tasks, including Push, PickAndPlace, Drawer, Insert, and ObstaclePush. The proposed RHER method has also been applied to learn a contact-rich push task on a physical robot from scratch, and the success rate reached 10/10 with only 250 episodes.
SMPL: Simulated Industrial Manufacturing and Process Control Learning Environments
Jun 17, 2022
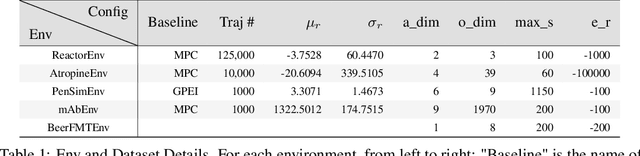
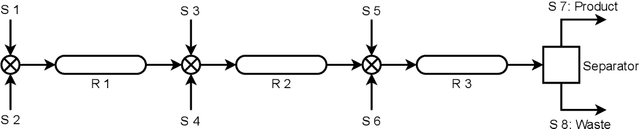
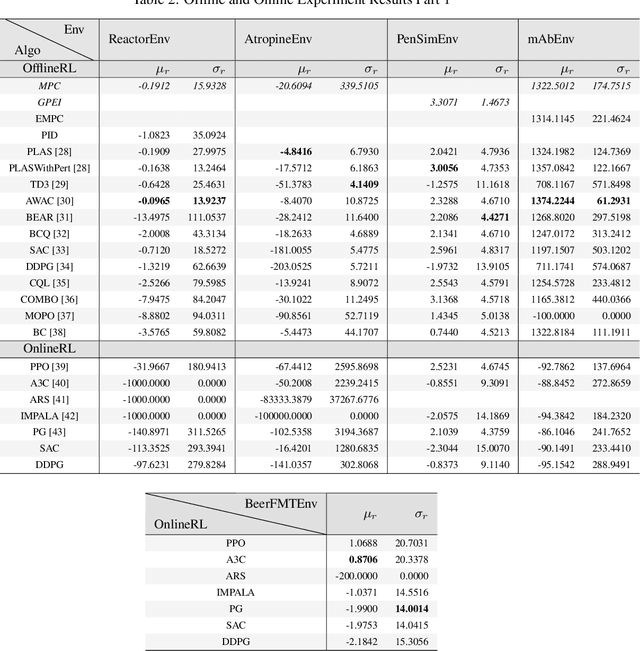
Traditional biological and pharmaceutical manufacturing plants are controlled by human workers or pre-defined thresholds. Modernized factories have advanced process control algorithms such as model predictive control (MPC). However, there is little exploration of applying deep reinforcement learning to control manufacturing plants. One of the reasons is the lack of high fidelity simulations and standard APIs for benchmarking. To bridge this gap, we develop an easy-to-use library that includes five high-fidelity simulation environments: BeerFMTEnv, ReactorEnv, AtropineEnv, PenSimEnv and mAbEnv, which cover a wide range of manufacturing processes. We build these environments on published dynamics models. Furthermore, we benchmark online and offline, model-based and model-free reinforcement learning algorithms for comparisons of follow-up research.
Balance Between Efficient and Effective Learning: Dense2Sparse Reward Shaping for Robot Manipulation with Environment Uncertainty
Mar 05, 2020
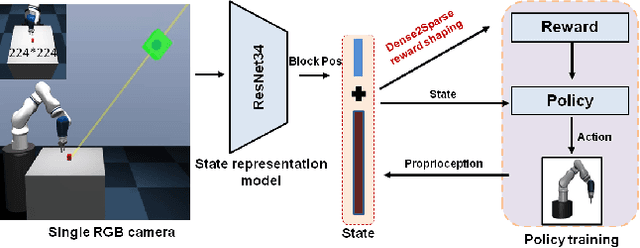
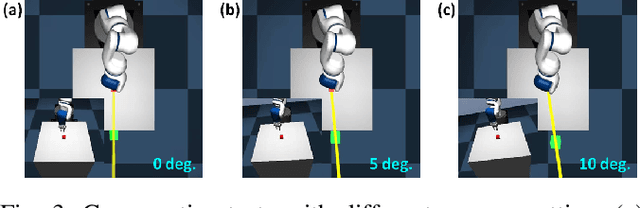
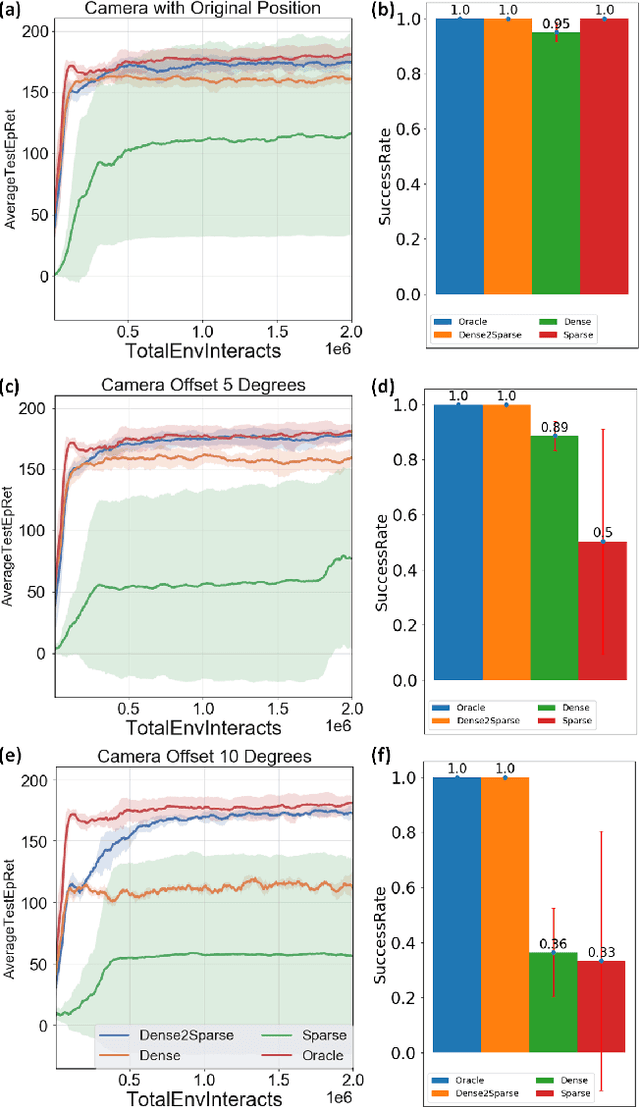
Efficient and effective learning is one of the ultimate goals of the deep reinforcement learning (DRL), although the compromise has been made in most of the time, especially for the application of robot manipulations. Learning is always expensive for robot manipulation tasks and the learning effectiveness could be affected by the system uncertainty. In order to solve above challenges, in this study, we proposed a simple but powerful reward shaping method, namely Dense2Sparse. It combines the advantage of fast convergence of dense reward and the noise isolation of the sparse reward, to achieve a balance between learning efficiency and effectiveness, which makes it suitable for robot manipulation tasks. We evaluated our Dense2Sparse method with a series of ablation experiments using the state representation model with system uncertainty. The experiment results show that the Dense2Sparse method obtained higher expected reward compared with the ones using standalone dense reward or sparse reward, and it also has a superior tolerance of system uncertainty.