 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecializing Large Models for Oracle Bone Script Interpretation via Component-Grounded Multimodal Knowledge Augmentation
Apr 08, 2026Deciphering ancient Chinese Oracle Bone Script (OBS) is a challenging task that offers insights into the beliefs, systems, and culture of the ancient era. Existing approaches treat decipherment as a closed-set image recognition problem, which fails to bridge the ``interpretation gap'': while individual characters are often unique and rare, they are composed of a limited set of recurring, pictographic components that carry transferable semantic meanings. To leverage this structural logic, we propose an agent-driven Vision-Language Model (VLM) framework that integrates a VLM for precise visual grounding with an LLM-based agent to automate a reasoning chain of component identification, graph-based knowledge retrieval, and relationship inference for linguistically accurate interpretation. To support this, we also introduce OB-Radix, an expert-annotated dataset providing structural and semantic data absent from prior corpora, comprising 1,022 character images (934 unique characters) and 1,853 fine-grained component images across 478 distinct components with verified explanations. By evaluating our system across three benchmarks of different tasks, we demonstrate that our framework yields more detailed and precise decipherments compared to baseline methods.
FastTurn: Unifying Acoustic and Streaming Semantic Cues for Low-Latency and Robust Turn Detection
Apr 07, 2026Recent advances in AudioLLMs have enabled spoken dialogue systems to move beyond turn-based interaction toward real-time full-duplex communication, where the agent must decide when to speak, yield, or interrupt while the user is still talking. Existing full-duplex approaches either rely on voice activity cues, which lack semantic understanding, or on ASR-based modules, which introduce latency and degrade under overlapping speech and noise. Moreover, available datasets rarely capture realistic interaction dynamics, limiting evaluation and deployment. To mitigate the problem, we propose \textbf{FastTurn}, a unified framework for low-latency and robust turn detection. To advance latency while maintaining performance, FastTurn combines streaming CTC decoding with acoustic features, enabling early decisions from partial observations while preserving semantic cues. We also release a test set based on real human dialogue, capturing authentic turn transitions, overlapping speech, backchannels, pauses, pitch variation, and environmental noise. Experiments show FastTurn achieves higher decision accuracy with lower interruption latency than representative baselines and remains robust under challenging acoustic conditions, demonstrating its effectiveness for practical full-duplex dialogue systems.
Photorealistic Lip Sync with Adversarial Temporal Convolutional Networks
Feb 20, 2020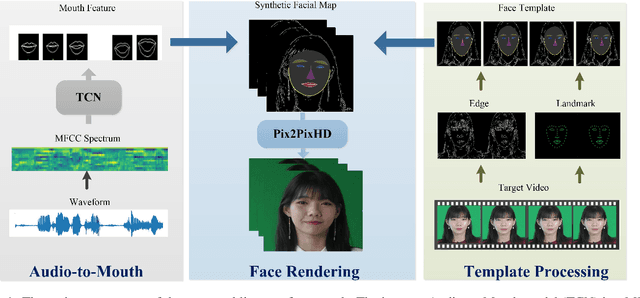

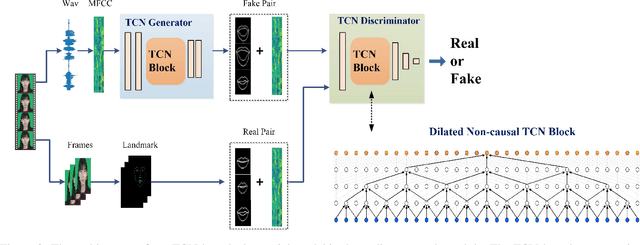

Lip sync has emerged as a promising technique to generate mouth movements on a talking head. However, synthesizing a clear, accurate and human-like performance is still challenging. In this paper, we present a novel lip-sync solution for producing a high-quality and photorealistic talking head from speech. We focus on capturing the specific lip movement and talking style of the target person. We model the seq-to-seq mapping from audio signals to mouth features by two adversarial temporal convolutional networks. Experiments show our model outperforms traditional RNN-based baselines in both accuracy and speed. We also propose an image-to-image translation-based approach for generating high-resolution photoreal face appearance from synthetic facial maps. This fully-trainable framework not only avoids the cumbersome steps like candidate-frame selection in graphics-based rendering methods but also solves some existing issues in recent neural network-based solutions. Our work will benefit related applications such as conversational agent, virtual anchor, tele-presence and gaming.