 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGivens Coordinate Descent Methods for Rotation Matrix Learning in Trainable Embedding Indexes
Mar 09, 2022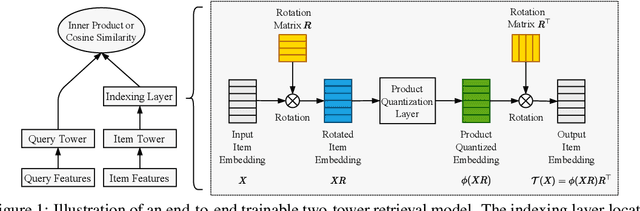
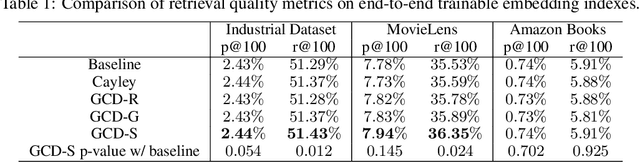
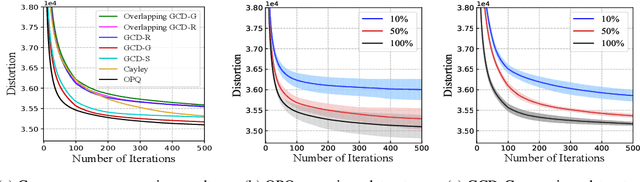
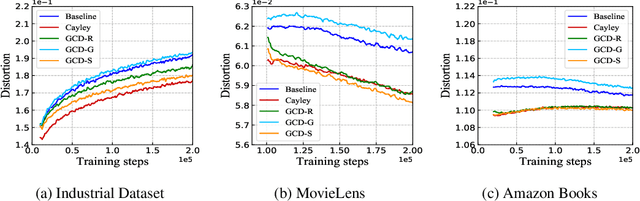
Product quantization (PQ) coupled with a space rotation, is widely used in modern approximate nearest neighbor (ANN) search systems to significantly compress the disk storage for embeddings and speed up the inner product computation. Existing rotation learning methods, however, minimize quantization distortion for fixed embeddings, which are not applicable to an end-to-end training scenario where embeddings are updated constantly. In this paper, based on geometric intuitions from Lie group theory, in particular the special orthogonal group $SO(n)$, we propose a family of block Givens coordinate descent algorithms to learn rotation matrix that are provably convergent on any convex objectives. Compared to the state-of-the-art SVD method, the Givens algorithms are much more parallelizable, reducing runtime by orders of magnitude on modern GPUs, and converge more stably according to experimental studies. They further improve upon vanilla product quantization significantly in an end-to-end training scenario.
* published in ICLR 2022
Feeding What You Need by Understanding What You Learned
Mar 05, 2022

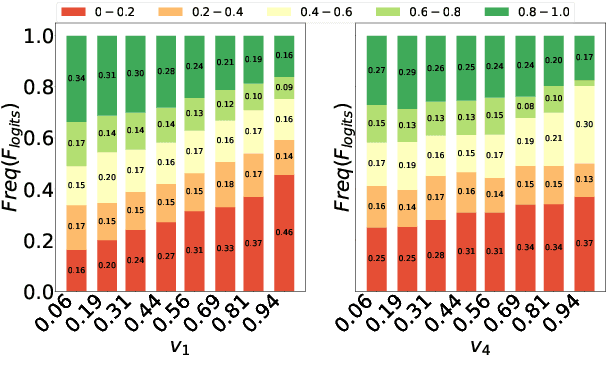
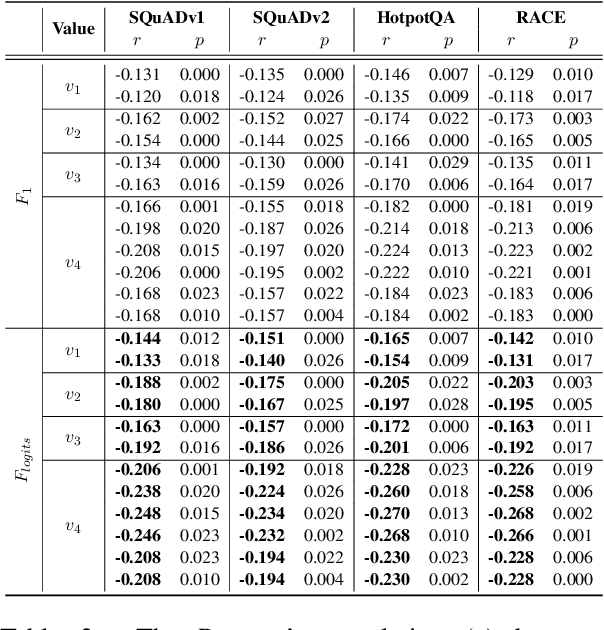
Machine Reading Comprehension (MRC) reveals the ability to understand a given text passage and answer questions based on it. Existing research works in MRC rely heavily on large-size models and corpus to improve the performance evaluated by metrics such as Exact Match ($EM$) and $F_1$. However, such a paradigm lacks sufficient interpretation to model capability and can not efficiently train a model with a large corpus. In this paper, we argue that a deep understanding of model capabilities and data properties can help us feed a model with appropriate training data based on its learning status. Specifically, we design an MRC capability assessment framework that assesses model capabilities in an explainable and multi-dimensional manner. Based on it, we further uncover and disentangle the connections between various data properties and model performance. Finally, to verify the effectiveness of the proposed MRC capability assessment framework, we incorporate it into a curriculum learning pipeline and devise a Capability Boundary Breakthrough Curriculum (CBBC) strategy, which performs a model capability-based training to maximize the data value and improve training efficiency. Extensive experiments demonstrate that our approach significantly improves performance, achieving up to an 11.22% / 8.71% improvement of $EM$ / $F_1$ on MRC tasks.
Sequential Search with Off-Policy Reinforcement Learning
Feb 01, 2022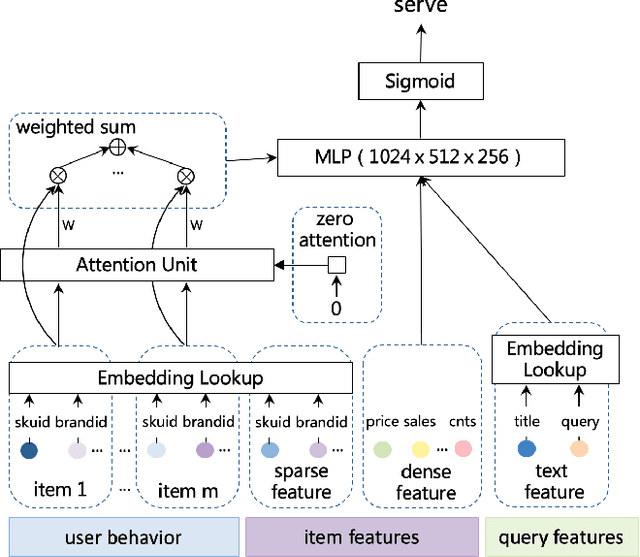
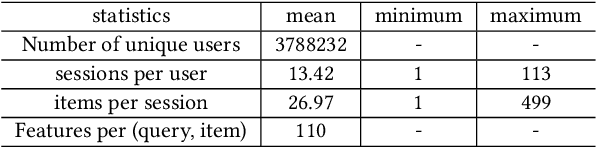
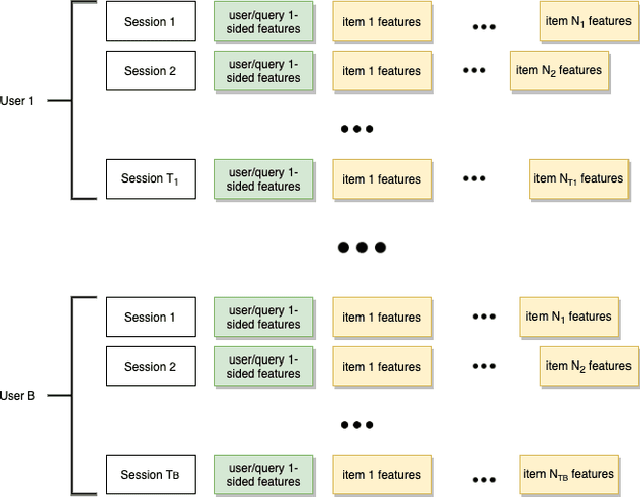
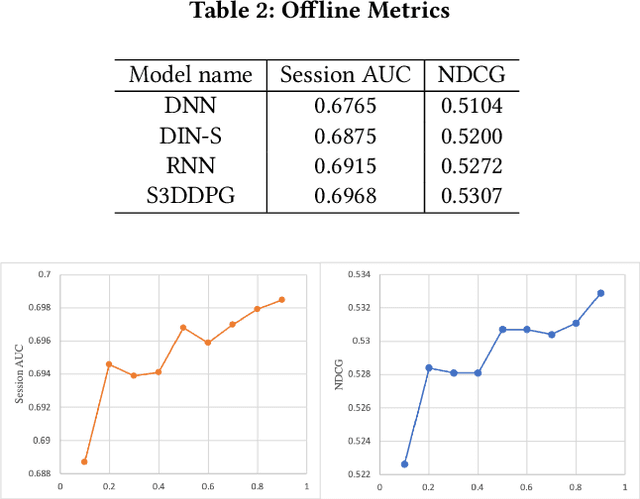
Recent years have seen a significant amount of interests in Sequential Recommendation (SR), which aims to understand and model the sequential user behaviors and the interactions between users and items over time. Surprisingly, despite the huge success Sequential Recommendation has achieved, there is little study on Sequential Search (SS), a twin learning task that takes into account a user's current and past search queries, in addition to behavior on historical query sessions. The SS learning task is even more important than the counterpart SR task for most of E-commence companies due to its much larger online serving demands as well as traffic volume. To this end, we propose a highly scalable hybrid learning model that consists of an RNN learning framework leveraging all features in short-term user-item interactions, and an attention model utilizing selected item-only features from long-term interactions. As a novel optimization step, we fit multiple short user sequences in a single RNN pass within a training batch, by solving a greedy knapsack problem on the fly. Moreover, we explore the use of off-policy reinforcement learning in multi-session personalized search ranking. Specifically, we design a pairwise Deep Deterministic Policy Gradient model that efficiently captures users' long term reward in terms of pairwise classification error. Extensive ablation experiments demonstrate significant improvement each component brings to its state-of-the-art baseline, on a variety of offline and online metrics.
Multi-Choice Questions based Multi-Interest Policy Learning for Conversational Recommendation
Dec 22, 2021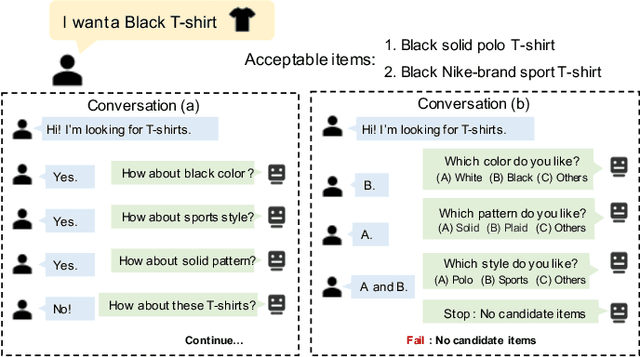
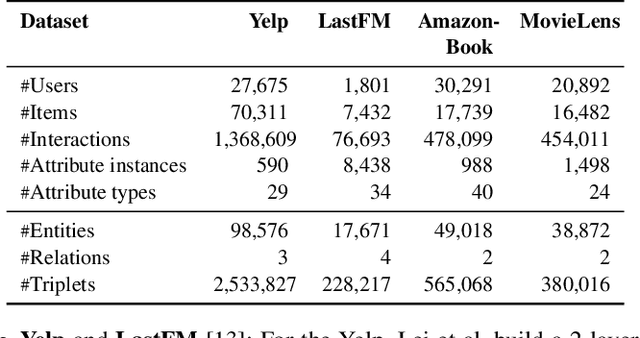
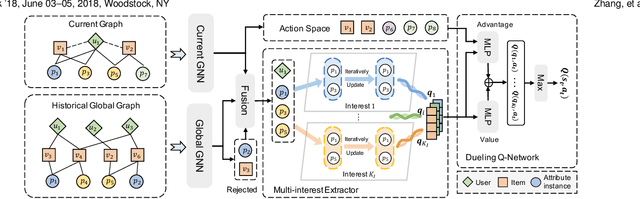
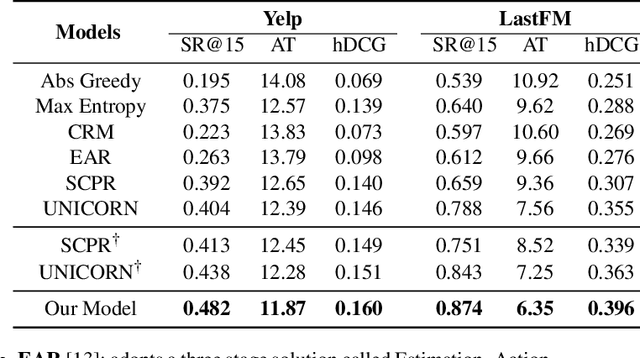
Conversational recommendation system (CRS) is able to obtain fine-grained and dynamic user preferences based on interactive dialogue. Previous CRS assumes that the user has a clear target item. However, for many users who resort to CRS, they might not have a clear idea about what they really like. Specifically, the user may have a clear single preference for some attribute types (e.g. color) of items, while for other attribute types, the user may have multiple preferences or even no clear preferences, which leads to multiple acceptable attribute instances (e.g. black and red) of one attribute type. Therefore, the users could show their preferences over items under multiple combinations of attribute instances rather than a single item with unique combination of all attribute instances. As a result, we first propose a more realistic CRS learning setting, namely Multi-Interest Multi-round Conversational Recommendation, where users may have multiple interests in attribute instance combinations and accept multiple items with partially overlapped combinations of attribute instances. To effectively cope with the new CRS learning setting, in this paper, we propose a novel learning framework namely, Multi-Choice questions based Multi-Interest Policy Learning . In order to obtain user preferences more efficiently, the agent generates multi-choice questions rather than binary yes/no ones on specific attribute instance. Besides, we propose a union set strategy to select candidate items instead of existing intersection set strategy in order to overcome over-filtering items during the conversation. Finally, we design a Multi-Interest Policy Learning module, which utilizes captured multiple interests of the user to decide next action, either asking attribute instances or recommending items. Extensive experimental results on four datasets verify the superiority of our method for the proposed setting.
Intelligent Online Selling Point Extraction for E-Commerce Recommendation
Dec 16, 2021


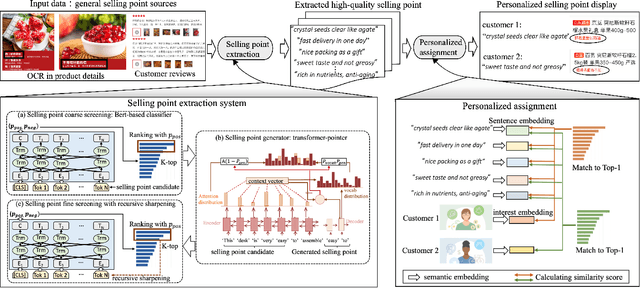
In the past decade, automatic product description generation for e-commerce have witnessed significant advancement. As the services provided by e-commerce platforms become diverse, it is necessary to dynamically adapt the patterns of descriptions generated. The selling point of products is an important type of product description for which the length should be as short as possible while still conveying key information. In addition, this kind of product description should be eye-catching to the readers. Currently, product selling points are normally written by human experts. Thus, the creation and maintenance of these contents incur high costs. These costs can be significantly reduced if product selling points can be automatically generated by machines. In this paper, we report our experience developing and deploying the Intelligent Online Selling Point Extraction (IOSPE) system to serve the recommendation system in the JD.com e-commerce platform. Since July 2020, IOSPE has become a core service for 62 key categories of products (covering more than 4 million products). So far, it has generated more than 0.1 billion selling points, thereby significantly scaling up the selling point creation operation and saving human labour. These IOSPE generated selling points have increased the click-through rate (CTR) by 1.89\% and the average duration the customers spent on the products by more than 2.03\% compared to the previous practice, which are significant improvements for such a large-scale e-commerce platform.
Automatic Product Copywriting for E-Commerce
Dec 15, 2021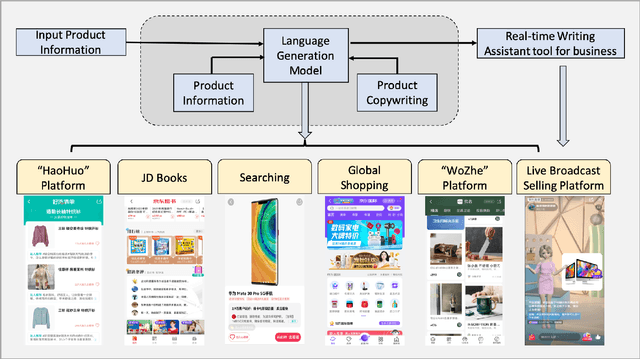

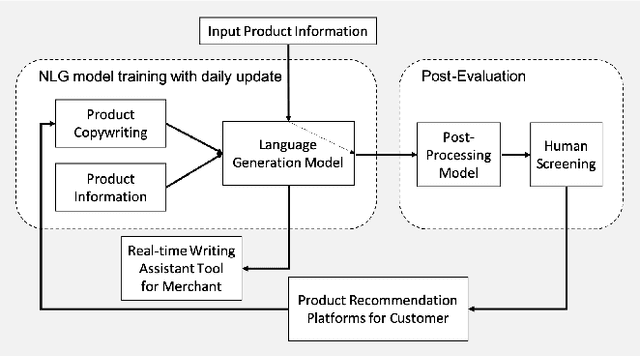
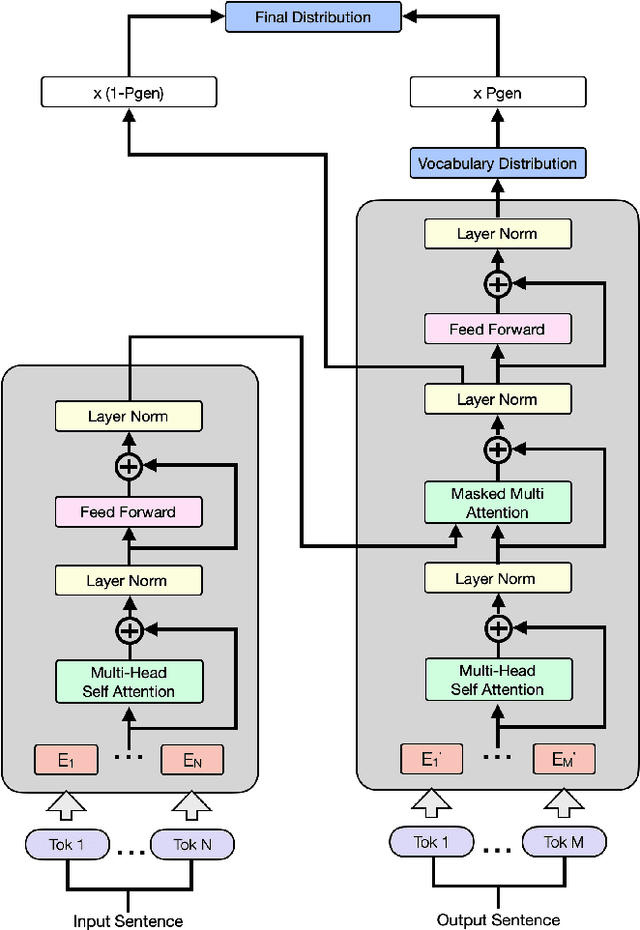
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021



We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
RDF-to-Text Generation with Reinforcement Learning Based Graph-augmented Structural Neural Encoders
Nov 20, 2021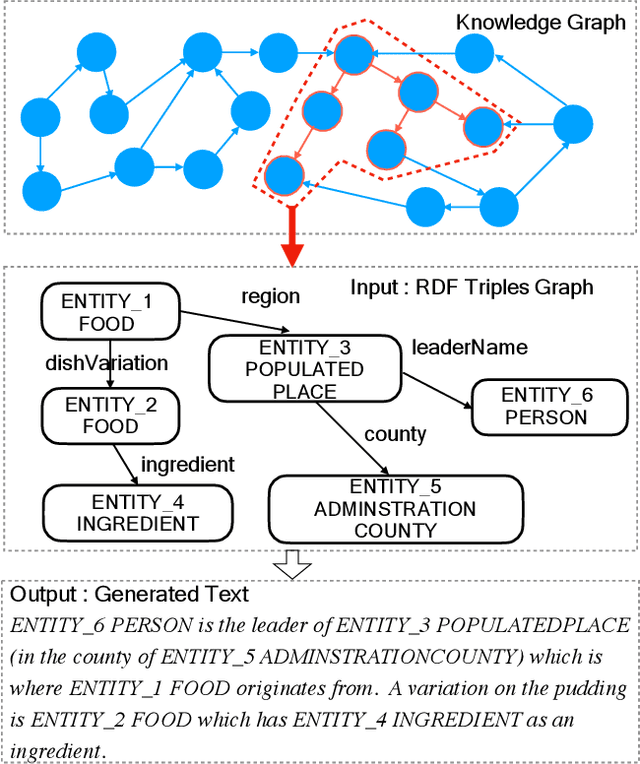

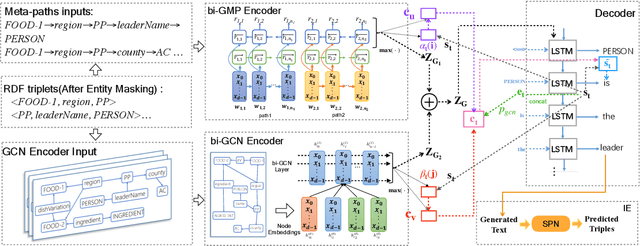
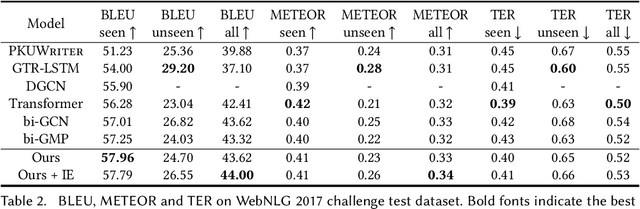
Considering a collection of RDF triples, the RDF-to-text generation task aims to generate a text description. Most previous methods solve this task using a sequence-to-sequence model or using a graph-based model to encode RDF triples and to generate a text sequence. Nevertheless, these approaches fail to clearly model the local and global structural information between and within RDF triples. Moreover, the previous methods also face the non-negligible problem of low faithfulness of the generated text, which seriously affects the overall performance of these models. To solve these problems, we propose a model combining two new graph-augmented structural neural encoders to jointly learn both local and global structural information in the input RDF triples. To further improve text faithfulness, we innovatively introduce a reinforcement learning (RL) reward based on information extraction (IE). We first extract triples from the generated text using a pretrained IE model and regard the correct number of the extracted triples as the additional RL reward. Experimental results on two benchmark datasets demonstrate that our proposed model outperforms the state-of-the-art baselines, and the additional reinforcement learning reward does help to improve the faithfulness of the generated text.
Graph-augmented Learning to Rank for Querying Large-scale Knowledge Graph
Nov 20, 2021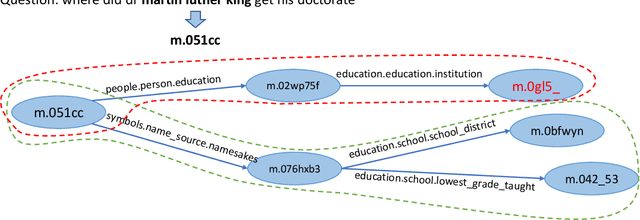

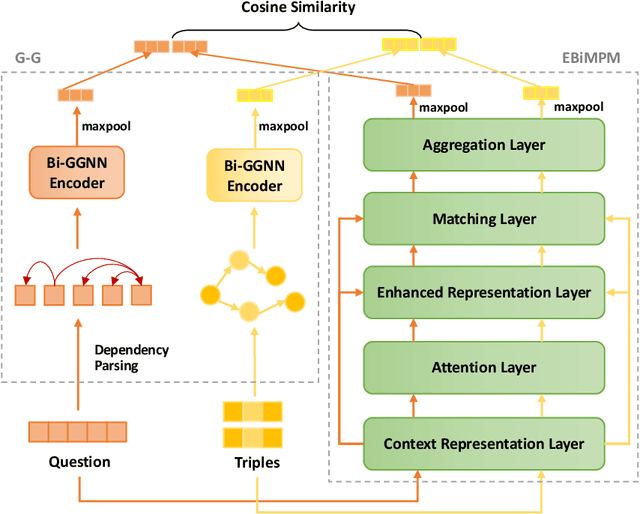
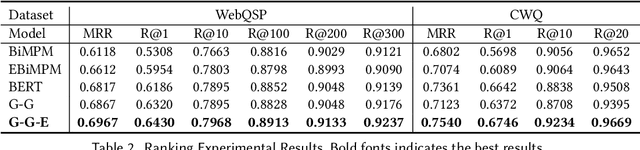
Knowledge graph question answering (i.e., KGQA) based on information retrieval aims to answer a question by retrieving answer from a large-scale knowledge graph. Most existing methods first roughly retrieve the knowledge subgraphs (KSG) that may contain candidate answer, and then search for the exact answer in the subgraph. However, the coarsely retrieved KSG may contain thousands of candidate nodes since the knowledge graph involved in querying is often of large scale. To tackle this problem, we first propose to partition the retrieved KSG to several smaller sub-KSGs via a new subgraph partition algorithm and then present a graph-augmented learning to rank model to select the top-ranked sub-KSGs from them. Our proposed model combines a novel subgraph matching networks to capture global interactions in both question and subgraphs and an Enhanced Bilateral Multi-Perspective Matching model to capture local interactions. Finally, we apply an answer selection model on the full KSG and the top-ranked sub-KSGs respectively to validate the effectiveness of our proposed graph-augmented learning to rank method. The experimental results on multiple benchmark datasets have demonstrated the effectiveness of our approach.
Multi-behavior Graph Contextual Aware Network for Session-based Recommendation
Sep 24, 2021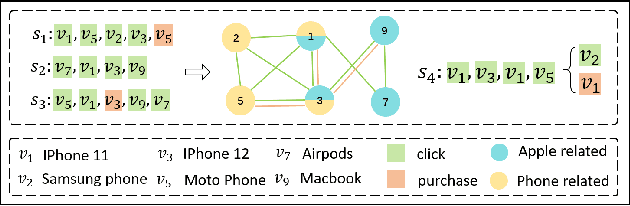
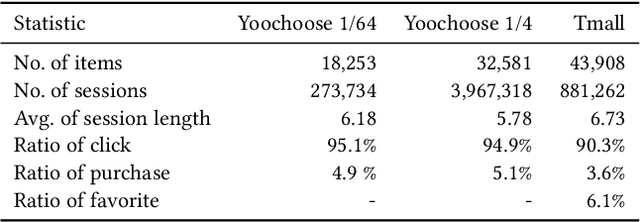
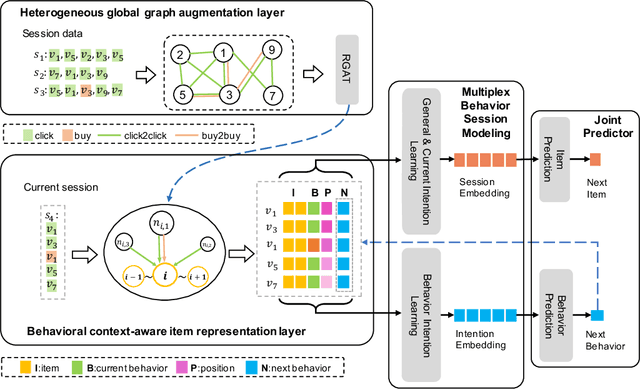
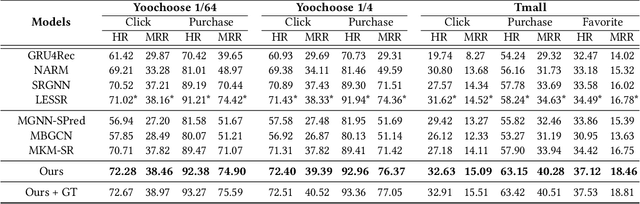
Predicting the next interaction of a short-term sequence is a challenging task in session-based recommendation (SBR).Multi-behavior session recommendation considers session sequence with multiple interaction types, such as click and purchase, to capture more effective user intention representation sufficiently.Despite the superior performance of existing multi-behavior based methods for SBR, there are still several severe limitations:(i) Almost all existing works concentrate on single target type of next behavior and fail to model multiplex behavior sessions uniformly.(ii) Previous methods also ignore the semantic relations between various next behavior and historical behavior sequence, which are significant signals to obtain current latent intention for SBR.(iii) The global cross-session item-item graph established by some existing models may incorporate semantics and context level noise for multi-behavior session-based recommendation. To overcome the limitations (i) and (ii), we propose two novel tasks for SBR, which require the incorporation of both historical behaviors and next behaviors into unified multi-behavior recommendation modeling. To this end, we design a Multi-behavior Graph Contextual Aware Network (MGCNet) for multi-behavior session-based recommendation for the two proposed tasks. Specifically, we build a multi-behavior global item transition graph based on all sessions involving all interaction types. Based on the global graph, MGCNet attaches the global interest representation to final item representation based on local contextual intention to address the limitation (iii). In the end, we utilize the next behavior information explicitly to guide the learning of general interest and current intention for SBR. Experiments on three public benchmark datasets show that MGCNet can outperform state-of-the-art models for multi-behavior session-based recommendation.