 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebate to Align: Reliable Entity Alignment through Two-Stage Multi-Agent Debate
Apr 15, 2026Entity alignment (EA) aims to identify entities referring to the same real-world object across different knowledge graphs (KGs). Recent approaches based on large language models (LLMs) typically obtain entity embeddings through knowledge representation learning and use embedding similarity to identify an alignment-uncertain entity set. For each uncertain entity, a candidate entity set (CES) is then retrieved based on embedding similarity to support subsequent alignment reasoning and decision making. However, the reliability of the CES and the reasoning capability of LLMs critically affect the effectiveness of subsequent alignment decisions. To address this issue, we propose AgentEA, a reliable EA framework based on multi-agent debate. AgentEA first improves embedding quality through entity representation preference optimization, and then introduces a two-stage multi-role debate mechanism consisting of lightweight debate verification and deep debate alignment to progressively enhance the reliability of alignment decisions while enabling more efficient debate-based reasoning. Extensive experiments on public benchmarks under cross-lingual, sparse, large-scale, and heterogeneous settings demonstrate the effectiveness of AgentEA.
RDF-to-Text Generation with Reinforcement Learning Based Graph-augmented Structural Neural Encoders
Nov 20, 2021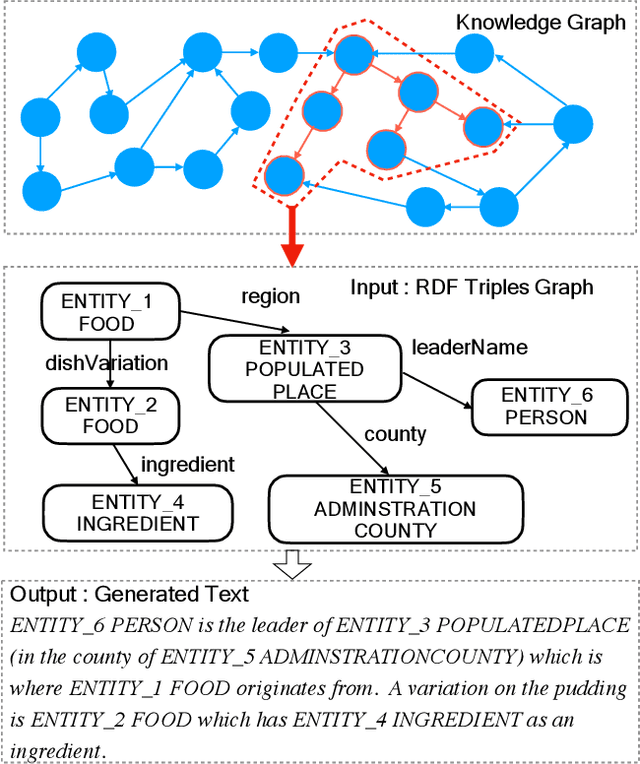

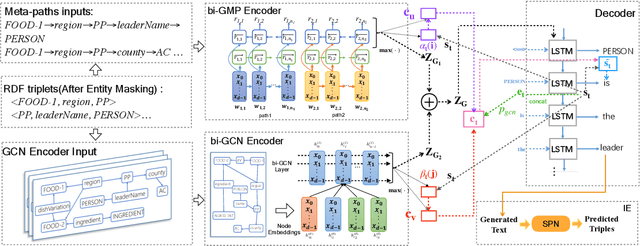
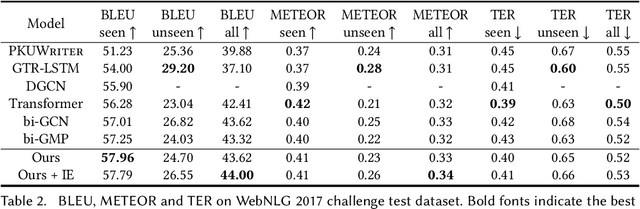
Considering a collection of RDF triples, the RDF-to-text generation task aims to generate a text description. Most previous methods solve this task using a sequence-to-sequence model or using a graph-based model to encode RDF triples and to generate a text sequence. Nevertheless, these approaches fail to clearly model the local and global structural information between and within RDF triples. Moreover, the previous methods also face the non-negligible problem of low faithfulness of the generated text, which seriously affects the overall performance of these models. To solve these problems, we propose a model combining two new graph-augmented structural neural encoders to jointly learn both local and global structural information in the input RDF triples. To further improve text faithfulness, we innovatively introduce a reinforcement learning (RL) reward based on information extraction (IE). We first extract triples from the generated text using a pretrained IE model and regard the correct number of the extracted triples as the additional RL reward. Experimental results on two benchmark datasets demonstrate that our proposed model outperforms the state-of-the-art baselines, and the additional reinforcement learning reward does help to improve the faithfulness of the generated text.
Graph-augmented Learning to Rank for Querying Large-scale Knowledge Graph
Nov 20, 2021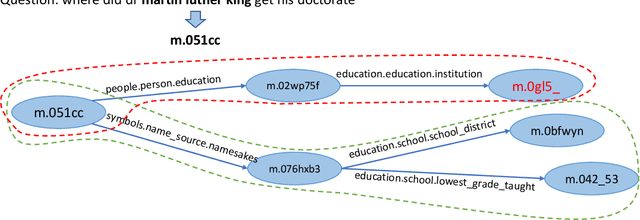

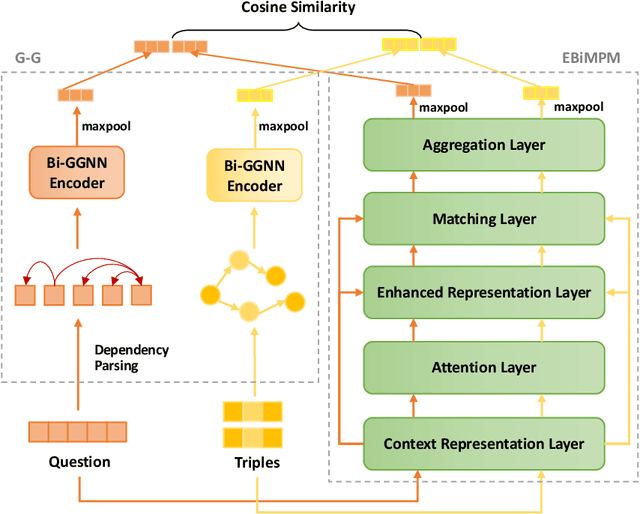
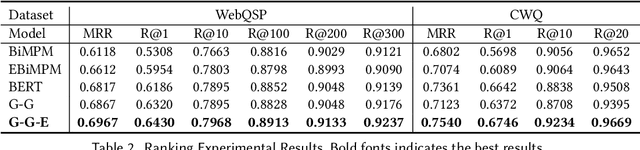
Knowledge graph question answering (i.e., KGQA) based on information retrieval aims to answer a question by retrieving answer from a large-scale knowledge graph. Most existing methods first roughly retrieve the knowledge subgraphs (KSG) that may contain candidate answer, and then search for the exact answer in the subgraph. However, the coarsely retrieved KSG may contain thousands of candidate nodes since the knowledge graph involved in querying is often of large scale. To tackle this problem, we first propose to partition the retrieved KSG to several smaller sub-KSGs via a new subgraph partition algorithm and then present a graph-augmented learning to rank model to select the top-ranked sub-KSGs from them. Our proposed model combines a novel subgraph matching networks to capture global interactions in both question and subgraphs and an Enhanced Bilateral Multi-Perspective Matching model to capture local interactions. Finally, we apply an answer selection model on the full KSG and the top-ranked sub-KSGs respectively to validate the effectiveness of our proposed graph-augmented learning to rank method. The experimental results on multiple benchmark datasets have demonstrated the effectiveness of our approach.