 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
May 30, 2024How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
Unifying Structured Data as Graph for Data-to-Text Pre-Training
Jan 02, 2024Data-to-text (D2T) generation aims to transform structured data into natural language text. Data-to-text pre-training has proved to be powerful in enhancing D2T generation and yields impressive performances. However, previous pre-training methods either oversimplified structured data into a sequence without considering input structures or designed training objectives tailored for a specific data structure (e.g., table or knowledge graph). In this paper, we unify different types of structured data (i.e., table, key-value data, knowledge graph) into the graph format and cast different data-to-text generation tasks as graph-to-text generation. To effectively exploit the structural information of the input graph, we propose a structure-enhanced pre-training method for D2T generation by designing a structure-enhanced Transformer. Concretely, we devise a position matrix for the Transformer, encoding relative positional information of connected nodes in the input graph. In addition, we propose a new attention matrix to incorporate graph structures into the original Transformer by taking the available explicit connectivity structure into account. Extensive experiments on six benchmark datasets show the effectiveness of our model. Our source codes are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/unid2t.
CATS: A Pragmatic Chinese Answer-to-Sequence Dataset with Large Scale and High Quality
Jun 20, 2023There are three problems existing in the popular data-to-text datasets. First, the large-scale datasets either contain noise or lack real application scenarios. Second, the datasets close to real applications are relatively small in size. Last, current datasets bias in the English language while leaving other languages underexplored. To alleviate these limitations, in this paper, we present CATS, a pragmatic Chinese answer-to-sequence dataset with large scale and high quality. The dataset aims to generate textual descriptions for the answer in the practical TableQA system. Further, to bridge the structural gap between the input SQL and table and establish better semantic alignments, we propose a Unified Graph Transformation approach to establish a joint encoding space for the two hybrid knowledge resources and convert this task to a graph-to-text problem. The experiment results demonstrate the effectiveness of our proposed method. Further analysis on CATS attests to both the high quality and challenges of the dataset.
History Semantic Graph Enhanced Conversational KBQA with Temporal Information Modeling
Jun 12, 2023



Context information modeling is an important task in conversational KBQA. However, existing methods usually assume the independence of utterances and model them in isolation. In this paper, we propose a History Semantic Graph Enhanced KBQA model (HSGE) that is able to effectively model long-range semantic dependencies in conversation history while maintaining low computational cost. The framework incorporates a context-aware encoder, which employs a dynamic memory decay mechanism and models context at different levels of granularity. We evaluate HSGE on a widely used benchmark dataset for complex sequential question answering. Experimental results demonstrate that it outperforms existing baselines averaged on all question types.
Iterative Forward Tuning Boosts In-context Learning in Language Models
May 22, 2023



Large language models (LLMs) have exhibited an emergent in-context learning (ICL) ability. However, the ICL models that can solve ordinary cases are hardly extended to solve more complex tasks by processing the demonstration examples once. This single-turn ICL is incoordinate with the decision making process of humans by learning from analogy. In this paper, we propose an effective and efficient two-stage framework to boost ICL in LLMs by exploiting a dual form between Transformer attention and gradient descent-based optimization. Concretely, we divide the ICL process into "Deep-Thinking" and inference stages. The "Deep-Thinking" stage performs iterative forward optimization of demonstrations, which is expected to boost the reasoning abilities of LLMs at test time by "thinking" demonstrations multiple times. It produces accumulated meta-gradients by manipulating the Key-Value matrices in the self-attention modules of the Transformer. Then, the inference stage only takes the test query as input without concatenating demonstrations and applies the learned meta-gradients through attention for output prediction. In this way, demonstrations are not required during the inference stage since they are already learned and stored in the definitive meta-gradients. LLMs can be effectively and efficiently adapted to downstream tasks. Extensive experiments on ten classification and multiple-choice datasets show that our method achieves substantially better performance than standard ICL in terms of both accuracy and efficiency.
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
May 04, 2023



Text-to-SQL parsing, which aims at converting natural language instructions into executable SQLs, has gained increasing attention in recent years. In particular, Codex and ChatGPT have shown impressive results in this task. However, most of the prevalent benchmarks, i.e., Spider, and WikiSQL, focus on database schema with few rows of database contents leaving the gap between academic study and real-world applications. To mitigate this gap, we present Bird, a big benchmark for large-scale database grounded in text-to-SQL tasks, containing 12,751 pairs of text-to-SQL data and 95 databases with a total size of 33.4 GB, spanning 37 professional domains. Our emphasis on database values highlights the new challenges of dirty database contents, external knowledge between NL questions and database contents, and SQL efficiency, particularly in the context of massive databases. To solve these problems, text-to-SQL models must feature database value comprehension in addition to semantic parsing. The experimental results demonstrate the significance of database values in generating accurate text-to-SQLs for big databases. Furthermore, even the most effective text-to-SQL models, i.e. ChatGPT, only achieves 40.08% in execution accuracy, which is still far from the human result of 92.96%, proving that challenges still stand. Besides, we also provide an efficiency analysis to offer insights into generating text-to-efficient-SQLs that are beneficial to industries. We believe that BIRD will contribute to advancing real-world applications of text-to-SQL research. The leaderboard and source code are available: https://bird-bench.github.io/.
Plan-then-Seam: Towards Efficient Table-to-Text Generation
Feb 28, 2023



Table-to-text generation aims at automatically generating text to help people conveniently obtain salient information in tables. Recent works explicitly decompose the generation process into content planning and surface generation stages, employing two autoregressive networks for them respectively. However, they are computationally expensive due to the non-parallelizable nature of autoregressive decoding and the redundant parameters of two networks. In this paper, we propose the first totally non-autoregressive table-to-text model (Plan-then-Seam, PTS) that produces its outputs in parallel with one single network. PTS firstly writes and calibrates one plan of the content to be generated with a novel rethinking pointer predictor, and then takes the plan as the context for seaming to decode the description. These two steps share parameters and perform iteratively to capture token inter-dependency while keeping parallel decoding. Experiments on two public benchmarks show that PTS achieves 3.0~5.6 times speedup for inference time, reducing 50% parameters, while maintaining as least comparable performance against strong two-stage table-to-text competitors.
Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning
Jan 31, 2023Table-based reasoning has shown remarkable progress in combining deep models with discrete reasoning, which requires reasoning over both free-form natural language (NL) questions and structured tabular data. However, previous table-based reasoning solutions usually suffer from significant performance degradation on huge evidence (tables). In addition, most existing methods struggle to reason over complex questions since the required information is scattered in different places. To alleviate the above challenges, we exploit large language models (LLMs) as decomposers for effective table-based reasoning, which (i) decompose huge evidence (a huge table) into sub-evidence (a small table) to mitigate the interference of useless information for table reasoning; and (ii) decompose complex questions into simpler sub-questions for text reasoning. Specifically, we first use the LLMs to break down the evidence (tables) involved in the current question, retaining the relevant evidence and excluding the remaining irrelevant evidence from the huge table. In addition, we propose a "parsing-execution-filling" strategy to alleviate the hallucination dilemma of the chain of thought by decoupling logic and numerical computation in each step. Extensive experiments show that our method can effectively leverage decomposed evidence and questions and outperforms the strong baselines on TabFact, WikiTableQuestion, and FetaQA datasets. Notably, our model outperforms human performance for the first time on the TabFact dataset.
Towards Generalizable and Robust Text-to-SQL Parsing
Oct 23, 2022



Text-to-SQL parsing tackles the problem of mapping natural language questions to executable SQL queries. In practice, text-to-SQL parsers often encounter various challenging scenarios, requiring them to be generalizable and robust. While most existing work addresses a particular generalization or robustness challenge, we aim to study it in a more comprehensive manner. In specific, we believe that text-to-SQL parsers should be (1) generalizable at three levels of generalization, namely i.i.d., zero-shot, and compositional, and (2) robust against input perturbations. To enhance these capabilities of the parser, we propose a novel TKK framework consisting of Task decomposition, Knowledge acquisition, and Knowledge composition to learn text-to-SQL parsing in stages. By dividing the learning process into multiple stages, our framework improves the parser's ability to acquire general SQL knowledge instead of capturing spurious patterns, making it more generalizable and robust. Experimental results under various generalization and robustness settings show that our framework is effective in all scenarios and achieves state-of-the-art performance on the Spider, SParC, and CoSQL datasets. Code can be found at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/tkk.
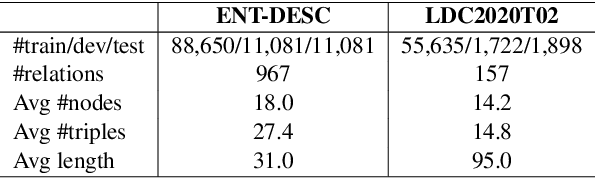
Graph-to-Text Generation with Dynamic Structure Pruning
Sep 15, 2022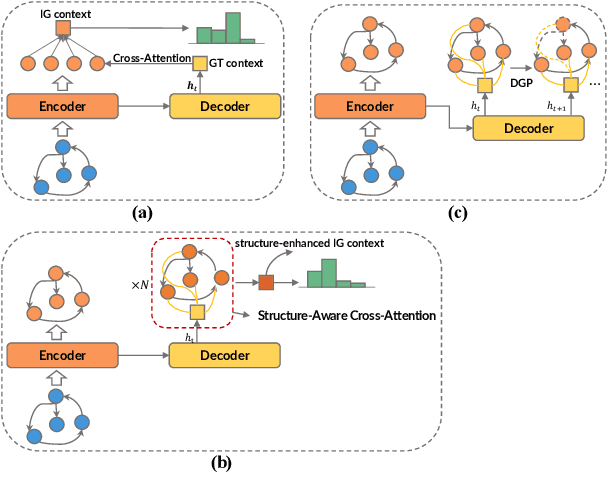
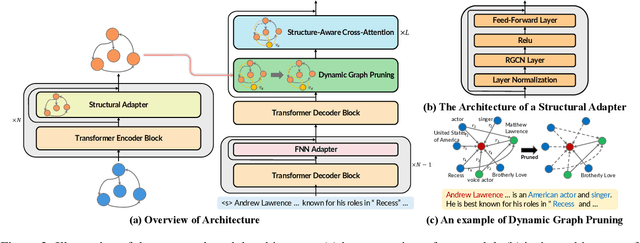
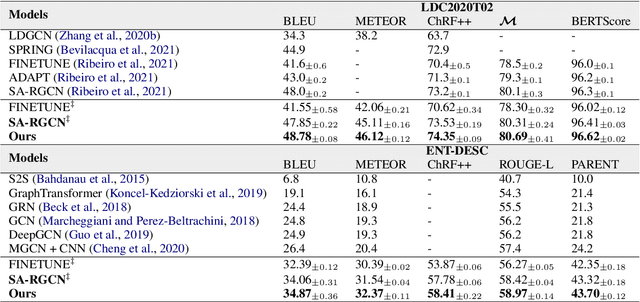
Most graph-to-text works are built on the encoder-decoder framework with cross-attention mechanism. Recent studies have shown that explicitly modeling the input graph structure can significantly improve the performance. However, the vanilla structural encoder cannot capture all specialized information in a single forward pass for all decoding steps, resulting in inaccurate semantic representations. Meanwhile, the input graph is flatted as an unordered sequence in the cross attention, ignoring the original graph structure. As a result, the obtained input graph context vector in the decoder may be flawed. To address these issues, we propose a Structure-Aware Cross-Attention (SACA) mechanism to re-encode the input graph representation conditioning on the newly generated context at each decoding step in a structure aware manner. We further adapt SACA and introduce its variant Dynamic Graph Pruning (DGP) mechanism to dynamically drop irrelevant nodes in the decoding process. We achieve new state-of-the-art results on two graph-to-text datasets, LDC2020T02 and ENT-DESC, with only minor increase on computational cost.