 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Stage-wise Learning for Unsupervised Feature Representation Enhancement
Jun 11, 2021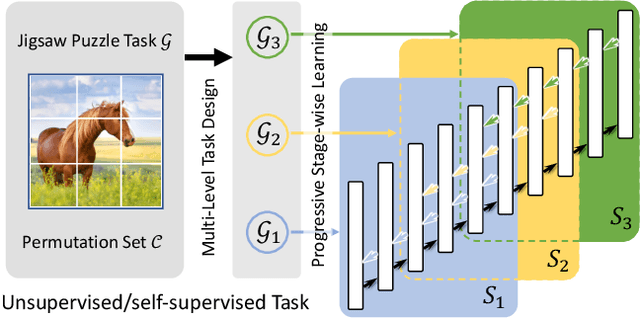

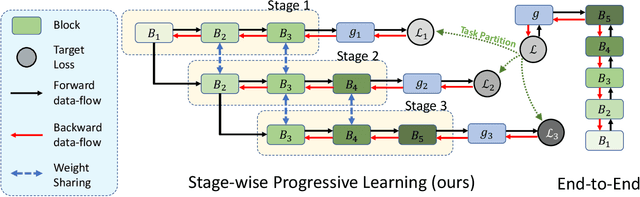
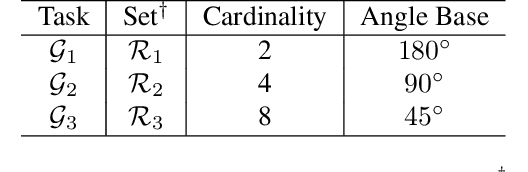
Unsupervised learning methods have recently shown their competitiveness against supervised training. Typically, these methods use a single objective to train the entire network. But one distinct advantage of unsupervised over supervised learning is that the former possesses more variety and freedom in designing the objective. In this work, we explore new dimensions of unsupervised learning by proposing the Progressive Stage-wise Learning (PSL) framework. For a given unsupervised task, we design multilevel tasks and define different learning stages for the deep network. Early learning stages are forced to focus on lowlevel tasks while late stages are guided to extract deeper information through harder tasks. We discover that by progressive stage-wise learning, unsupervised feature representation can be effectively enhanced. Our extensive experiments show that PSL consistently improves results for the leading unsupervised learning methods.
SimSwap: An Efficient Framework For High Fidelity Face Swapping
Jun 11, 2021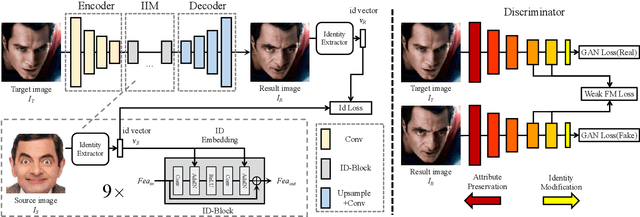

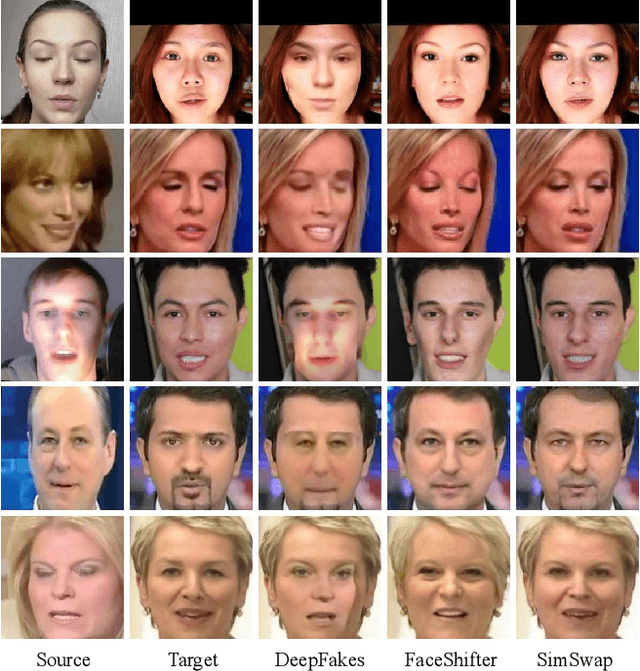

We propose an efficient framework, called Simple Swap (SimSwap), aiming for generalized and high fidelity face swapping. In contrast to previous approaches that either lack the ability to generalize to arbitrary identity or fail to preserve attributes like facial expression and gaze direction, our framework is capable of transferring the identity of an arbitrary source face into an arbitrary target face while preserving the attributes of the target face. We overcome the above defects in the following two ways. First, we present the ID Injection Module (IIM) which transfers the identity information of the source face into the target face at feature level. By using this module, we extend the architecture of an identity-specific face swapping algorithm to a framework for arbitrary face swapping. Second, we propose the Weak Feature Matching Loss which efficiently helps our framework to preserve the facial attributes in an implicit way. Extensive experiments on wild faces demonstrate that our SimSwap is able to achieve competitive identity performance while preserving attributes better than previous state-of-the-art methods. The code is already available on github: https://github.com/neuralchen/SimSwap.
* Accepted by ACMMM 2020
Self-supervised Graph-level Representation Learning with Local and Global Structure
Jun 08, 2021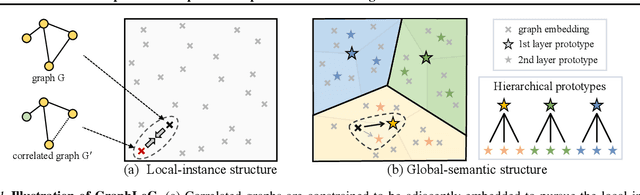
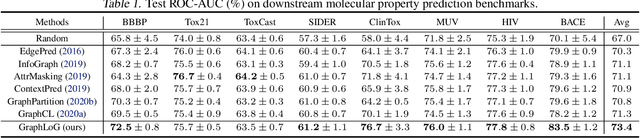
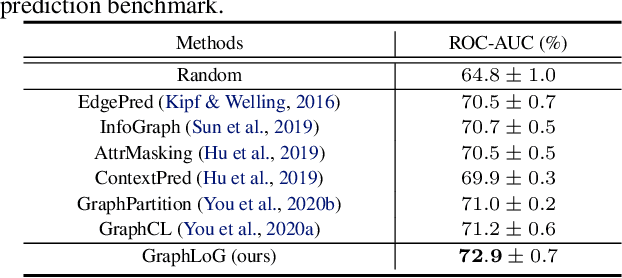

This paper studies unsupervised/self-supervised whole-graph representation learning, which is critical in many tasks such as molecule properties prediction in drug and material discovery. Existing methods mainly focus on preserving the local similarity structure between different graph instances but fail to discover the global semantic structure of the entire data set. In this paper, we propose a unified framework called Local-instance and Global-semantic Learning (GraphLoG) for self-supervised whole-graph representation learning. Specifically, besides preserving the local similarities, GraphLoG introduces the hierarchical prototypes to capture the global semantic clusters. An efficient online expectation-maximization (EM) algorithm is further developed for learning the model. We evaluate GraphLoG by pre-training it on massive unlabeled graphs followed by fine-tuning on downstream tasks. Extensive experiments on both chemical and biological benchmark data sets demonstrate the effectiveness of the proposed approach.
X-volution: On the unification of convolution and self-attention
Jun 07, 2021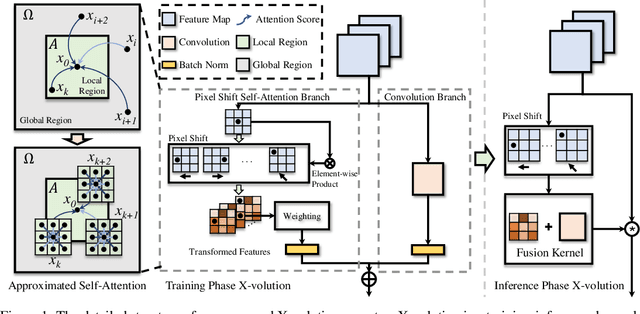
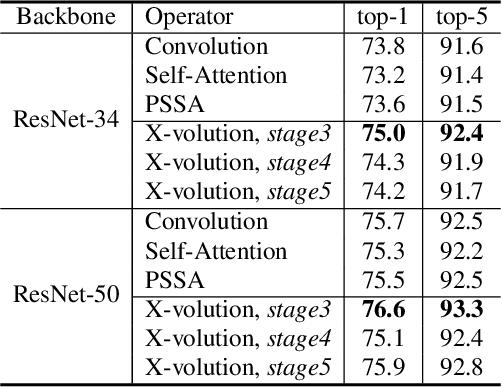
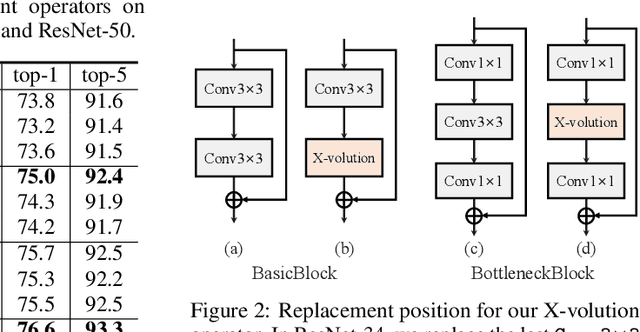
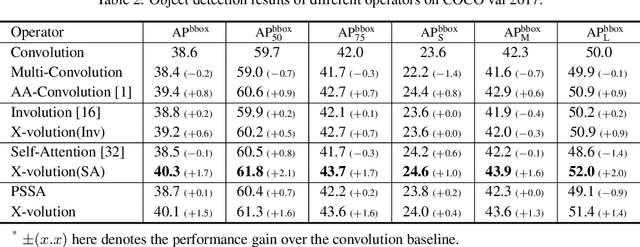
Convolution and self-attention are acting as two fundamental building blocks in deep neural networks, where the former extracts local image features in a linear way while the latter non-locally encodes high-order contextual relationships. Though essentially complementary to each other, i.e., first-/high-order, stat-of-the-art architectures, i.e., CNNs or transformers lack a principled way to simultaneously apply both operations in a single computational module, due to their heterogeneous computing pattern and excessive burden of global dot-product for visual tasks. In this work, we theoretically derive a global self-attention approximation scheme, which approximates a self-attention via the convolution operation on transformed features. Based on the approximated scheme, we establish a multi-branch elementary module composed of both convolution and self-attention operation, capable of unifying both local and non-local feature interaction. Importantly, once trained, this multi-branch module could be conditionally converted into a single standard convolution operation via structural re-parameterization, rendering a pure convolution styled operator named X-volution, ready to be plugged into any modern networks as an atomic operation. Extensive experiments demonstrate that the proposed X-volution, achieves highly competitive visual understanding improvements (+1.2% top-1 accuracy on ImageNet classification, +1.7 box AP and +1.5 mask AP on COCO detection and segmentation).
3D Human Action Representation Learning via Cross-View Consistency Pursuit
May 01, 2021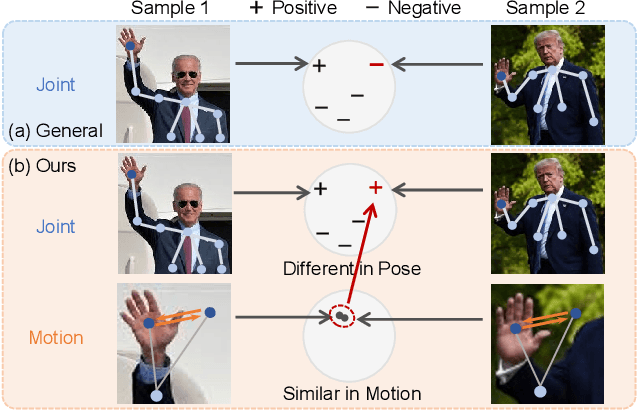
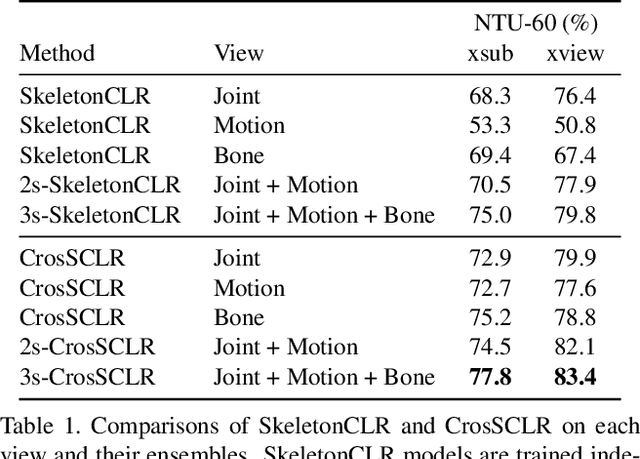
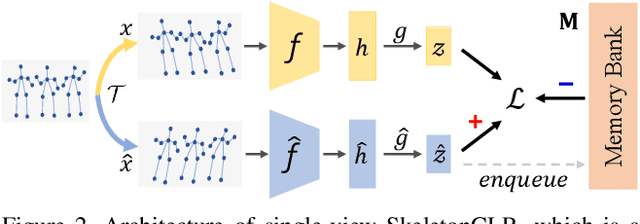
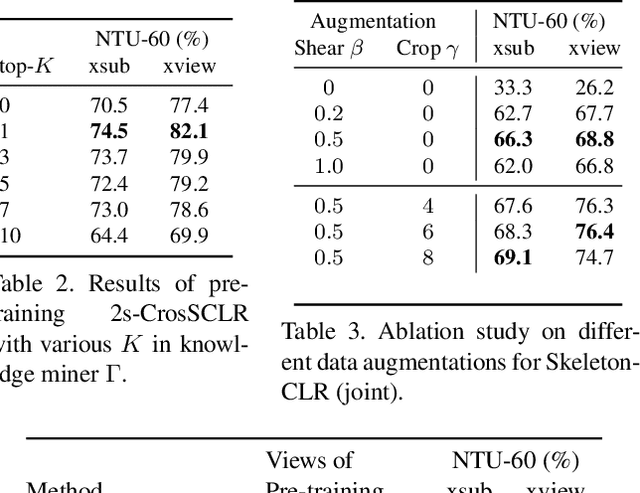
In this work, we propose a Cross-view Contrastive Learning framework for unsupervised 3D skeleton-based action Representation (CrosSCLR), by leveraging multi-view complementary supervision signal. CrosSCLR consists of both single-view contrastive learning (SkeletonCLR) and cross-view consistent knowledge mining (CVC-KM) modules, integrated in a collaborative learning manner. It is noted that CVC-KM works in such a way that high-confidence positive/negative samples and their distributions are exchanged among views according to their embedding similarity, ensuring cross-view consistency in terms of contrastive context, i.e., similar distributions. Extensive experiments show that CrosSCLR achieves remarkable action recognition results on NTU-60 and NTU-120 datasets under unsupervised settings, with observed higher-quality action representations. Our code is available at https://github.com/LinguoLi/CrosSCLR.
Learning Multi-Attention Context Graph for Group-Based Re-Identification
Apr 29, 2021

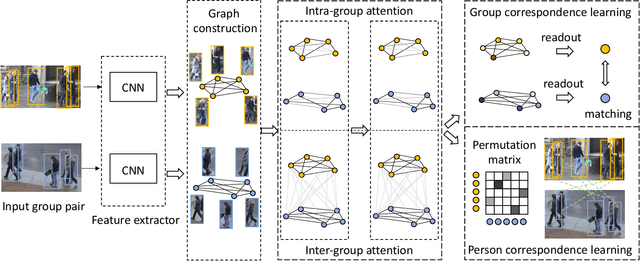

Learning to re-identify or retrieve a group of people across non-overlapped camera systems has important applications in video surveillance. However, most existing methods focus on (single) person re-identification (re-id), ignoring the fact that people often walk in groups in real scenarios. In this work, we take a step further and consider employing context information for identifying groups of people, i.e., group re-id. We propose a novel unified framework based on graph neural networks to simultaneously address the group-based re-id tasks, i.e., group re-id and group-aware person re-id. Specifically, we construct a context graph with group members as its nodes to exploit dependencies among different people. A multi-level attention mechanism is developed to formulate both intra-group and inter-group context, with an additional self-attention module for robust graph-level representations by attentively aggregating node-level features. The proposed model can be directly generalized to tackle group-aware person re-id using node-level representations. Meanwhile, to facilitate the deployment of deep learning models on these tasks, we build a new group re-id dataset that contains more than 3.8K images with 1.5K annotated groups, an order of magnitude larger than existing group re-id datasets. Extensive experiments on the novel dataset as well as three existing datasets clearly demonstrate the effectiveness of the proposed framework for both group-based re-id tasks. The code is available at https://github.com/daodaofr/group_reid.
Graphical Modeling for Multi-Source Domain Adaptation
Apr 27, 2021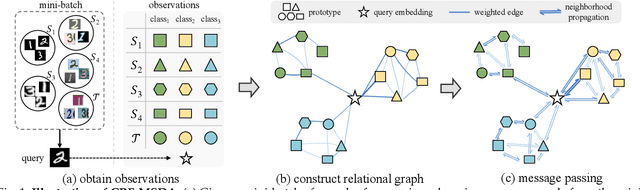

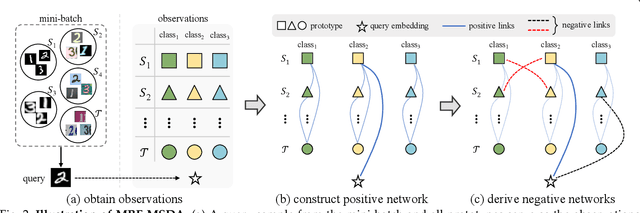
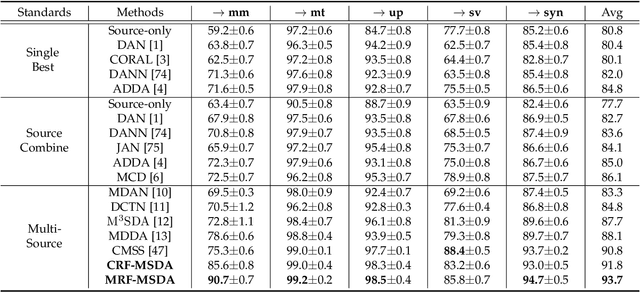
Multi-Source Domain Adaptation (MSDA) focuses on transferring the knowledge from multiple source domains to the target domain, which is a more practical and challenging problem compared to the conventional single-source domain adaptation. In this problem, it is essential to utilize the labeled source data and the unlabeled target data to approach the conditional distribution of semantic label on target domain, which requires the joint modeling across different domains and also an effective domain combination scheme. The graphical structure among different domains is useful to tackle these challenges, in which the interdependency among various instances/categories can be effectively modeled. In this work, we propose two types of graphical models,i.e. Conditional Random Field for MSDA (CRF-MSDA) and Markov Random Field for MSDA (MRF-MSDA), for cross-domain joint modeling and learnable domain combination. In a nutshell, given an observation set composed of a query sample and the semantic prototypes i.e. representative category embeddings) on various domains, the CRF-MSDA model seeks to learn the joint distribution of labels conditioned on the observations. We attain this goal by constructing a relational graph over all observations and conducting local message passing on it. By comparison, MRF-MSDA aims to model the joint distribution of observations over different Markov networks via an energy-based formulation, and it can naturally perform label prediction by summing the joint likelihoods over several specific networks. Compared to the CRF-MSDA counterpart, the MRF-MSDA model is more expressive and possesses lower computational cost. We evaluate these two models on four standard benchmark data sets of MSDA with distinct domain shift and data complexity, and both models achieve superior performance over existing methods on all benchmarks.
Bilevel Online Adaptation for Out-of-Domain Human Mesh Reconstruction
Mar 30, 2021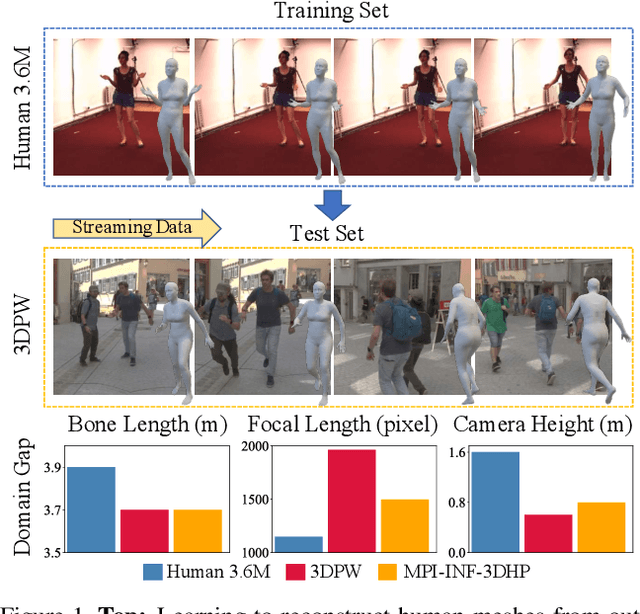
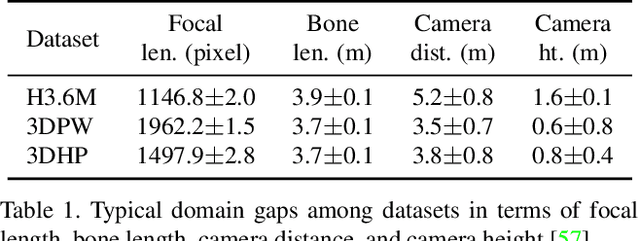
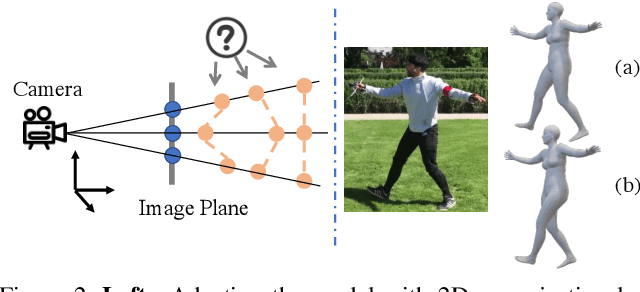
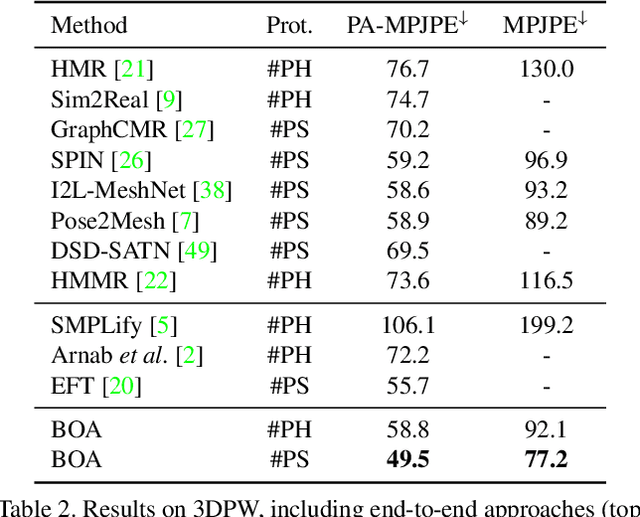
This paper considers a new problem of adapting a pre-trained model of human mesh reconstruction to out-of-domain streaming videos. However, most previous methods based on the parametric SMPL model \cite{loper2015smpl} underperform in new domains with unexpected, domain-specific attributes, such as camera parameters, lengths of bones, backgrounds, and occlusions. Our general idea is to dynamically fine-tune the source model on test video streams with additional temporal constraints, such that it can mitigate the domain gaps without over-fitting the 2D information of individual test frames. A subsequent challenge is how to avoid conflicts between the 2D and temporal constraints. We propose to tackle this problem using a new training algorithm named Bilevel Online Adaptation (BOA), which divides the optimization process of overall multi-objective into two steps of weight probe and weight update in a training iteration. We demonstrate that BOA leads to state-of-the-art results on two human mesh reconstruction benchmarks.
Image Translation via Fine-grained Knowledge Transfer
Dec 21, 2020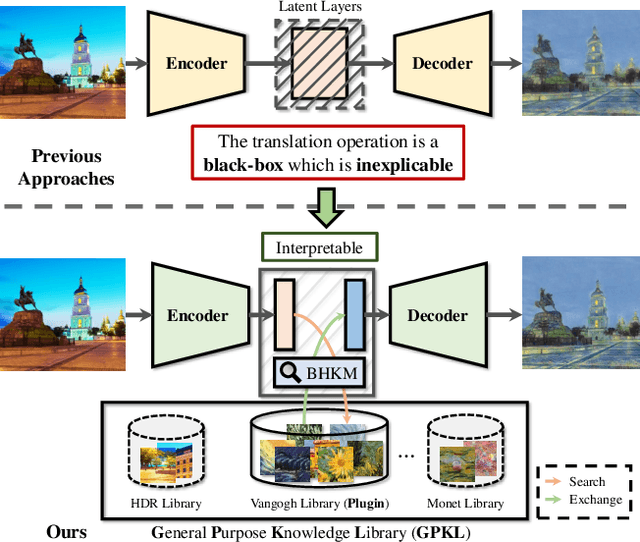



Prevailing image-translation frameworks mostly seek to process images via the end-to-end style, which has achieved convincing results. Nonetheless, these methods lack interpretability and are not scalable on different image-translation tasks (e.g., style transfer, HDR, etc.). In this paper, we propose an interpretable knowledge-based image-translation framework, which realizes the image-translation through knowledge retrieval and transfer. In details, the framework constructs a plug-and-play and model-agnostic general purpose knowledge library, remembering task-specific styles, tones, texture patterns, etc. Furthermore, we present a fast ANN searching approach, Bandpass Hierarchical K-Means (BHKM), to cope with the difficulty of searching in the enormous knowledge library. Extensive experiments well demonstrate the effectiveness and feasibility of our framework in different image-translation tasks. In particular, backtracking experiments verify the interpretability of our method. Our code soon will be available at https://github.com/AceSix/Knowledge_Transfer.
RainNet: A Large-Scale Dataset for Spatial Precipitation Downscaling
Dec 18, 2020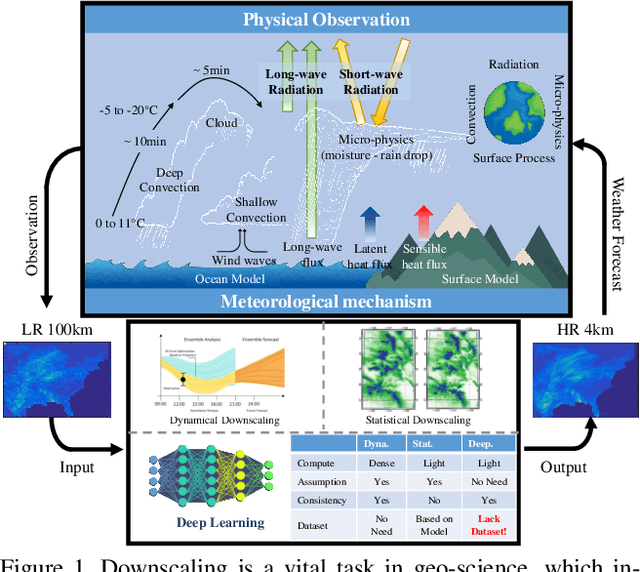
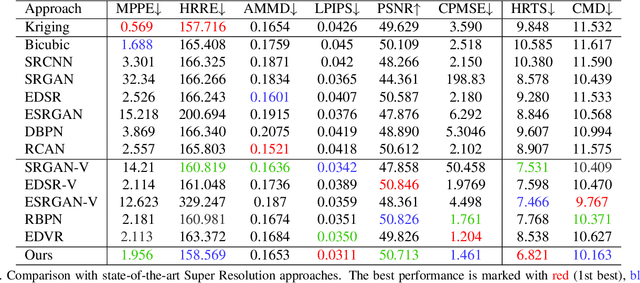
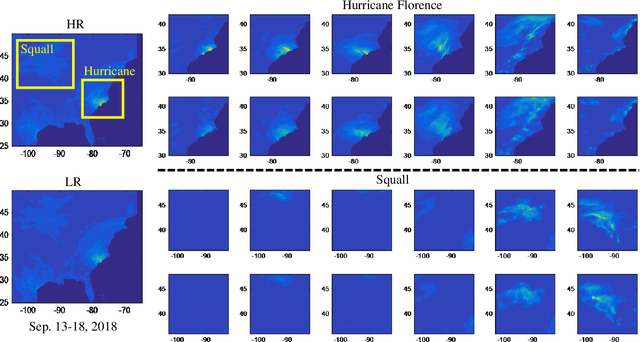
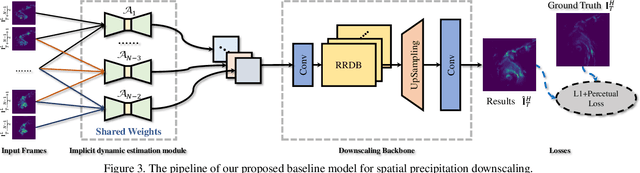
Spatial Precipitation Downscaling is one of the most important problems in the geo-science community. However, it still remains an unaddressed issue. Deep learning is a promising potential solution for downscaling. In order to facilitate the research on precipitation downscaling for deep learning, we present the first REAL (non-simulated) Large-Scale Spatial Precipitation Downscaling Dataset, RainNet, which contains 62,424 pairs of low-resolution and high-resolution precipitation maps for 17 years. Contrary to simulated data, this real dataset covers various types of real meteorological phenomena (e.g., Hurricane, Squall, etc.), and shows the physical characters - Temporal Misalignment, Temporal Sparse and Fluid Properties - that challenge the downscaling algorithms. In order to fully explore potential downscaling solutions, we propose an implicit physical estimation framework to learn the above characteristics. Eight metrics specifically considering the physical property of the data set are raised, while fourteen models are evaluated on the proposed dataset. Finally, we analyze the effectiveness and feasibility of these models on precipitation downscaling task. The Dataset and Code will be available at https://neuralchen.github.io/RainNet/.