 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultisource Collaborative Domain Generalization for Cross-Scene Remote Sensing Image Classification
Dec 05, 2024



Cross-scene image classification aims to transfer prior knowledge of ground materials to annotate regions with different distributions and reduce hand-crafted cost in the field of remote sensing. However, existing approaches focus on single-source domain generalization to unseen target domains, and are easily confused by large real-world domain shifts due to the limited training information and insufficient diversity modeling capacity. To address this gap, we propose a novel multi-source collaborative domain generalization framework (MS-CDG) based on homogeneity and heterogeneity characteristics of multi-source remote sensing data, which considers data-aware adversarial augmentation and model-aware multi-level diversification simultaneously to enhance cross-scene generalization performance. The data-aware adversarial augmentation adopts an adversary neural network with semantic guide to generate MS samples by adaptively learning realistic channel and distribution changes across domains. In views of cross-domain and intra-domain modeling, the model-aware diversification transforms the shared spatial-channel features of MS data into the class-wise prototype and kernel mixture module, to address domain discrepancies and cluster different classes effectively. Finally, the joint classification of original and augmented MS samples is employed by introducing a distribution consistency alignment to increase model diversity and ensure better domain-invariant representation learning. Extensive experiments on three public MS remote sensing datasets demonstrate the superior performance of the proposed method when benchmarked with the state-of-the-art methods.
Hyperspectral Image Cross-Domain Object Detection Method based on Spectral-Spatial Feature Alignment
Nov 25, 2024



With consecutive bands in a wide range of wavelengths, hyperspectral images (HSI) have provided a unique tool for object detection task. However, existing HSI object detection methods have not been fully utilized in real applications, which is mainly resulted by the difference of spatial and spectral resolution between the unlabeled target domain and a labeled source domain, i.e. the domain shift of HSI. In this work, we aim to explore the unsupervised cross-domain object detection of HSI. Our key observation is that the local spatial-spectral characteristics remain invariant across different domains. For solving the problem of domain-shift, we propose a HSI cross-domain object detection method based on spectral-spatial feature alignment, which is the first attempt in the object detection community to the best of our knowledge. Firstly, we develop a spectral-spatial alignment module to extract domain-invariant local spatial-spectral features. Secondly, the spectral autocorrelation module has been designed to solve the domain shift in the spectral domain specifically, which can effectively align HSIs with different spectral resolutions. Besides, we have collected and annotated an HSI dataset for the cross-domain object detection. Our experimental results have proved the effectiveness of HSI cross-domain object detection, which has firstly demonstrated a significant and promising step towards HSI cross-domain object detection in the object detection community.
Enterprise Benchmarks for Large Language Model Evaluation
Oct 11, 2024



The advancement of large language models (LLMs) has led to a greater challenge of having a rigorous and systematic evaluation of complex tasks performed, especially in enterprise applications. Therefore, LLMs need to be able to benchmark enterprise datasets for various tasks. This work presents a systematic exploration of benchmarking strategies tailored to LLM evaluation, focusing on the utilization of domain-specific datasets and consisting of a variety of NLP tasks. The proposed evaluation framework encompasses 25 publicly available datasets from diverse enterprise domains like financial services, legal, cyber security, and climate and sustainability. The diverse performance of 13 models across different enterprise tasks highlights the importance of selecting the right model based on the specific requirements of each task. Code and prompts are available on GitHub.
Low-Rank Representations Meets Deep Unfolding: A Generalized and Interpretable Network for Hyperspectral Anomaly Detection
Feb 23, 2024



Current hyperspectral anomaly detection (HAD) benchmark datasets suffer from low resolution, simple background, and small size of the detection data. These factors also limit the performance of the well-known low-rank representation (LRR) models in terms of robustness on the separation of background and target features and the reliance on manual parameter selection. To this end, we build a new set of HAD benchmark datasets for improving the robustness of the HAD algorithm in complex scenarios, AIR-HAD for short. Accordingly, we propose a generalized and interpretable HAD network by deeply unfolding a dictionary-learnable LLR model, named LRR-Net$^+$, which is capable of spectrally decoupling the background structure and object properties in a more generalized fashion and eliminating the bias introduced by vital interference targets concurrently. In addition, LRR-Net$^+$ integrates the solution process of the Alternating Direction Method of Multipliers (ADMM) optimizer with the deep network, guiding its search process and imparting a level of interpretability to parameter optimization. Additionally, the integration of physical models with DL techniques eliminates the need for manual parameter tuning. The manually tuned parameters are seamlessly transformed into trainable parameters for deep neural networks, facilitating a more efficient and automated optimization process. Extensive experiments conducted on the AIR-HAD dataset show the superiority of our LRR-Net$^+$ in terms of detection performance and generalization ability, compared to top-performing rivals. Furthermore, the compilable codes and our AIR-HAD benchmark datasets in this paper will be made available freely and openly at \url{https://sites.google.com/view/danfeng-hong}.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023



The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Oct 03, 2023



Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e.g., single cities or regions). Yet these AI models tend to meet the performance bottleneck in the case studies across cities or regions, due to the lack of diverse RS information and cutting-edge solutions with high generalization ability. To this end, we build a new set of multimodal remote sensing benchmark datasets (including hyperspectral, multispectral, SAR) for the study purpose of the cross-city semantic segmentation task (called C2Seg dataset), which consists of two cross-city scenes, i.e., Berlin-Augsburg (in Germany) and Beijing-Wuhan (in China). Beyond the single city, we propose a high-resolution domain adaptation network, HighDAN for short, to promote the AI model's generalization ability from the multi-city environments. HighDAN is capable of retaining the spatially topological structure of the studied urban scene well in a parallel high-to-low resolution fusion fashion but also closing the gap derived from enormous differences of RS image representations between different cities by means of adversarial learning. In addition, the Dice loss is considered in HighDAN to alleviate the class imbalance issue caused by factors across cities. Extensive experiments conducted on the C2Seg dataset show the superiority of our HighDAN in terms of segmentation performance and generalization ability, compared to state-of-the-art competitors. The C2Seg dataset and the semantic segmentation toolbox (involving the proposed HighDAN) will be available publicly at https://github.com/danfenghong.
Demystifying the Performance of Data Transfers in High-Performance Research Networks
Aug 20, 2023



High-speed research networks are built to meet the ever-increasing needs of data-intensive distributed workflows. However, data transfers in these networks often fail to attain the promised transfer rates for several reasons, including I/O and network interference, server misconfigurations, and network anomalies. Although understanding the root causes of performance issues is critical to mitigating them and increasing the utilization of expensive network infrastructures, there is currently no available mechanism to monitor data transfers in these networks. In this paper, we present a scalable, end-to-end monitoring framework to gather and store key performance metrics for file transfers to shed light on the performance of transfers. The evaluation results show that the proposed framework can monitor up to 400 transfers per host and more than 40, 000 transfers in total while collecting performance statistics at one-second precision. We also introduce a heuristic method to automatically process the gathered performance metrics and identify the root causes of performance anomalies with an F-score of 87 - 98%.
Tensor Decompositions for Hyperspectral Data Processing in Remote Sensing: A Comprehensive Review
May 13, 2022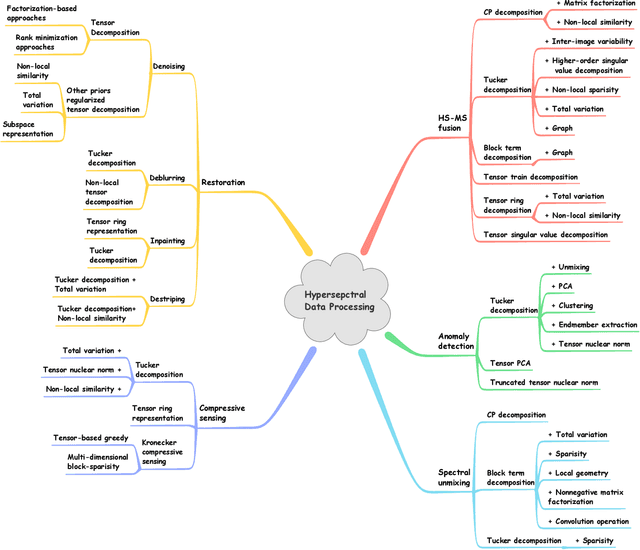



Owing to the rapid development of sensor technology, hyperspectral (HS) remote sensing (RS) imaging has provided a significant amount of spatial and spectral information for the observation and analysis of the Earth's surface at a distance of data acquisition devices, such as aircraft, spacecraft, and satellite. The recent advancement and even revolution of the HS RS technique offer opportunities to realize the full potential of various applications, while confronting new challenges for efficiently processing and analyzing the enormous HS acquisition data. Due to the maintenance of the 3-D HS inherent structure, tensor decomposition has aroused widespread concern and research in HS data processing tasks over the past decades. In this article, we aim at presenting a comprehensive overview of tensor decomposition, specifically contextualizing the five broad topics in HS data processing, and they are HS restoration, compressed sensing, anomaly detection, super-resolution, and spectral unmixing. For each topic, we elaborate on the remarkable achievements of tensor decomposition models for HS RS with a pivotal description of the existing methodologies and a representative exhibition on the experimental results. As a result, the remaining challenges of the follow-up research directions are outlined and discussed from the perspective of the real HS RS practices and tensor decomposition merged with advanced priors and even with deep neural networks. This article summarizes different tensor decomposition-based HS data processing methods and categorizes them into different classes from simple adoptions to complex combinations with other priors for the algorithm beginners. We also expect this survey can provide new investigations and development trends for the experienced researchers who understand tensor decomposition and HS RS to some extent.
Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review
May 03, 2022
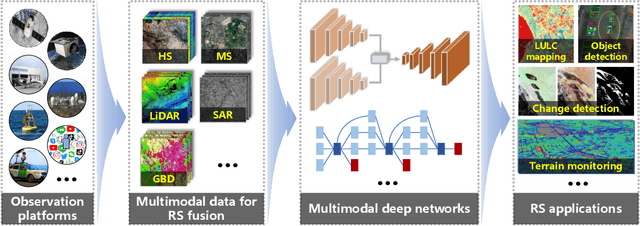
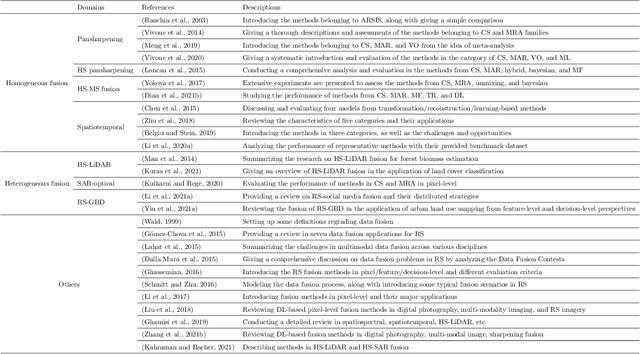
With the extremely rapid advances in remote sensing (RS) technology, a great quantity of Earth observation (EO) data featuring considerable and complicated heterogeneity is readily available nowadays, which renders researchers an opportunity to tackle current geoscience applications in a fresh way. With the joint utilization of EO data, much research on multimodal RS data fusion has made tremendous progress in recent years, yet these developed traditional algorithms inevitably meet the performance bottleneck due to the lack of the ability to comprehensively analyse and interpret these strongly heterogeneous data. Hence, this non-negligible limitation further arouses an intense demand for an alternative tool with powerful processing competence. Deep learning (DL), as a cutting-edge technology, has witnessed remarkable breakthroughs in numerous computer vision tasks owing to its impressive ability in data representation and reconstruction. Naturally, it has been successfully applied to the field of multimodal RS data fusion, yielding great improvement compared with traditional methods. This survey aims to present a systematic overview in DL-based multimodal RS data fusion. More specifically, some essential knowledge about this topic is first given. Subsequently, a literature survey is conducted to analyse the trends of this field. Some prevalent sub-fields in the multimodal RS data fusion are then reviewed in terms of the to-be-fused data modalities, i.e., spatiospectral, spatiotemporal, light detection and ranging-optical, synthetic aperture radar-optical, and RS-Geospatial Big Data fusion. Furthermore, We collect and summarize some valuable resources for the sake of the development in multimodal RS data fusion. Finally, the remaining challenges and potential future directions are highlighted.
Experimental quantum adversarial learning with programmable superconducting qubits
Apr 04, 2022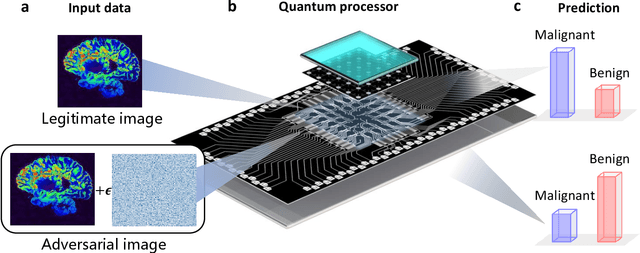
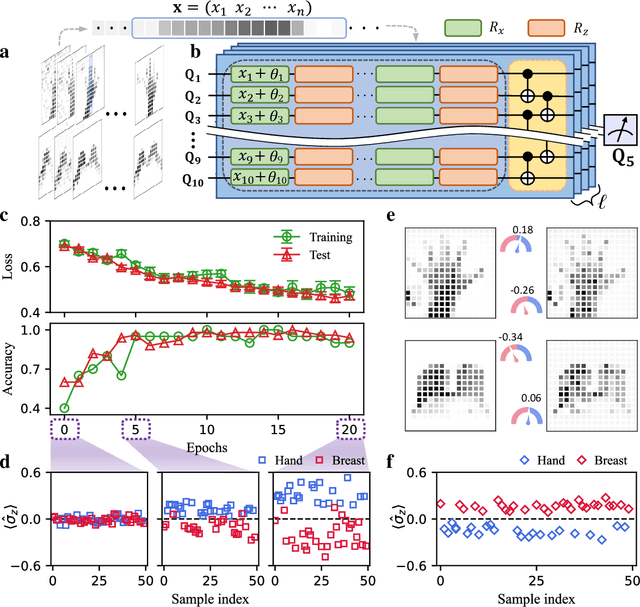
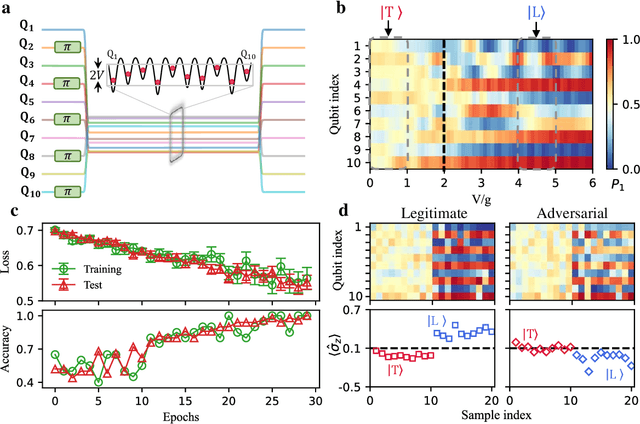
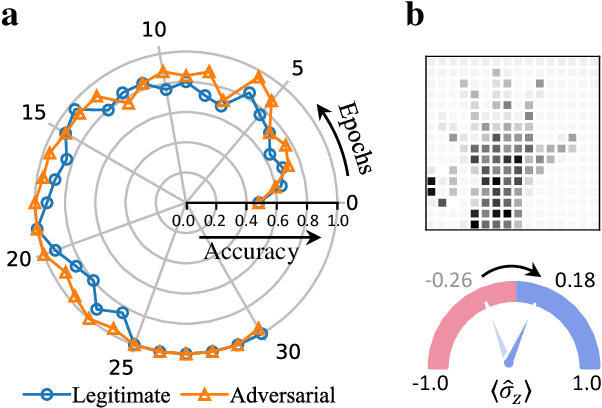
Quantum computing promises to enhance machine learning and artificial intelligence. Different quantum algorithms have been proposed to improve a wide spectrum of machine learning tasks. Yet, recent theoretical works show that, similar to traditional classifiers based on deep classical neural networks, quantum classifiers would suffer from the vulnerability problem: adding tiny carefully-crafted perturbations to the legitimate original data samples would facilitate incorrect predictions at a notably high confidence level. This will pose serious problems for future quantum machine learning applications in safety and security-critical scenarios. Here, we report the first experimental demonstration of quantum adversarial learning with programmable superconducting qubits. We train quantum classifiers, which are built upon variational quantum circuits consisting of ten transmon qubits featuring average lifetimes of 150 $\mu$s, and average fidelities of simultaneous single- and two-qubit gates above 99.94% and 99.4% respectively, with both real-life images (e.g., medical magnetic resonance imaging scans) and quantum data. We demonstrate that these well-trained classifiers (with testing accuracy up to 99%) can be practically deceived by small adversarial perturbations, whereas an adversarial training process would significantly enhance their robustness to such perturbations. Our results reveal experimentally a crucial vulnerability aspect of quantum learning systems under adversarial scenarios and demonstrate an effective defense strategy against adversarial attacks, which provide a valuable guide for quantum artificial intelligence applications with both near-term and future quantum devices.