 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailed Geometry and Appearance from Opportunistic Motion
Mar 27, 2026Reconstructing 3D geometry and appearance from a sparse set of fixed cameras is a foundational task with broad applications, yet it remains fundamentally constrained by the limited viewpoints. We show that this bound can be broken by exploiting opportunistic object motion: as a person manipulates an object~(e.g., moving a chair or lifting a mug), the static cameras effectively ``orbit'' the object in its local coordinate frame, providing additional virtual viewpoints. Harnessing this object motion, however, poses two challenges: the tight coupling of object pose and geometry estimation and the complex appearance variations of a moving object under static illumination. We address these by formulating a joint pose and shape optimization using 2D Gaussian splatting with alternating minimization of 6DoF trajectories and primitive parameters, and by introducing a novel appearance model that factorizes diffuse and specular components with reflected directional probing within the spherical harmonics space. Extensive experiments on synthetic and real-world datasets with extremely sparse viewpoints demonstrate that our method recovers significantly more accurate geometry and appearance than state-of-the-art baselines.
How good was my shot? Quantifying Player Skill Level in Table Tennis
Mar 26, 2026Gauging an individual's skill level is crucial, as it inherently shapes their behavior. Quantifying skill, however, is challenging because it is latent to the observed actions. To explore skill understanding in human behavior, we focus on dyadic sports -- specifically table tennis -- where skill manifests not just in complex movements, but in the subtle nuances of execution conditioned on game context. Our key idea is to learn a generative model of each player's tactical racket strokes and jointly embed them in a common latent space that encodes individual characteristics, including those pertaining to skill levels. By training these player models on a large-scale dataset of 3D-reconstructed professional matches and conditioning them on comprehensive game context -- including player positioning and opponent behaviors -- the models capture individual tactical identities within their latent space. We probe this learned player space and find that it reflects distinct play styles and attributes that collectively represent skill. By training a simple relative ranking network on these embeddings, we demonstrate that both relative and absolute skill predictions can be achieved. These results demonstrate that the learned player space effectively quantifies skill levels, providing a foundation for automated skill assessment in complex, interactive behaviors.
Under One Sun: Multi-Object Generative Perception of Materials and Illumination
Mar 19, 2026We introduce Multi-Object Generative Perception (MultiGP), a generative inverse rendering method for stochastic sampling of all radiometric constituents -- reflectance, texture, and illumination -- underlying object appearance from a single image. Our key idea to solve this inherently ambiguous radiometric disentanglement is to leverage the fact that while their texture and reflectance may differ, objects in the same scene are all lit by the same illumination. MultiGP exploits this consensus to produce samples of reflectance, texture, and illumination from a single image of known shapes based on four key technical contributions: a cascaded end-to-end architecture that combines image-space and angular-space disentanglement; Coordinated Guidance for diffusion convergence to a single consistent illumination estimate; Axial Attention applied to facilitate ``cross-talk'' between objects of different reflectance; and a Texture Extraction ControlNet to preserve high-frequency texture details while ensuring decoupling from estimated lighting. Experimental results demonstrate that MultiGP effectively leverages the complementary spatial and frequency characteristics of multiple object appearances to recover individual texture and reflectance as well as the common illumination.
M-PhyGs: Multi-Material Object Dynamics from Video
Dec 18, 2025Knowledge of the physical material properties governing the dynamics of a real-world object becomes necessary to accurately anticipate its response to unseen interactions. Existing methods for estimating such physical material parameters from visual data assume homogeneous single-material objects, pre-learned dynamics, or simplistic topologies. Real-world objects, however, are often complex in material composition and geometry lying outside the realm of these assumptions. In this paper, we particularly focus on flowers as a representative common object. We introduce Multi-material Physical Gaussians (M-PhyGs) to estimate the material composition and parameters of such multi-material complex natural objects from video. From a short video captured in a natural setting, M-PhyGs jointly segments the object into similar materials and recovers their continuum mechanical parameters while accounting for gravity. M-PhyGs achieves this efficiently with newly introduced cascaded 3D and 2D losses, and by leveraging temporal mini-batching. We introduce a dataset, Phlowers, of people interacting with flowers as a novel platform to evaluate the accuracy of this challenging task of multi-material physical parameter estimation. Experimental results on Phlowers dataset demonstrate the accuracy and effectiveness of M-PhyGs and its components.
Single-Shot Shape and Reflectance with Spatial Polarization Multiplexing
Apr 17, 2025



We propose spatial polarization multiplexing (SPM) for reconstructing object shape and reflectance from a single polarimetric image and demonstrate its application to dynamic surface recovery. Although single-pattern structured light enables single-shot shape reconstruction, the reflectance is challenging to recover due to the lack of angular sampling of incident light and the entanglement of the projected pattern and the surface color texture. We design a spatially multiplexed pattern of polarization that can be robustly and uniquely decoded for shape reconstruction by quantizing the AoLP values. At the same time, our spatial-multiplexing enables single-shot ellipsometry of linear polarization by projecting differently polarized light within a local region, which separates the specular and diffuse reflections for BRDF estimation. We achieve this spatial polarization multiplexing with a constrained de Bruijn sequence. Unlike single-pattern structured light with intensity and color, our polarization pattern is invisible to the naked eye and retains the natural surface appearance which is essential for accurate appearance modeling and also interaction with people. We experimentally validate our method on real data. The results show that our method can recover the shape, the Mueller matrix, and the BRDF from a single-shot polarimetric image. We also demonstrate the application of our method to dynamic surfaces.
Enterprise Benchmarks for Large Language Model Evaluation
Oct 11, 2024



The advancement of large language models (LLMs) has led to a greater challenge of having a rigorous and systematic evaluation of complex tasks performed, especially in enterprise applications. Therefore, LLMs need to be able to benchmark enterprise datasets for various tasks. This work presents a systematic exploration of benchmarking strategies tailored to LLM evaluation, focusing on the utilization of domain-specific datasets and consisting of a variety of NLP tasks. The proposed evaluation framework encompasses 25 publicly available datasets from diverse enterprise domains like financial services, legal, cyber security, and climate and sustainability. The diverse performance of 13 models across different enterprise tasks highlights the importance of selecting the right model based on the specific requirements of each task. Code and prompts are available on GitHub.
Privacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.
Towards Federated Graph Learning for Collaborative Financial Crimes Detection
Oct 02, 2019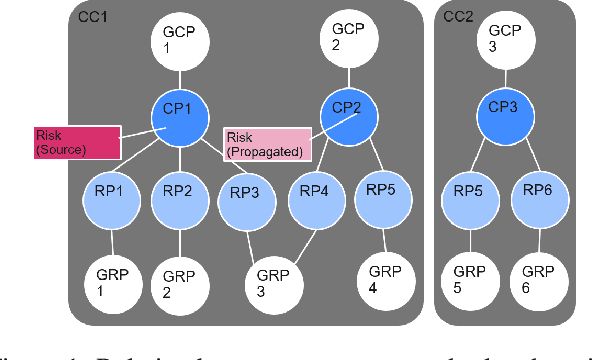
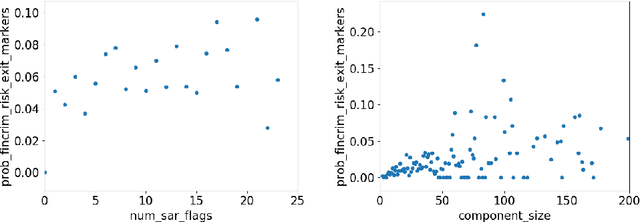
Financial crime is a large and growing problem, in some way touching almost every financial institution. Financial institutions are the front line in the war against financial crime and accordingly, must devote substantial human and technology resources to this effort. Current processes to detect financial misconduct have limitations in their ability to effectively differentiate between malicious behavior and ordinary financial activity. These limitations tend to result in gross over-reporting of suspicious activity that necessitate time-intensive and costly manual review. Advances in technology used in this domain, including machine learning based approaches, can improve upon the effectiveness of financial institutions' existing processes, however, a key challenge that most financial institutions continue to face is that they address financial crimes in isolation without any insight from other firms. Where financial institutions address financial crimes through the lens of their own firm, perpetrators may devise sophisticated strategies that may span across institutions and geographies. Financial institutions continue to work relentlessly to advance their capabilities, forming partnerships across institutions to share insights, patterns and capabilities. These public-private partnerships are subject to stringent regulatory and data privacy requirements, thereby making it difficult to rely on traditional technology solutions. In this paper, we propose a methodology to share key information across institutions by using a federated graph learning platform that enables us to build more accurate machine learning models by leveraging federated learning and also graph learning approaches. We demonstrated that our federated model outperforms local model by 20% with the UK FCA TechSprint data set. This new platform opens up a door to efficiently detecting global money laundering activity.
Shape from Water Reflection
Jun 25, 2019
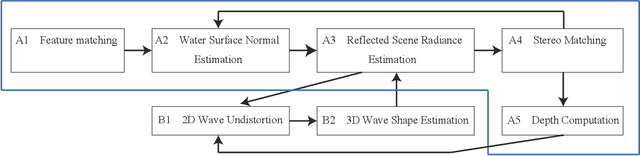
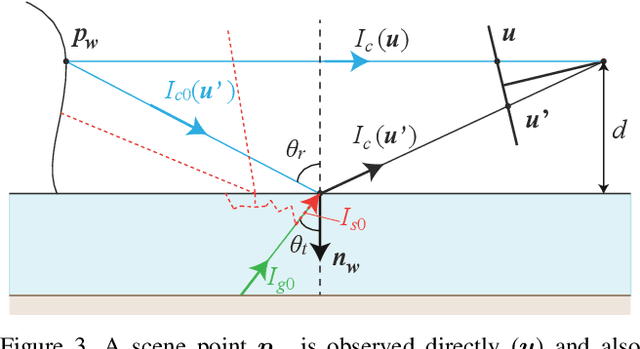

This paper introduces single-image 3D scene reconstruction from water reflection photography, i.e., images capturing direct and water-reflected real-world scenes. Water reflection offers an additional viewpoint to the direct sight, collectively forming a stereo pair. The water-reflected scene, however, includes internally scattered and reflected environmental illumination in addition to the scene radiance, which precludes direct stereo matching. We derive a principled iterative method that disentangles this scene radiometry and geometry for reconstructing 3D scene structure as well as its high-dynamic range appearance. In the presence of waves, we simultaneously recover the wave geometry as surface normal perturbations of the water surface. Most important, we show that the water reflection enables calibration of the camera. In other words, we show that capturing a direct and water-reflected scene in a single exposure forms a self-calibrating catadioptric stereo camera. We demonstrate our method on a number of images taken in the wild. The results demonstrate a new means for leveraging this accidental catadioptric camera.