 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Anomaly Detection for Big Time Series of Industrial Sensors
Apr 18, 2022
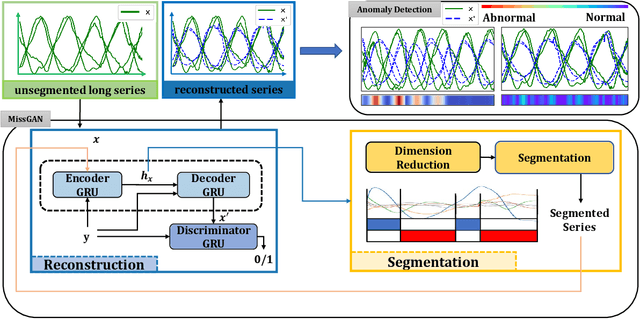
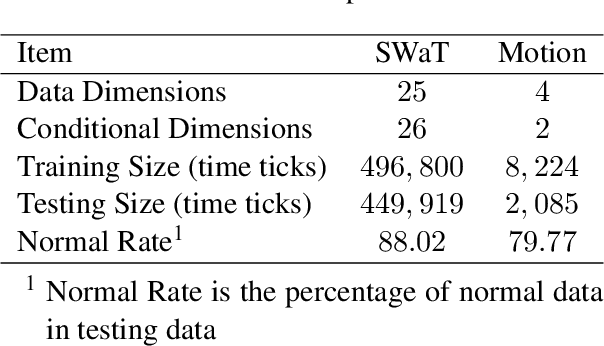
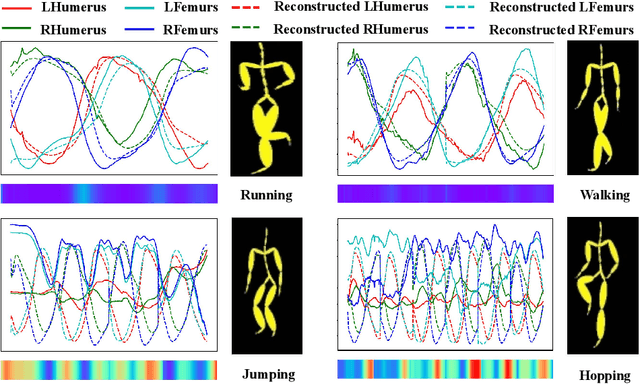
Given a multivariate big time series, can we detect anomalies as soon as they occur? Many existing works detect anomalies by learning how much a time series deviates away from what it should be in the reconstruction framework. However, most models have to cut the big time series into small pieces empirically since optimization algorithms cannot afford such a long series. The question is raised: do such cuts pollute the inherent semantic segments, like incorrect punctuation in sentences? Therefore, we propose a reconstruction-based anomaly detection method, MissGAN, iteratively learning to decode and encode naturally smooth time series in coarse segments, and finding out a finer segment from low-dimensional representations based on HMM. As a result, learning from multi-scale segments, MissGAN can reconstruct a meaningful and robust time series, with the help of adversarial regularization and extra conditional states. MissGAN does not need labels or only needs labels of normal instances, making it widely applicable. Experiments on industrial datasets of real water network sensors show our MissGAN outperforms the baselines with scalability. Besides, we use a case study on the CMU Motion dataset to demonstrate that our model can well distinguish unexpected gestures from a given conditional motion.
Autofocus for Event Cameras
Mar 23, 2022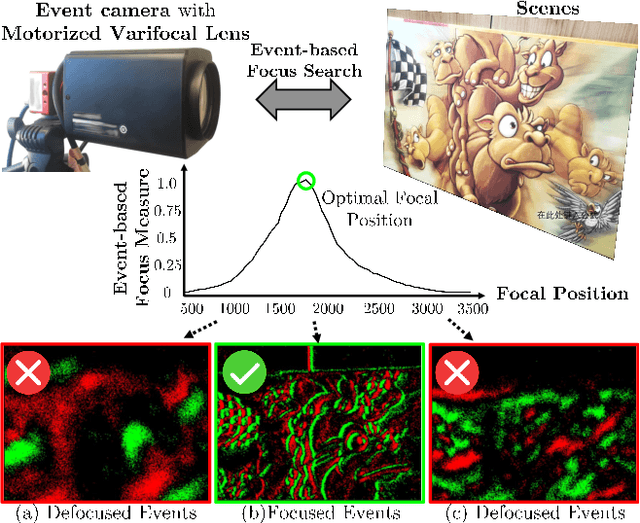
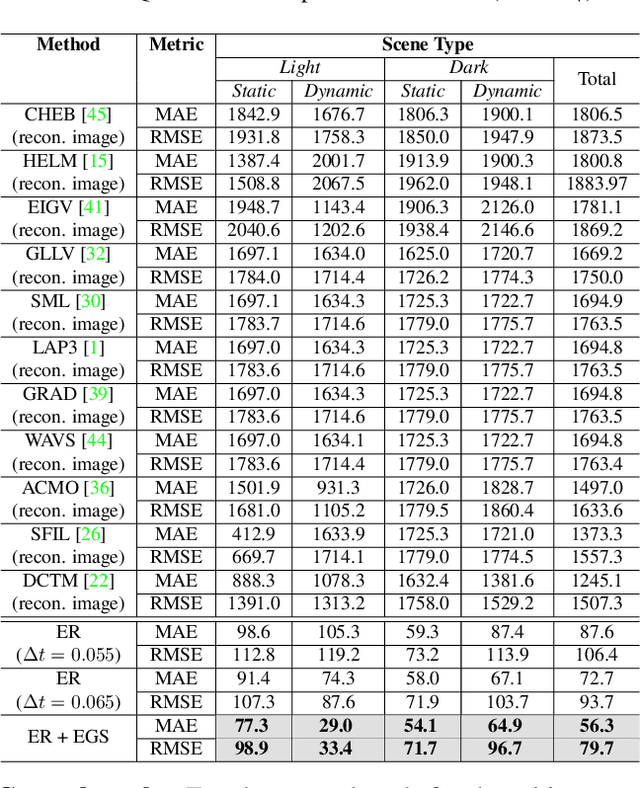


Focus control (FC) is crucial for cameras to capture sharp images in challenging real-world scenarios. The autofocus (AF) facilitates the FC by automatically adjusting the focus settings. However, due to the lack of effective AF methods for the recently introduced event cameras, their FC still relies on naive AF like manual focus adjustments, leading to poor adaptation in challenging real-world conditions. In particular, the inherent differences between event and frame data in terms of sensing modality, noise, temporal resolutions, etc., bring many challenges in designing an effective AF method for event cameras. To address these challenges, we develop a novel event-based autofocus framework consisting of an event-specific focus measure called event rate (ER) and a robust search strategy called event-based golden search (EGS). To verify the performance of our method, we have collected an event-based autofocus dataset (EAD) containing well-synchronized frames, events, and focal positions in a wide variety of challenging scenes with severe lighting and motion conditions. The experiments on this dataset and additional real-world scenarios demonstrated the superiority of our method over state-of-the-art approaches in terms of efficiency and accuracy.
Learning Semantic Abstraction of Shape via 3D Region of Interest
Jan 13, 2022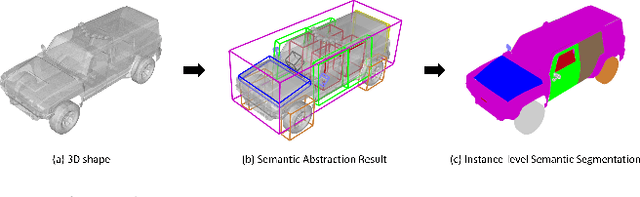
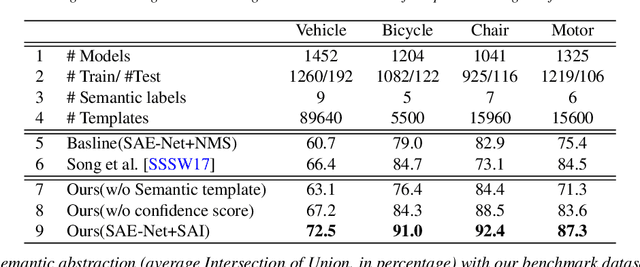
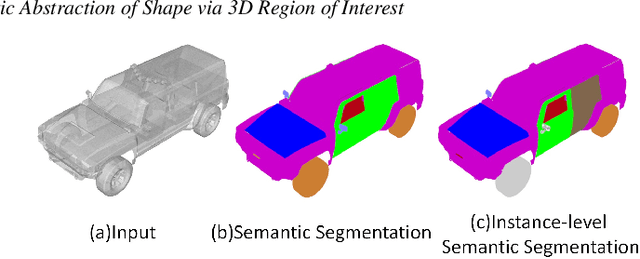
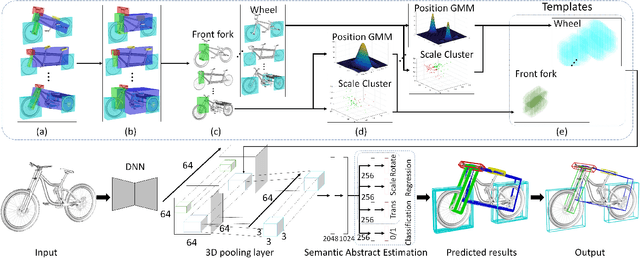
In this paper, we focus on the two tasks of 3D shape abstraction and semantic analysis. This is in contrast to current methods, which focus solely on either 3D shape abstraction or semantic analysis. In addition, previous methods have had difficulty producing instance-level semantic results, which has limited their application. We present a novel method for the joint estimation of a 3D shape abstraction and semantic analysis. Our approach first generates a number of 3D semantic candidate regions for a 3D shape; we then employ these candidates to directly predict the semantic categories and refine the parameters of the candidate regions simultaneously using a deep convolutional neural network. Finally, we design an algorithm to fuse the predicted results and obtain the final semantic abstraction, which is shown to be an improvement over a standard non maximum suppression. Experimental results demonstrate that our approach can produce state-of-the-art results. Moreover, we also find that our results can be easily applied to instance-level semantic part segmentation and shape matching.
A novel time delay estimation algorithm of acoustic pyrometry for furnace
Nov 25, 2021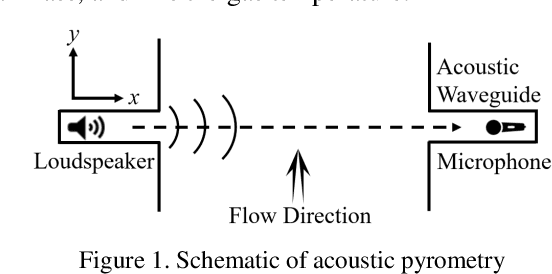
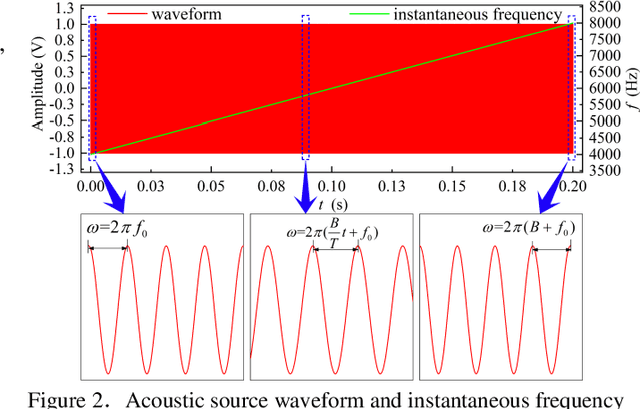
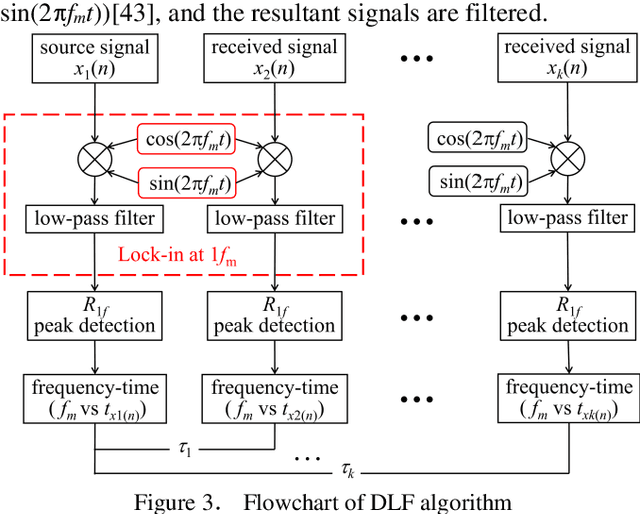
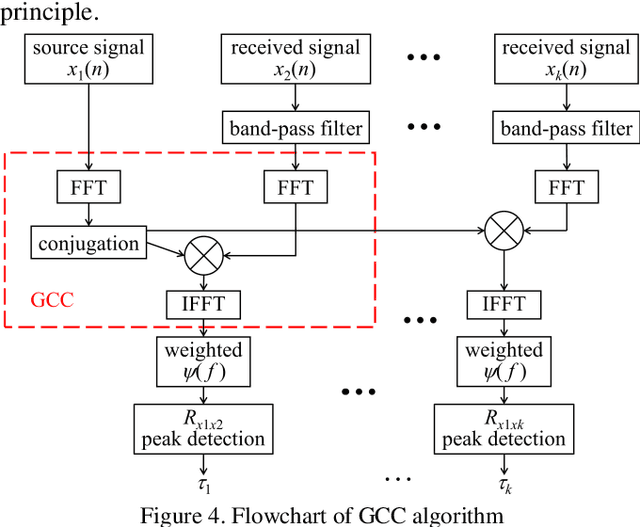
Acoustic pyrometry is a non-contact measurement technology for monitoring furnace combustion reaction, diagnosing energy loss due to incomplete combustion and ensuring safe production. The accuracy of time of flight (TOF) estimation of an acoustic pyrometry directly affects the authenticity of furnace temperature measurement. In this paper presented is a novel TOF (i.e. time delay) estimation algorithm based on digital lock-in filtering (DLF) algorithm. In this research, the time-frequency relationship between the first harmonic of the acoustic signal and the moment of characteristic frequency applied is established through the digital lock-in and low-pass filtering techniques. The accurate estimation of TOF is obtained by extracting and comparing the temporal relationship of the characteristic frequency occurrence between received and source acoustic signals. The computational error analysis indicates that the accuracy of the proposed algorithm is better than that of the classical generalized cross-correlation (GCC) algorithm, and the computational effort is significantly reduced to half of that the GCC can offer. It can be confirmed that with this method, the temperature measurement in furnaces can be improved in terms of computational effort and accuracy, which are vital parameters in furnace combustion control. It provides a new idea of time delay estimation with the utilization of acoustic pyrometry for furnace.
Awakening Latent Grounding from Pretrained Language Models for Semantic Parsing
Sep 22, 2021
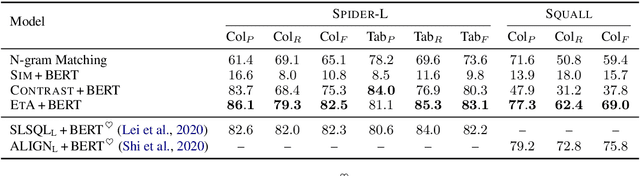
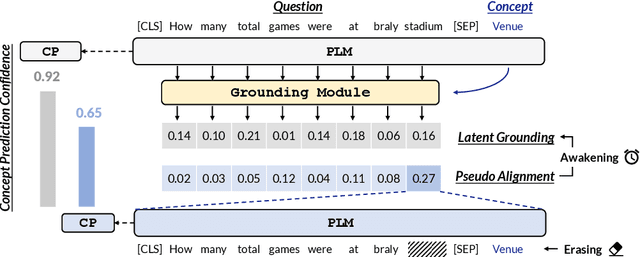
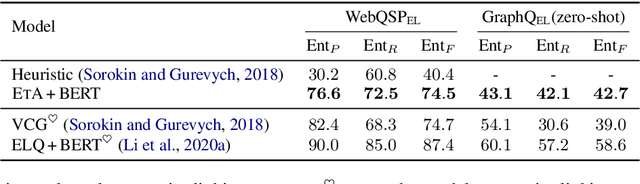
Recent years pretrained language models (PLMs) hit a success on several downstream tasks, showing their power on modeling language. To better understand and leverage what PLMs have learned, several techniques have emerged to explore syntactic structures entailed by PLMs. However, few efforts have been made to explore grounding capabilities of PLMs, which are also essential. In this paper, we highlight the ability of PLMs to discover which token should be grounded to which concept, if combined with our proposed erasing-then-awakening approach. Empirical studies on four datasets demonstrate that our approach can awaken latent grounding which is understandable to human experts, even if it is not exposed to such labels during training. More importantly, our approach shows great potential to benefit downstream semantic parsing models. Taking text-to-SQL as a case study, we successfully couple our approach with two off-the-shelf parsers, obtaining an absolute improvement of up to 9.8%.
Indoor Scene Generation from a Collection of Semantic-Segmented Depth Images
Aug 20, 2021
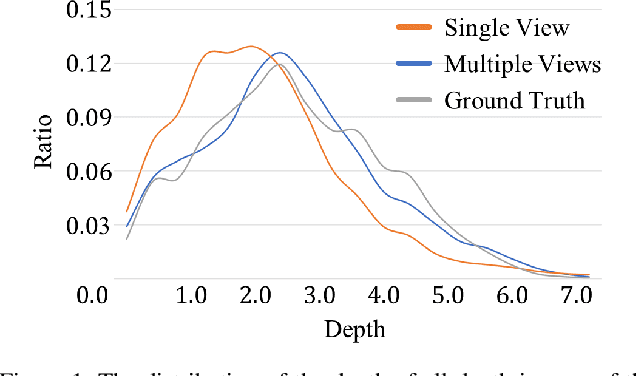
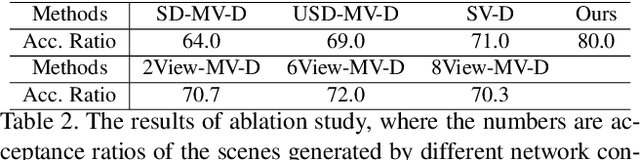
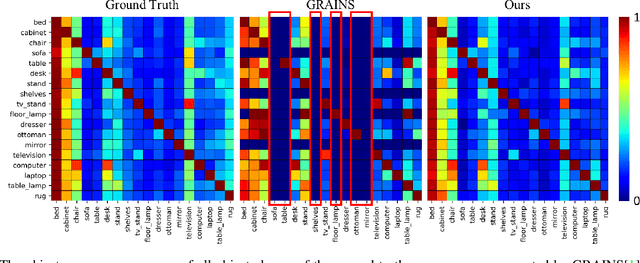
We present a method for creating 3D indoor scenes with a generative model learned from a collection of semantic-segmented depth images captured from different unknown scenes. Given a room with a specified size, our method automatically generates 3D objects in a room from a randomly sampled latent code. Different from existing methods that represent an indoor scene with the type, location, and other properties of objects in the room and learn the scene layout from a collection of complete 3D indoor scenes, our method models each indoor scene as a 3D semantic scene volume and learns a volumetric generative adversarial network (GAN) from a collection of 2.5D partial observations of 3D scenes. To this end, we apply a differentiable projection layer to project the generated 3D semantic scene volumes into semantic-segmented depth images and design a new multiple-view discriminator for learning the complete 3D scene volume from 2.5D semantic-segmented depth images. Compared to existing methods, our method not only efficiently reduces the workload of modeling and acquiring 3D scenes for training, but also produces better object shapes and their detailed layouts in the scene. We evaluate our method with different indoor scene datasets and demonstrate the advantages of our method. We also extend our method for generating 3D indoor scenes from semantic-segmented depth images inferred from RGB images of real scenes.
High-Efficiency Resonant Beam Charging and Communication
Jul 30, 2021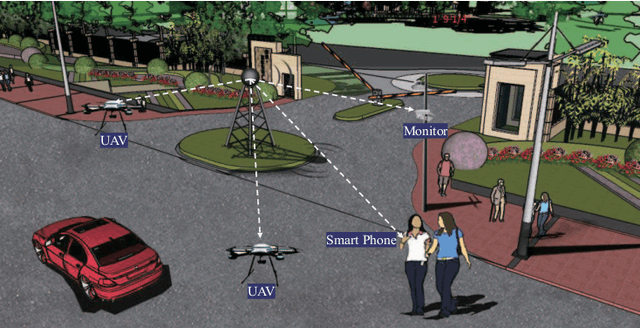
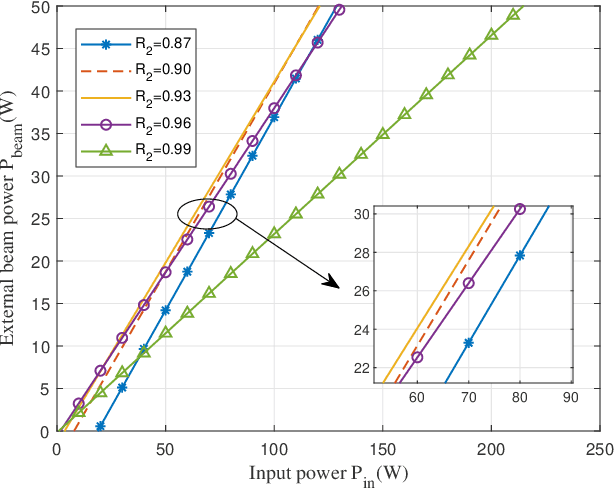
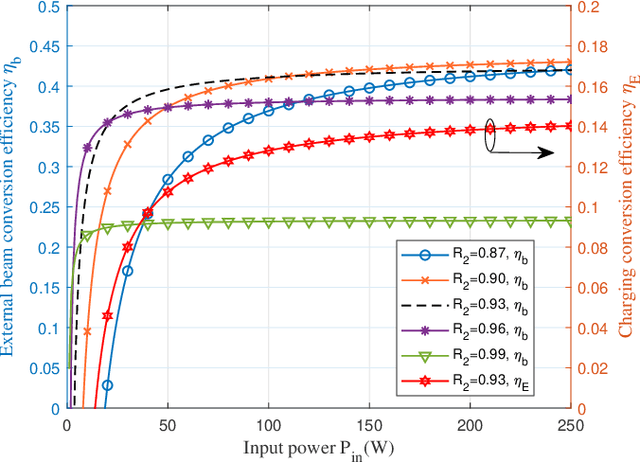
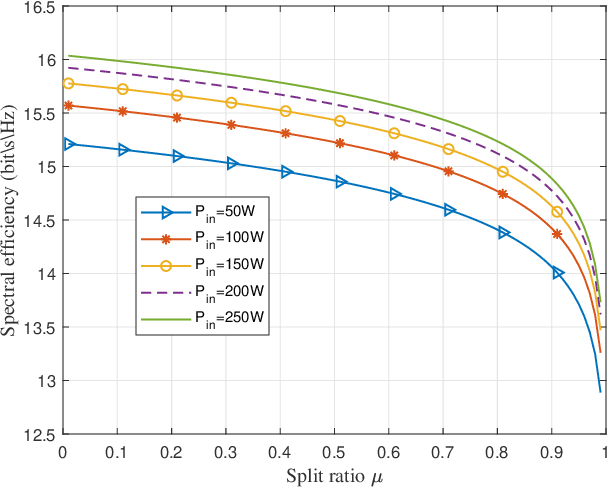
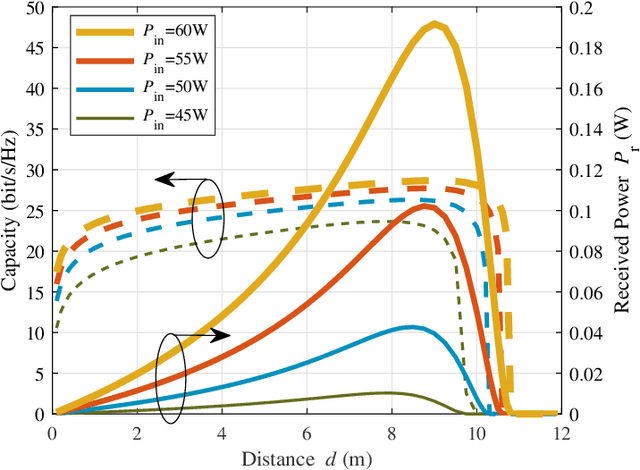
Simultaneous wireless information and power transfer (SWIPT) has been envisioned as an enabling technology for future 6G by providing high-efficiency power transfer and high-rate data transmissions concurrently. In this paper, we propose a resonant beam charging and communication (RBCC) system utilizing the telescope internal modulator (TIM) and the semiconductor gain medium. TIM can concentrate the diverged beam into a small-size gain module, thus the propagation loss is reduced and the transmission efficiency is enhanced. Since the semiconductor gain medium has better energy absorption capacity compared with the traditional solid-state one, the overall energy conversion efficiency can be improved. We establish an analytical model of this RBCC system for SWIPT and evaluate its stability, output energy, and spectral efficiency. Numerical analysis shows that the proposed RBCC system can realize stable SWIPT over 10 meters, whose energy conversion efficiency is increased by 14 times compared with the traditional system using the solid-state gain medium without TIM, and the spectrum efficiency can be above 15 bit/s/Hz.
A Cloud-Edge-Terminal Collaborative System for Temperature Measurement in COVID-19 Prevention
Jul 11, 2021
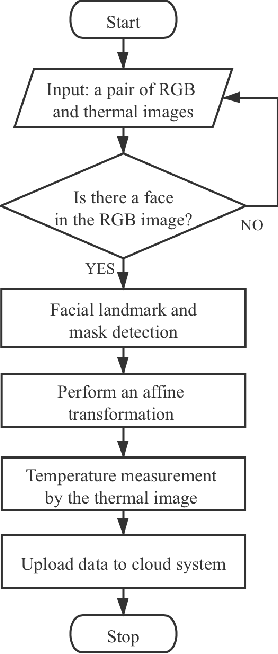
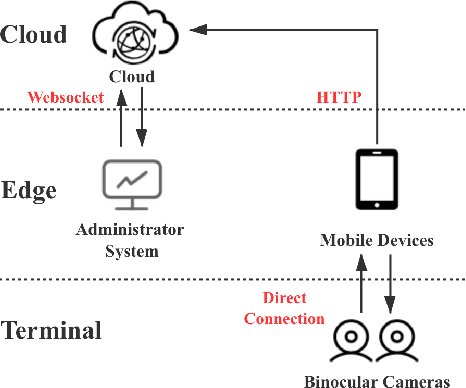

To prevent the spread of coronavirus disease 2019 (COVID-19), preliminary temperature measurement and mask detection in public areas are conducted. However, the existing temperature measurement methods face the problems of safety and deployment. In this paper, to realize safe and accurate temperature measurement even when a person's face is partially obscured, we propose a cloud-edge-terminal collaborative system with a lightweight infrared temperature measurement model. A binocular camera with an RGB lens and a thermal lens is utilized to simultaneously capture image pairs. Then, a mobile detection model based on a multi-task cascaded convolutional network (MTCNN) is proposed to realize face alignment and mask detection on the RGB images. For accurate temperature measurement, we transform the facial landmarks on the RGB images to the thermal images by an affine transformation and select a more accurate temperature measurement area on the forehead. The collected information is uploaded to the cloud in real time for COVID-19 prevention. Experiments show that the detection model is only 6.1M and the average detection speed is 257ms. At a distance of 1m, the error of indoor temperature measurement is about 3%. That is, the proposed system can realize real-time temperature measurement in public areas.
Mobile Optical Communications Using Second Harmonic of Intra-Cavity Laser
Jun 21, 2021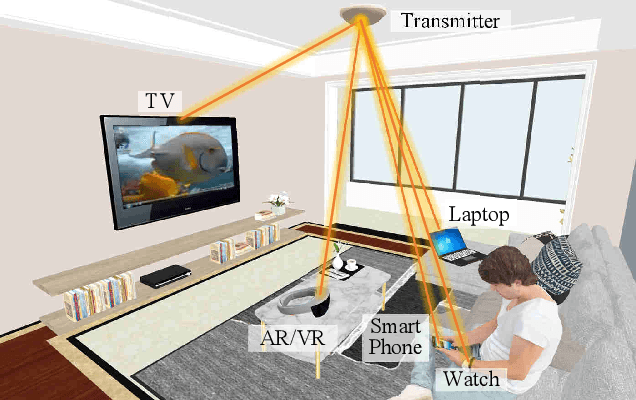
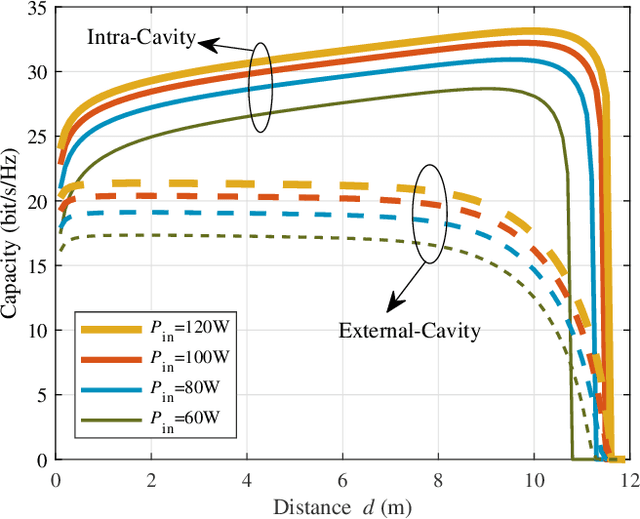
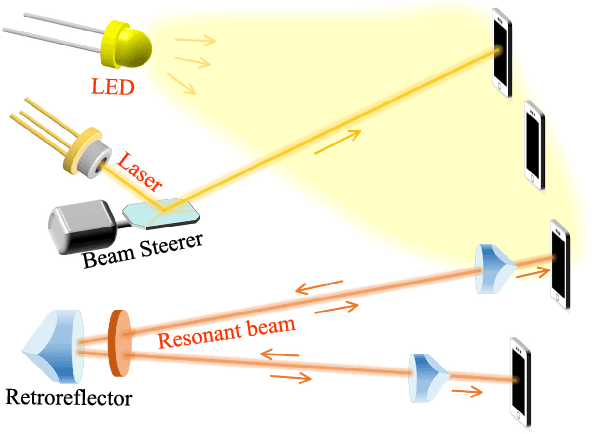
Optical wireless communication (OWC) meets the demands of the future six-generation mobile network (6G) as it operates at several hundreds of Terahertz and has the potential to enable data rate in the order of Tbps. However, most beam-steering OWC technologies require high-accuracy positioning and high-speed control. Resonant beam communication (RBCom), as one kind of non-positioning OWC technologies, has been proposed for high-rate mobile communications. The mobility of RBCom relies on its self-alignment characteristic where no positioning is required. In a previous study, an external-cavity second-harmonic-generation (SHG) RBCom system has been proposed for eliminating the echo interference inside the resonator. However, its energy conversion efficiency and complexity are of concern. In this paper, we propose an intra-cavity SHG RBCom system to simplify the system design and improve the energy conversion efficiency. We elaborate the system structure and establish an analytical model. Numerical results show that the energy consumption of the proposed intra-cavity design is reduced to reach the same level of channel capacity at the receiver compared with the external-cavity one.
Learning Fine-Grained Segmentation of 3D Shapes without Part Labels
Mar 24, 2021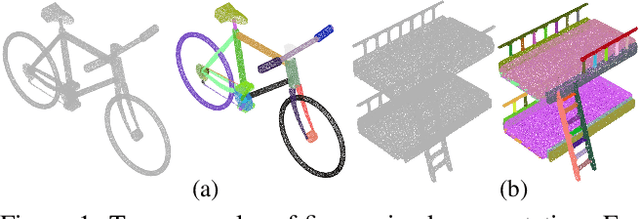
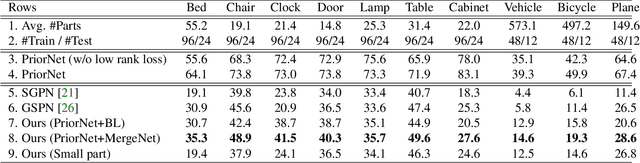
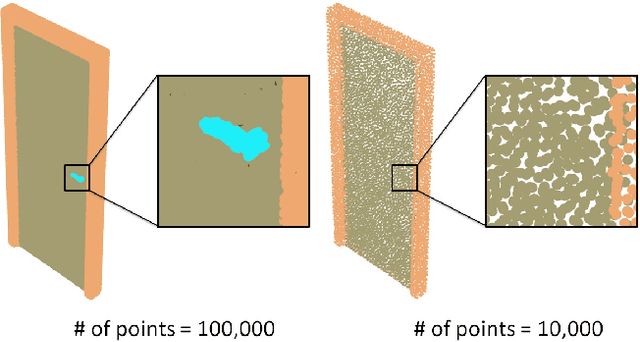
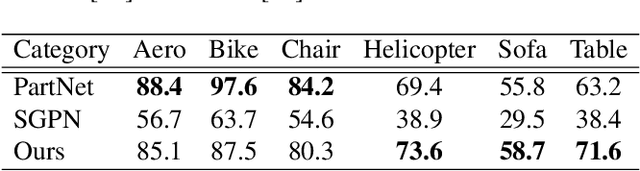
Learning-based 3D shape segmentation is usually formulated as a semantic labeling problem, assuming that all parts of training shapes are annotated with a given set of tags. This assumption, however, is impractical for learning fine-grained segmentation. Although most off-the-shelf CAD models are, by construction, composed of fine-grained parts, they usually miss semantic tags and labeling those fine-grained parts is extremely tedious. We approach the problem with deep clustering, where the key idea is to learn part priors from a shape dataset with fine-grained segmentation but no part labels. Given point sampled 3D shapes, we model the clustering priors of points with a similarity matrix and achieve part segmentation through minimizing a novel low rank loss. To handle highly densely sampled point sets, we adopt a divide-and-conquer strategy. We partition the large point set into a number of blocks. Each block is segmented using a deep-clustering-based part prior network trained in a category-agnostic manner. We then train a graph convolution network to merge the segments of all blocks to form the final segmentation result. Our method is evaluated with a challenging benchmark of fine-grained segmentation, showing state-of-the-art performance.