 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Satellite Object Localization with Dilated Convolutions and Attention-aided Spatial Pooling
May 08, 2025



Object localization in satellite imagery is particularly challenging due to the high variability of objects, low spatial resolution, and interference from noise and dominant features such as clouds and city lights. In this research, we focus on three satellite datasets: upper atmospheric Gravity Waves (GW), mesospheric Bores (Bore), and Ocean Eddies (OE), each presenting its own unique challenges. These challenges include the variability in the scale and appearance of the main object patterns, where the size, shape, and feature extent of objects of interest can differ significantly. To address these challenges, we introduce YOLO-DCAP, a novel enhanced version of YOLOv5 designed to improve object localization in these complex scenarios. YOLO-DCAP incorporates a Multi-scale Dilated Residual Convolution (MDRC) block to capture multi-scale features at scale with varying dilation rates, and an Attention-aided Spatial Pooling (AaSP) module to focus on the global relevant spatial regions, enhancing feature selection. These structural improvements help to better localize objects in satellite imagery. Experimental results demonstrate that YOLO-DCAP significantly outperforms both the YOLO base model and state-of-the-art approaches, achieving an average improvement of 20.95% in mAP50 and 32.23% in IoU over the base model, and 7.35% and 9.84% respectively over state-of-the-art alternatives, consistently across all three satellite datasets. These consistent gains across all three satellite datasets highlight the robustness and generalizability of the proposed approach. Our code is open sourced at https://github.com/AI-4-atmosphere-remote-sensing/satellite-object-localization.
gWaveNet: Classification of Gravity Waves from Noisy Satellite Data using Custom Kernel Integrated Deep Learning Method
Aug 26, 2024Atmospheric gravity waves occur in the Earths atmosphere caused by an interplay between gravity and buoyancy forces. These waves have profound impacts on various aspects of the atmosphere, including the patterns of precipitation, cloud formation, ozone distribution, aerosols, and pollutant dispersion. Therefore, understanding gravity waves is essential to comprehend and monitor changes in a wide range of atmospheric behaviors. Limited studies have been conducted to identify gravity waves from satellite data using machine learning techniques. Particularly, without applying noise removal techniques, it remains an underexplored area of research. This study presents a novel kernel design aimed at identifying gravity waves within satellite images. The proposed kernel is seamlessly integrated into a deep convolutional neural network, denoted as gWaveNet. Our proposed model exhibits impressive proficiency in detecting images containing gravity waves from noisy satellite data without any feature engineering. The empirical results show our model outperforms related approaches by achieving over 98% training accuracy and over 94% test accuracy which is known to be the best result for gravity waves detection up to the time of this work. We open sourced our code at https://rb.gy/qn68ku.
Modeling e-Learners' Cognitive and Metacognitive Strategy in Comparative Question Solving
Jun 04, 2019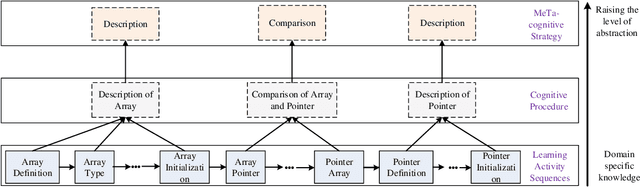
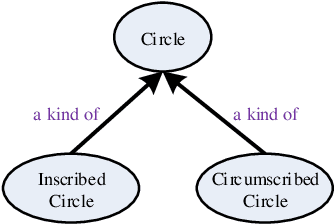
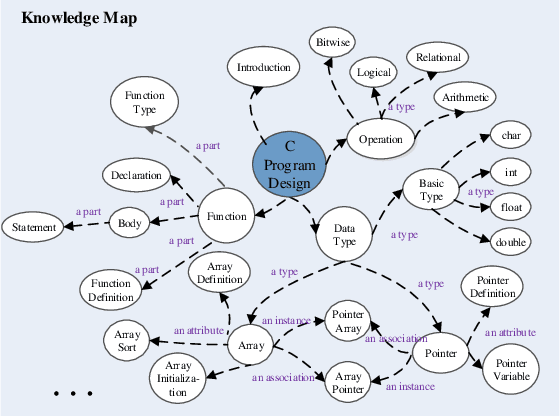
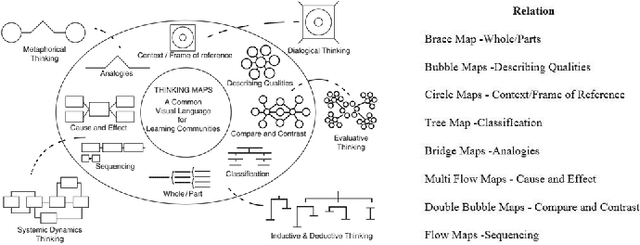
Cognitive and metacognitive strategy had demonstrated a significant role in self-regulated learning (SRL), and an appropriate use of strategies is beneficial to effective learning or question-solving tasks during a human-computer interaction process. This paper proposes a novel method combining Knowledge Map (KM) based data mining technique with Thinking Map (TM) to detect learner's cognitive and metacognitive strategy in the question-solving scenario. In particular, a graph-based mining algorithm is designed to facilitate our proposed method, which can automatically map cognitive strategy to metacognitive strategy with raising abstraction level, and make the cognitive and metacognitive process viewable, which acts like a reverse engineering engine to explain how a learner thinks when solving a question. Additionally, we develop an online learning environment system for participants to learn and record their behaviors. To corroborate the effectiveness of our approach and algorithm, we conduct experiments recruiting 173 postgraduate and undergraduate students, and they were asked to complete a question-solving task, such as "What are similarities and differences between array and pointer?" from "The C Programming Language" course and "What are similarities and differences between packet switching and circuit switching?" from "Computer Network Principle" course. The mined strategies patterns results are encouraging and supported well our proposed method.
Learning Unit State Recognition Based on Multi-channel Data Fusion
May 25, 2018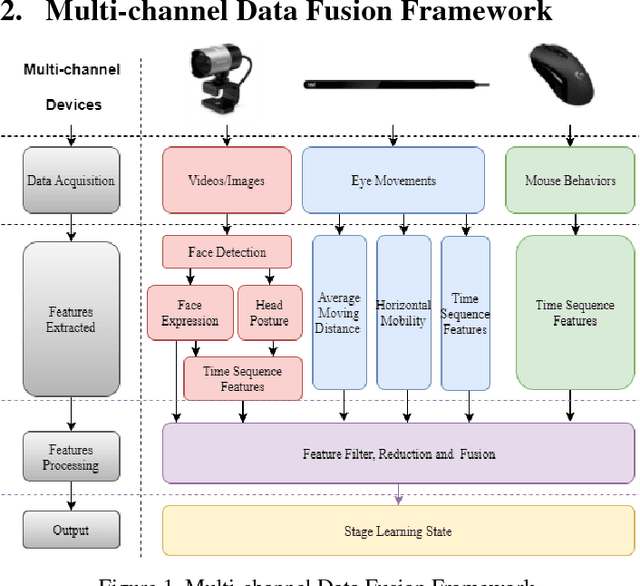
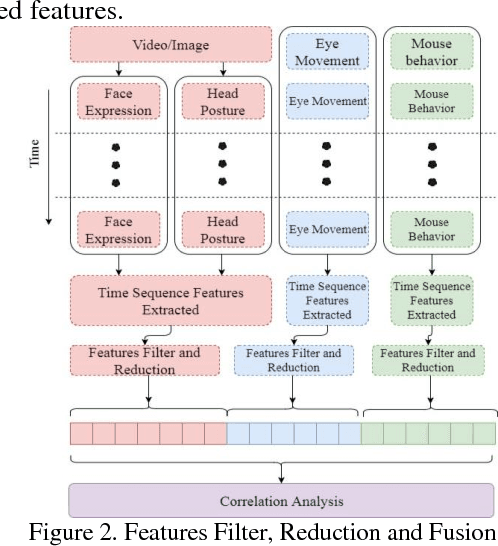
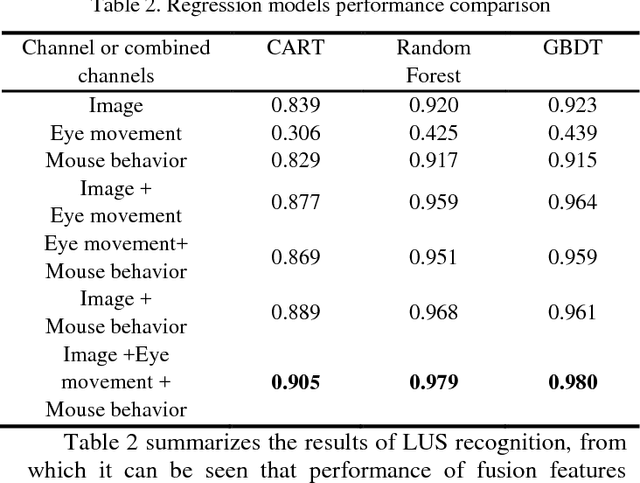
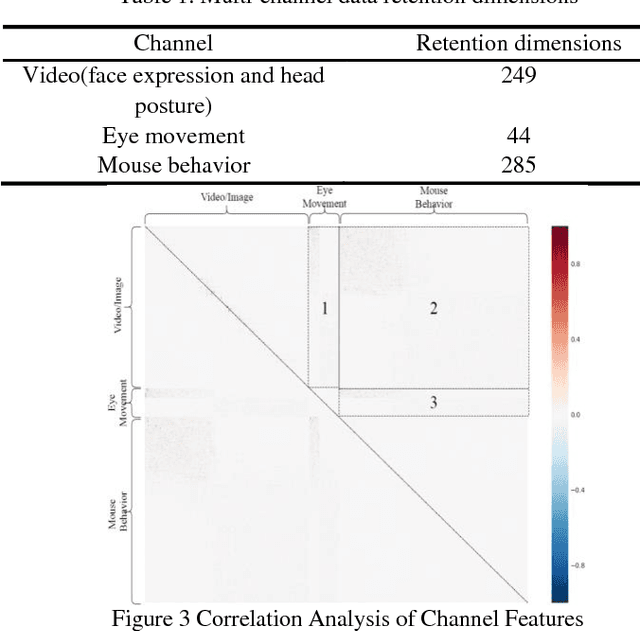
Despite recent advances in MOOC, the current e-learning systems have advantages of alleviating barriers by time differences, and geographically spatial separation between teachers and students. However, there has been a 'lack of supervision' problem that e-learner's learning unit state(LUS) can't be supervised automatically. In this paper, we present a fusion framework considering three channel data sources: 1) videos/images from a camera, 2) eye movement information tracked by a low solution eye tracker and 3) mouse movement. Based on these data modalities, we propose a novel approach of multi-channel data fusion to explore the learning unit state recognition. We also propose a method to build a learning state recognition model to avoid manually labeling image data. The experiments were carried on our designed online learning prototype system, and we choose CART, Random Forest and GBDT regression model to predict e-learner's learning state. The results show that multi-channel data fusion model have a better recognition performance in comparison with single channel model. In addition, a best recognition performance can be reached when image, eye movement and mouse movement features are fused.