 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Safety Detectors Aren't Enough: A Stealthy and Effective Jailbreak Attack on LLMs via Steganographic Techniques
May 22, 2025



Jailbreak attacks pose a serious threat to large language models (LLMs) by bypassing built-in safety mechanisms and leading to harmful outputs. Studying these attacks is crucial for identifying vulnerabilities and improving model security. This paper presents a systematic survey of jailbreak methods from the novel perspective of stealth. We find that existing attacks struggle to simultaneously achieve toxic stealth (concealing toxic content) and linguistic stealth (maintaining linguistic naturalness). Motivated by this, we propose StegoAttack, a fully stealthy jailbreak attack that uses steganography to hide the harmful query within benign, semantically coherent text. The attack then prompts the LLM to extract the hidden query and respond in an encrypted manner. This approach effectively hides malicious intent while preserving naturalness, allowing it to evade both built-in and external safety mechanisms. We evaluate StegoAttack on four safety-aligned LLMs from major providers, benchmarking against eight state-of-the-art methods. StegoAttack achieves an average attack success rate (ASR) of 92.00%, outperforming the strongest baseline by 11.0%. Its ASR drops by less than 1% even under external detection (e.g., Llama Guard). Moreover, it attains the optimal comprehensive scores on stealth detection metrics, demonstrating both high efficacy and exceptional stealth capabilities. The code is available at https://anonymous.4open.science/r/StegoAttack-Jail66
Your Fixed Watermark is Fragile: Towards Semantic-Aware Watermark for EaaS Copyright Protection
Nov 14, 2024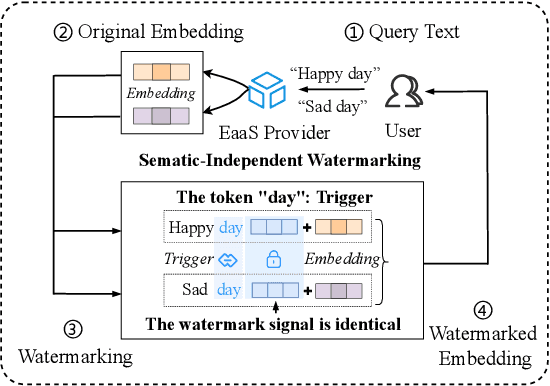
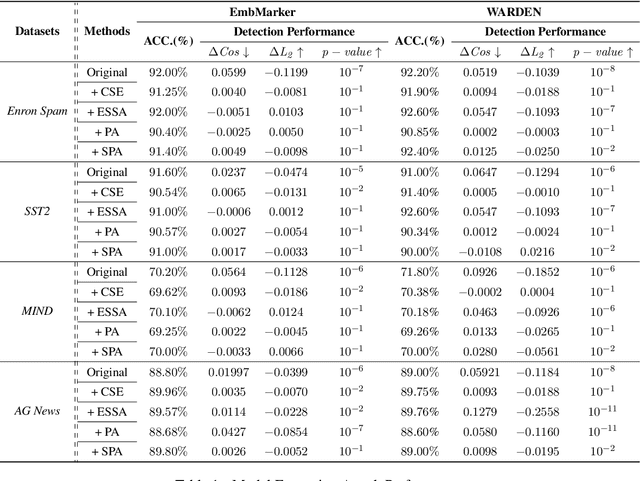
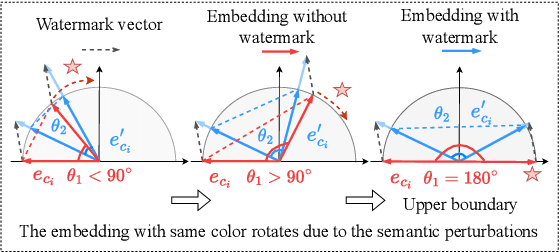
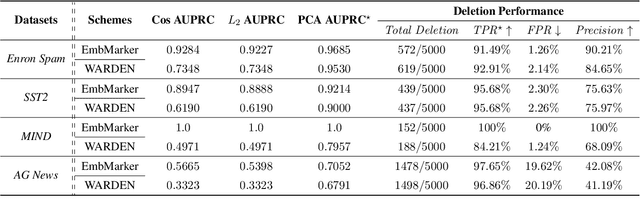
Embedding-as-a-Service (EaaS) has emerged as a successful business pattern but faces significant challenges related to various forms of copyright infringement, including API misuse and different attacks. Various studies have proposed backdoor-based watermarking schemes to protect the copyright of EaaS services. In this paper, we reveal that previous watermarking schemes possess semantic-independent characteristics and propose the Semantic Perturbation Attack (SPA). Our theoretical and experimental analyses demonstrate that this semantic-independent nature makes current watermarking schemes vulnerable to adaptive attacks that exploit semantic perturbations test to bypass watermark verification. To address this vulnerability, we propose the Semantic Aware Watermarking (SAW) scheme, a robust defense mechanism designed to resist SPA, by injecting a watermark that adapts to the text semantics. Extensive experimental results across multiple datasets demonstrate that the True Positive Rate (TPR) for detecting watermarked samples under SPA can reach up to more than 95%, rendering previous watermarks ineffective. Meanwhile, our watermarking scheme can resist such attack while ensuring the watermark verification capability. Our code is available at https://github.com/Zk4-ps/EaaS-Embedding-Watermark.