 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentation-Interpolative AutoEncoders for Unsupervised Few-Shot Image Generation
Nov 25, 2020
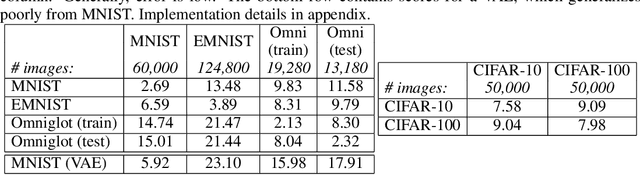

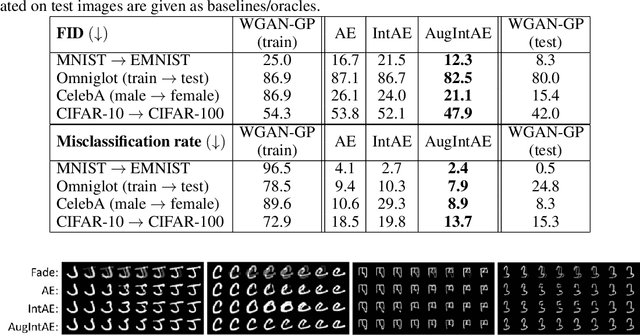
We aim to build image generation models that generalize to new domains from few examples. To this end, we first investigate the generalization properties of classic image generators, and discover that autoencoders generalize extremely well to new domains, even when trained on highly constrained data. We leverage this insight to produce a robust, unsupervised few-shot image generation algorithm, and introduce a novel training procedure based on recovering an image from data augmentations. Our Augmentation-Interpolative AutoEncoders synthesize realistic images of novel objects from only a few reference images, and outperform both prior interpolative models and supervised few-shot image generators. Our procedure is simple and lightweight, generalizes broadly, and requires no category labels or other supervision during training.
Self-training for Few-shot Transfer Across Extreme Task Differences
Oct 15, 2020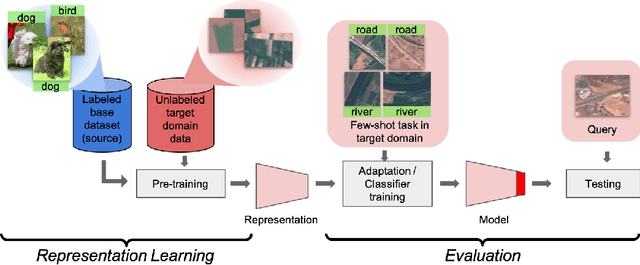
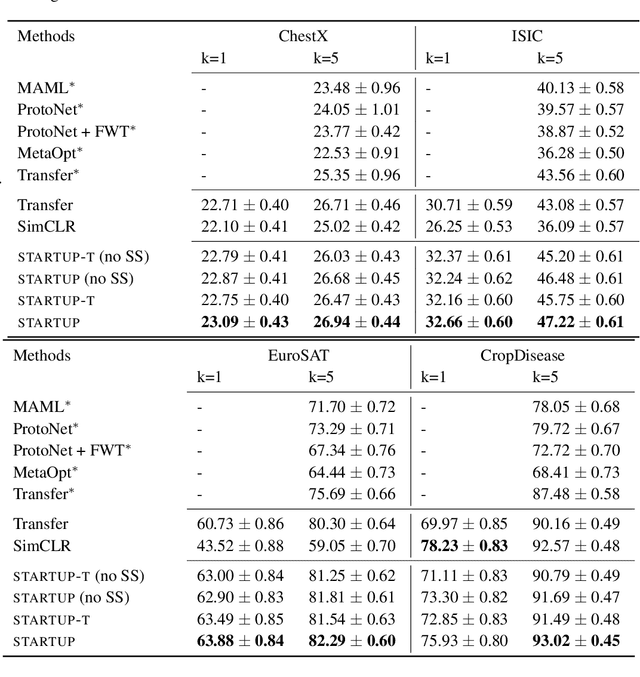
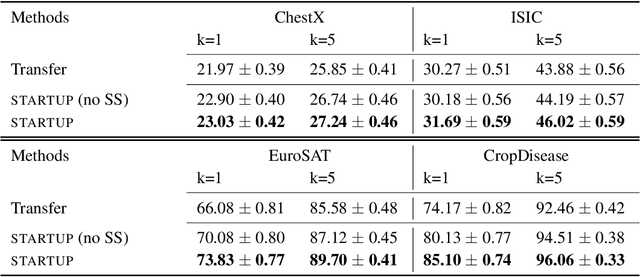
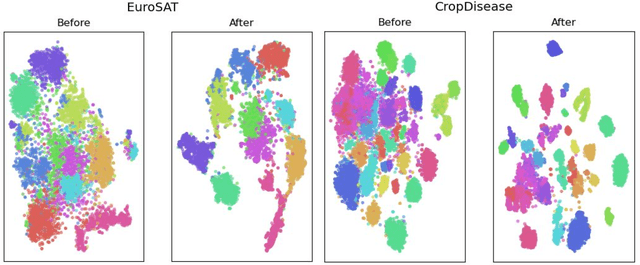
All few-shot learning techniques must be pre-trained on a large, labeled "base dataset". In problem domains where such large labeled datasets are not available for pre-training (e.g., X-ray images), one must resort to pre-training in a different "source" problem domain (e.g., ImageNet), which can be very different from the desired target task. Traditional few-shot and transfer learning techniques fail in the presence of such extreme differences between the source and target tasks. In this paper, we present a simple and effective solution to tackle this extreme domain gap: self-training a source domain representation on unlabeled data from the target domain. We show that this improves one-shot performance on the target domain by 2.9 points on average on a challenging benchmark with multiple domains.
Learning Gradient Fields for Shape Generation
Aug 18, 2020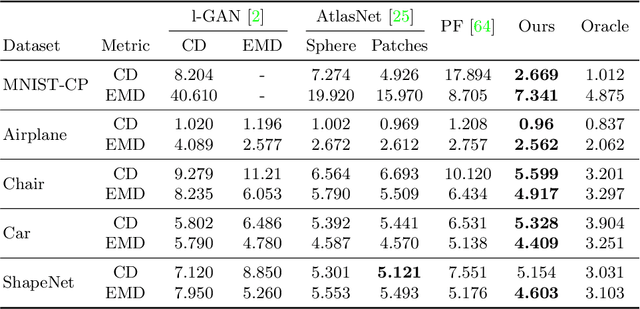
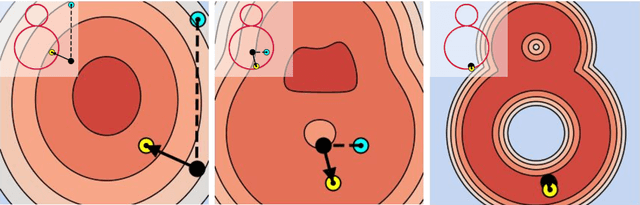
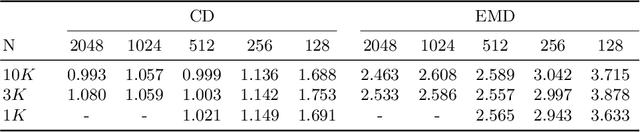
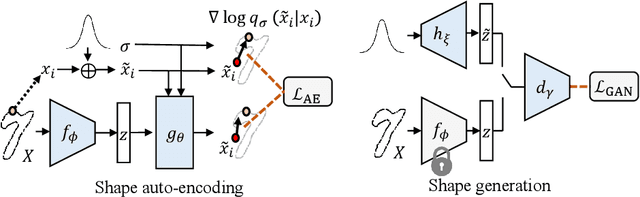
In this work, we propose a novel technique to generate shapes from point cloud data. A point cloud can be viewed as samples from a distribution of 3D points whose density is concentrated near the surface of the shape. Point cloud generation thus amounts to moving randomly sampled points to high-density areas. We generate point clouds by performing stochastic gradient ascent on an unnormalized probability density, thereby moving sampled points toward the high-likelihood regions. Our model directly predicts the gradient of the log density field and can be trained with a simple objective adapted from score-based generative models. We show that our method can reach state-of-the-art performance for point cloud auto-encoding and generation, while also allowing for extraction of a high-quality implicit surface. Code is available at https://github.com/RuojinCai/ShapeGF.
Wasserstein Distances for Stereo Disparity Estimation
Jul 06, 2020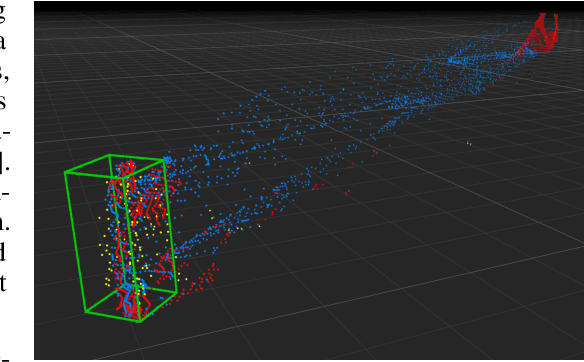
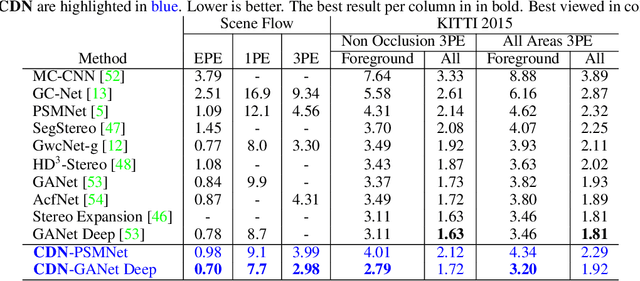
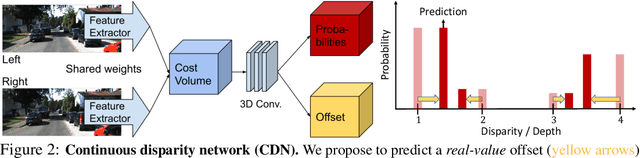
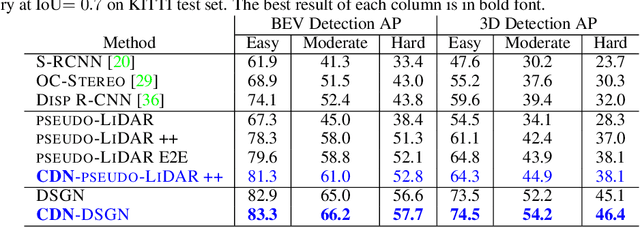
Existing approaches to depth or disparity estimation output a distribution over a set of pre-defined discrete values. This leads to inaccurate results when the true depth or disparity does not match any of these values. The fact that this distribution is usually learned indirectly through a regression loss causes further problems in ambiguous regions around object boundaries. We address these issues using a new neural network architecture that is capable of outputting arbitrary depth values, and a new loss function that is derived from the Wasserstein distance between the true and the predicted distributions. We validate our approach on a variety of tasks, including stereo disparity and depth estimation, and the downstream 3D object detection. Our approach drastically reduces the error in ambiguous regions, especially around object boundaries that greatly affect the localization of objects in 3D, achieving the state-of-the-art in 3D object detection for autonomous driving.
Train in Germany, Test in The USA: Making 3D Object Detectors Generalize
May 17, 2020

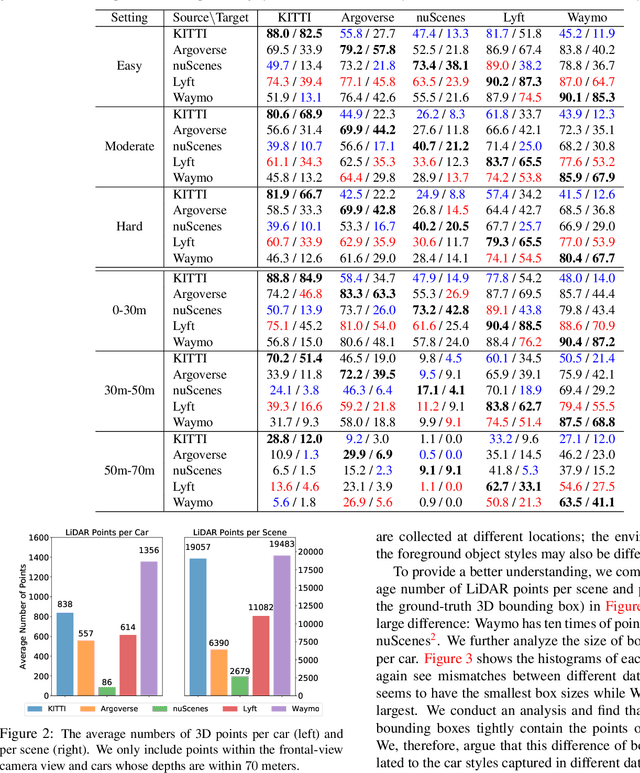
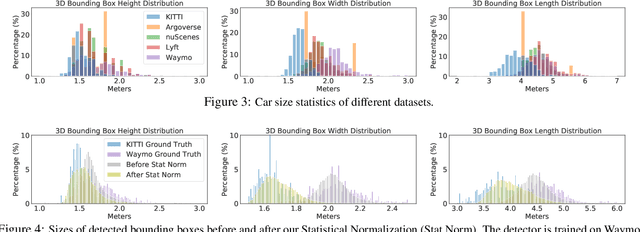
In the domain of autonomous driving, deep learning has substantially improved the 3D object detection accuracy for LiDAR and stereo camera data alike. While deep networks are great at generalization, they are also notorious to over-fit to all kinds of spurious artifacts, such as brightness, car sizes and models, that may appear consistently throughout the data. In fact, most datasets for autonomous driving are collected within a narrow subset of cities within one country, typically under similar weather conditions. In this paper we consider the task of adapting 3D object detectors from one dataset to another. We observe that naively, this appears to be a very challenging task, resulting in drastic drops in accuracy levels. We provide extensive experiments to investigate the true adaptation challenges and arrive at a surprising conclusion: the primary adaptation hurdle to overcome are differences in car sizes across geographic areas. A simple correction based on the average car size yields a strong correction of the adaptation gap. Our proposed method is simple and easily incorporated into most 3D object detection frameworks. It provides a first baseline for 3D object detection adaptation across countries, and gives hope that the underlying problem may be more within grasp than one may have hoped to believe. Our code is available at https://github.com/cxy1997/3D_adapt_auto_driving.
Learning Feature Descriptors using Camera Pose Supervision
Apr 28, 2020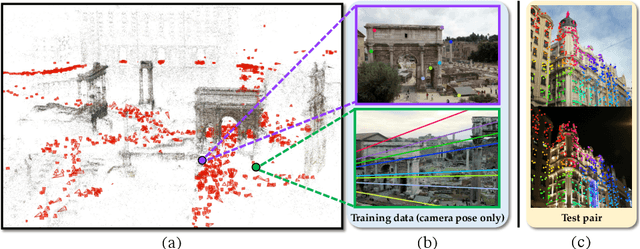
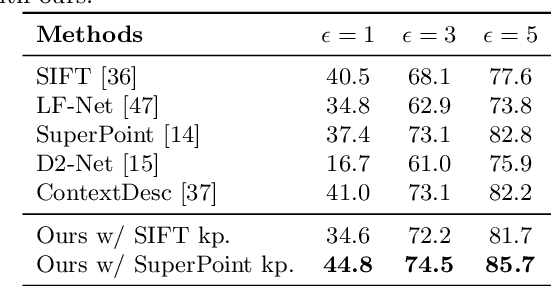
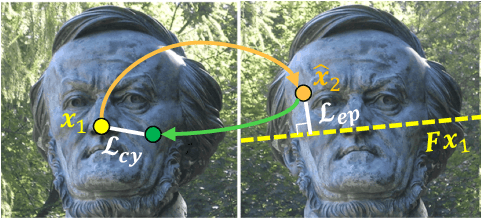
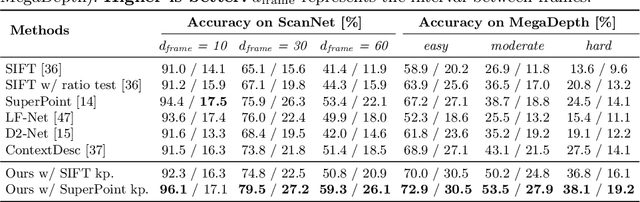
Recent research on learned visual descriptors has shown promising improvements in correspondence estimation, a key component of many 3D vision tasks. However, existing descriptor learning frameworks typically require ground-truth correspondences between feature points for training, which are challenging to acquire at scale. In this paper we propose a novel weakly-supervised framework that can learn feature descriptors solely from relative camera poses between images. To do so, we devise both a new loss function that exploits the epipolar constraint given by camera poses, and a new model architecture that makes the whole pipeline differentiable and efficient. Because we no longer need pixel-level ground-truth correspondences, our framework opens up the possibility of training on much larger and more diverse datasets for better and unbiased descriptors. Though trained with weak supervision, our learned descriptors outperform even prior fully-supervised methods and achieve state-of-the-art performance on a variety of geometric tasks.
Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
Apr 26, 2020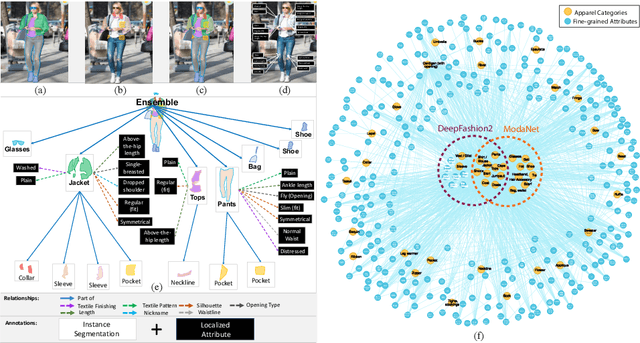


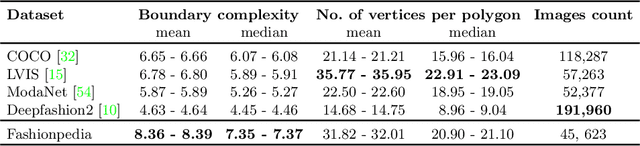
In this work we explore the task of instance segmentation with attribute localization, which unifies instance segmentation (detect and segment each object instance) and fine-grained visual attribute categorization (recognize one or multiple attributes). The proposed task requires both localizing an object and describing its properties. To illustrate the various aspects of this task, we focus on the domain of fashion and introduce Fashionpedia as a step toward mapping out the visual aspects of the fashion world. Fashionpedia consists of two parts: (1) an ontology built by fashion experts containing 27 main apparel categories, 19 apparel parts, 294 fine-grained attributes and their relationships; (2) a dataset with everyday and celebrity event fashion images annotated with segmentation masks and their associated per-mask fine-grained attributes, built upon the Fashionpedia ontology. In order to solve this challenging task, we propose a novel Attribute-Mask RCNN model to jointly perform instance segmentation and localized attribute recognition, and provide a novel evaluation metric for the task. We also demonstrate instance segmentation models pre-trained on Fashionpedia achieve better transfer learning performance on other fashion datasets than ImageNet pre-training. Fashionpedia is available at: https://fashionpedia.github.io/home/index.html.
Extending and Analyzing Self-Supervised Learning Across Domains
Apr 24, 2020
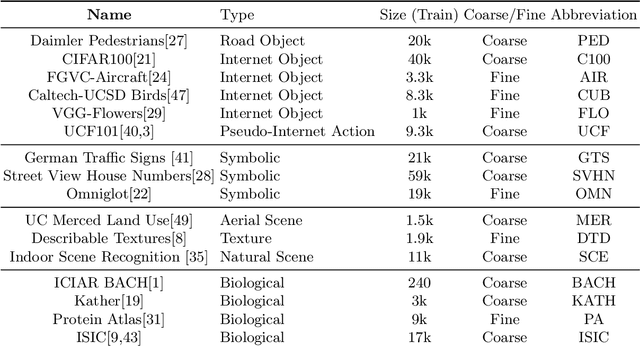
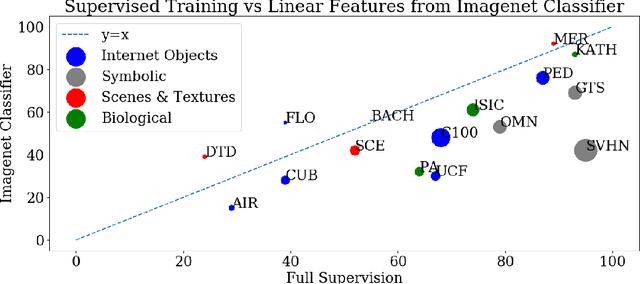
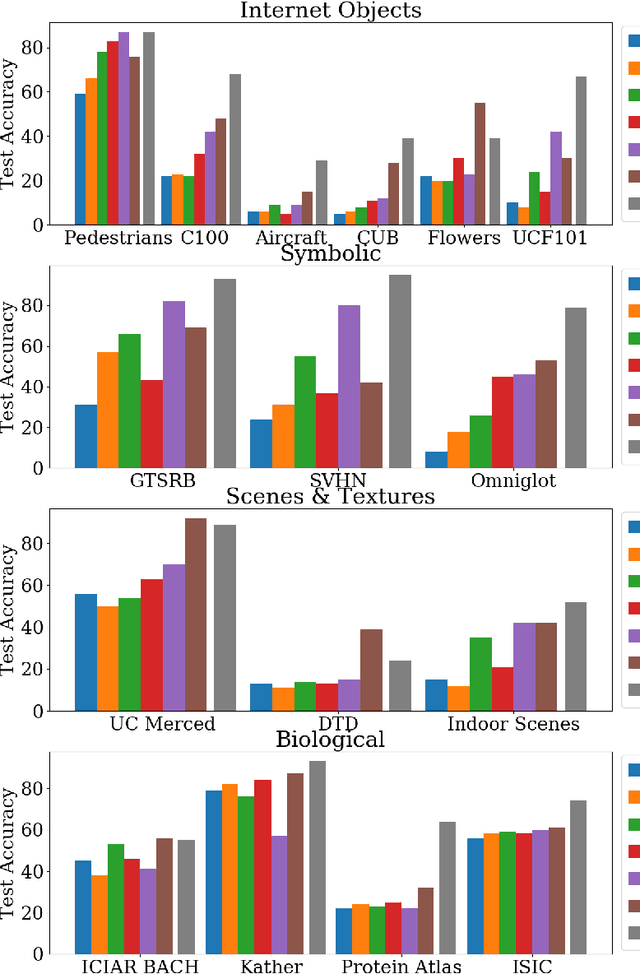
Self-supervised representation learning has achieved impressive results in recent years, with experiments primarily coming on ImageNet or other similarly large internet imagery datasets. There has been little to no work with these methods on other smaller domains, such as satellite, textural, or biological imagery. We experiment with several popular methods on an unprecedented variety of domains. We discover, among other findings, that Rotation is by far the most semantically meaningful task, with much of the performance of Jigsaw and Instance Discrimination being attributable to the nature of their induced distribution rather than semantic understanding. Additionally, there are several areas, such as fine-grain classification, where all tasks underperform. We quantitatively and qualitatively diagnose the reasons for these failures and successes via novel experiments studying pretext generalization, random labelings, and implicit dimensionality. Code and models are available at https://github.com/BramSW/Extending_SSRL_Across_Domains/.
End-to-End Pseudo-LiDAR for Image-Based 3D Object Detection
Apr 07, 2020
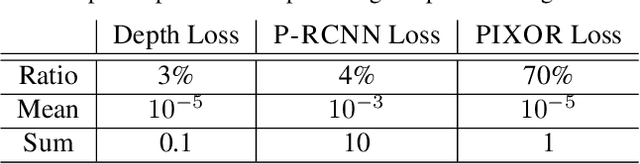
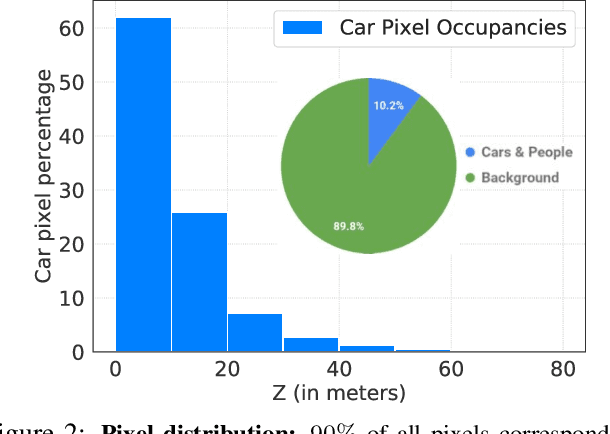
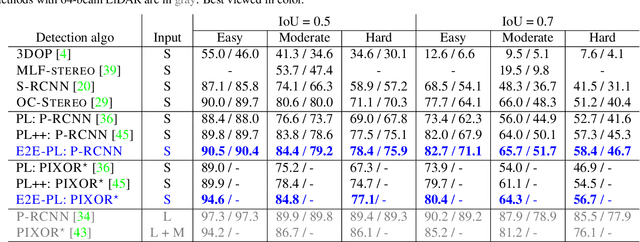
Reliable and accurate 3D object detection is a necessity for safe autonomous driving. Although LiDAR sensors can provide accurate 3D point cloud estimates of the environment, they are also prohibitively expensive for many settings. Recently, the introduction of pseudo-LiDAR (PL) has led to a drastic reduction in the accuracy gap between methods based on LiDAR sensors and those based on cheap stereo cameras. PL combines state-of-the-art deep neural networks for 3D depth estimation with those for 3D object detection by converting 2D depth map outputs to 3D point cloud inputs. However, so far these two networks have to be trained separately. In this paper, we introduce a new framework based on differentiable Change of Representation (CoR) modules that allow the entire PL pipeline to be trained end-to-end. The resulting framework is compatible with most state-of-the-art networks for both tasks and in combination with PointRCNN improves over PL consistently across all benchmarks -- yielding the highest entry on the KITTI image-based 3D object detection leaderboard at the time of submission. Our code will be made available at https://github.com/mileyan/pseudo-LiDAR_e2e.
Revisiting Pose-Normalization for Fine-Grained Few-Shot Recognition
Apr 01, 2020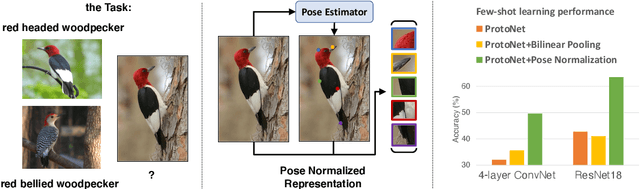
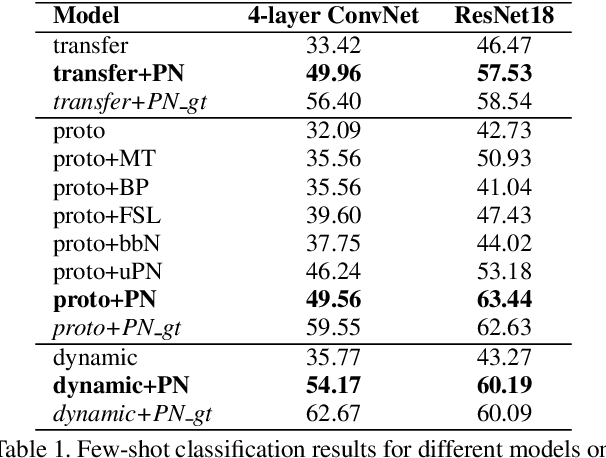
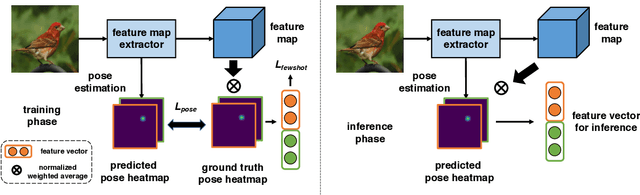
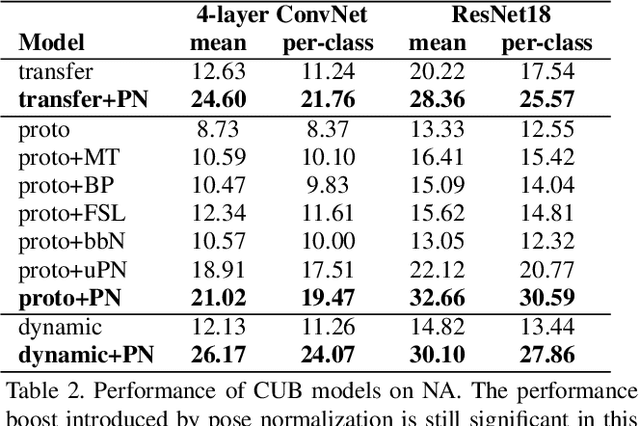
Few-shot, fine-grained classification requires a model to learn subtle, fine-grained distinctions between different classes (e.g., birds) based on a few images alone. This requires a remarkable degree of invariance to pose, articulation and background. A solution is to use pose-normalized representations: first localize semantic parts in each image, and then describe images by characterizing the appearance of each part. While such representations are out of favor for fully supervised classification, we show that they are extremely effective for few-shot fine-grained classification. With a minimal increase in model capacity, pose normalization improves accuracy between 10 and 20 percentage points for shallow and deep architectures, generalizes better to new domains, and is effective for multiple few-shot algorithms and network backbones. Code is available at https://github.com/Tsingularity/PoseNorm_Fewshot