 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Reasoning for Constraint-Aware Feature Selection in Industrial Systems
Mar 26, 2026Feature selection is a crucial step in large-scale industrial machine learning systems, directly affecting model accuracy, efficiency, and maintainability. Traditional feature selection methods rely on labeled data and statistical heuristics, making them difficult to apply in production environments where labeled data are limited and multiple operational constraints must be satisfied. To address this, we propose Model Feature Agent (MoFA), a model-driven framework that performs sequential, reasoning-based feature selection using both semantic and quantitative feature information. MoFA incorporates feature definitions, importance scores, correlations, and metadata (e.g., feature groups or types) into structured prompts and selects features through interpretable, constraint-aware reasoning. We evaluate MoFA in three real-world industrial applications: (1) True Interest and Time-Worthiness Prediction, where it improves accuracy while reducing feature group complexity, (2) Value Model Enhancement, where it discovers high-order interaction terms that yield substantial engagement gains in online experiments, and (3) Notification Behavior Prediction, where it selects compact, high-value feature subsets that improve both model accuracy and inference efficiency. Together, these results demonstrate the practicality and effectiveness of LLM-based reasoning for feature selection in real production systems.
EBPO: Empirical Bayes Shrinkage for Stabilizing Group-Relative Policy Optimization
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for enhancing the reasoning capabilities of Large Language Models (LLMs). However, dominant approaches like Group Relative Policy Optimization (GRPO) face critical stability challenges: they suffer from high estimator variance under computational constraints (small group sizes) and vanishing gradient signals in saturated failure regimes where all responses yield identical zero rewards. To address this, we propose Empirical Bayes Policy Optimization (EBPO), a novel framework that regularizes local group-based baselines by borrowing strength from the policy's accumulated global statistics. Instead of estimating baselines in isolation, EBPO employs a shrinkage estimator that dynamically balances local group statistics with a global prior updated via Welford's online algorithm. Theoretically, we demonstrate that EBPO guarantees strictly lower Mean Squared Error (MSE), bounded entropy decay, and non-vanishing penalty signals in failure scenarios compared to GRPO. Empirically, EBPO consistently outperforms GRPO and other established baselines across diverse benchmarks, including AIME and OlympiadBench. Notably, EBPO exhibits superior training stability, achieving high-performance gains even with small group sizes, and benefits significantly from difficulty-stratified curriculum learning.
GEM: Empowering LLM for both Embedding Generation and Language Understanding
Jun 04, 2025Large decoder-only language models (LLMs) have achieved remarkable success in generation and reasoning tasks, where they generate text responses given instructions. However, many applications, e.g., retrieval augmented generation (RAG), still rely on separate embedding models to generate text embeddings, which can complicate the system and introduce discrepancies in understanding of the query between the embedding model and LLMs. To address this limitation, we propose a simple self-supervised approach, Generative Embedding large language Model (GEM), that enables any large decoder-only LLM to generate high-quality text embeddings while maintaining its original text generation and reasoning capabilities. Our method inserts new special token(s) into a text body, and generates summarization embedding of the text by manipulating the attention mask. This method could be easily integrated into post-training or fine tuning stages of any existing LLMs. We demonstrate the effectiveness of our approach by applying it to two popular LLM families, ranging from 1B to 8B parameters, and evaluating the transformed models on both text embedding benchmarks (MTEB) and NLP benchmarks (MMLU). The results show that our proposed method significantly improves the original LLMs on MTEB while having a minimal impact on MMLU. Our strong results indicate that our approach can empower LLMs with state-of-the-art text embedding capabilities while maintaining their original NLP performance
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
SWaT: Statistical Modeling of Video Watch Time through User Behavior Analysis
Aug 14, 2024



The significance of estimating video watch time has been highlighted by the rising importance of (short) video recommendation, which has become a core product of mainstream social media platforms. Modeling video watch time, however, has been challenged by the complexity of user-video interaction, such as different user behavior modes in watching the recommended videos and varying watching probabilities over the video horizon. Despite the importance and challenges, existing literature on modeling video watch time mostly focuses on relatively black-box mechanical enhancement of the classical regression/classification losses, without factoring in user behavior in a principled manner. In this paper, we for the first time take on a user-centric perspective to model video watch time, from which we propose a white-box statistical framework that directly translates various user behavior assumptions in watching (short) videos into statistical watch time models. These behavior assumptions are portrayed by our domain knowledge on users' behavior modes in video watching. We further employ bucketization to cope with user's non-stationary watching probability over the video horizon, which additionally helps to respect the constraint of video length and facilitate the practical compatibility between the continuous regression event of watch time and other binary classification events. We test our models extensively on two public datasets, a large-scale offline industrial dataset, and an online A/B test on a short video platform with hundreds of millions of daily-active users. On all experiments, our models perform competitively against strong relevant baselines, demonstrating the efficacy of our user-centric perspective and proposed framework.
Resource Aware Person Re-identification across Multiple Resolutions
Oct 02, 2018
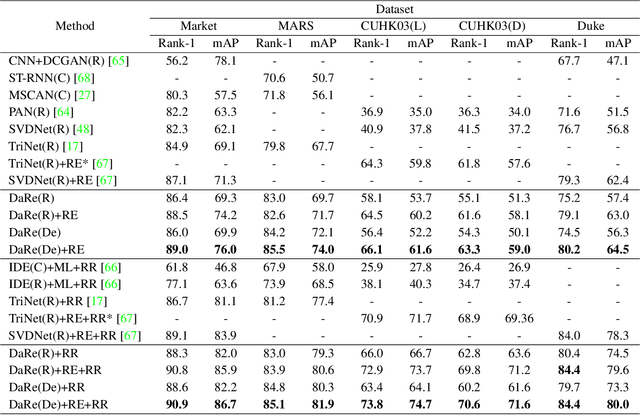
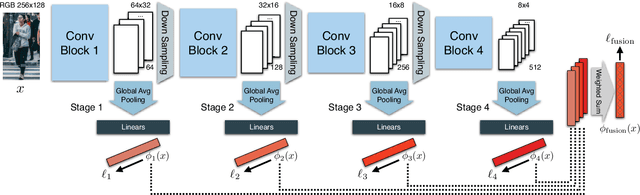
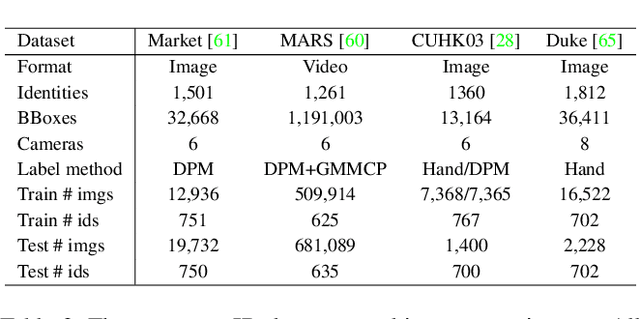
Not all people are equally easy to identify: color statistics might be enough for some cases while others might require careful reasoning about high- and low-level details. However, prevailing person re-identification(re-ID) methods use one-size-fits-all high-level embeddings from deep convolutional networks for all cases. This might limit their accuracy on difficult examples or makes them needlessly expensive for the easy ones. To remedy this, we present a new person re-ID model that combines effective embeddings built on multiple convolutional network layers, trained with deep-supervision. On traditional re-ID benchmarks, our method improves substantially over the previous state-of-the-art results on all five datasets that we evaluate on. We then propose two new formulations of the person re-ID problem under resource-constraints, and show how our model can be used to effectively trade off accuracy and computation in the presence of resource constraints. Code and pre-trained models are available at https://github.com/mileyan/DARENet.