 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Fragile Features and Batch Normalization in Adversarial Training
Apr 26, 2022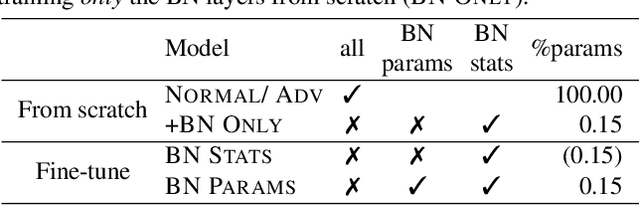

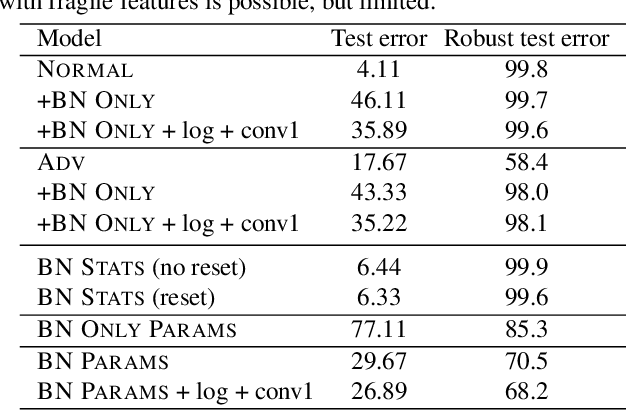

Modern deep learning architecture utilize batch normalization (BN) to stabilize training and improve accuracy. It has been shown that the BN layers alone are surprisingly expressive. In the context of robustness against adversarial examples, however, BN is argued to increase vulnerability. That is, BN helps to learn fragile features. Nevertheless, BN is still used in adversarial training, which is the de-facto standard to learn robust features. In order to shed light on the role of BN in adversarial training, we investigate to what extent the expressiveness of BN can be used to robustify fragile features in comparison to random features. On CIFAR10, we find that adversarially fine-tuning just the BN layers can result in non-trivial adversarial robustness. Adversarially training only the BN layers from scratch, in contrast, is not able to convey meaningful adversarial robustness. Our results indicate that fragile features can be used to learn models with moderate adversarial robustness, while random features cannot
RBGNet: Ray-based Grouping for 3D Object Detection
Apr 05, 2022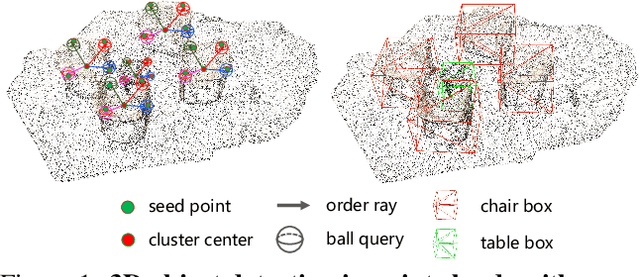

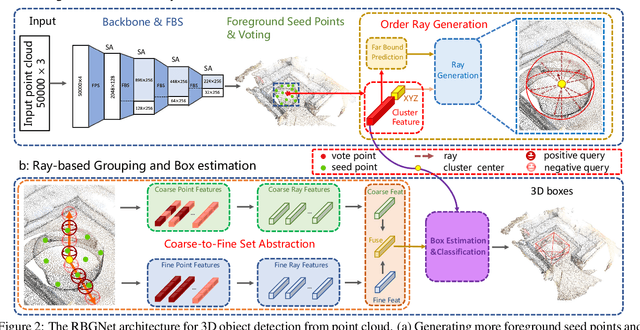
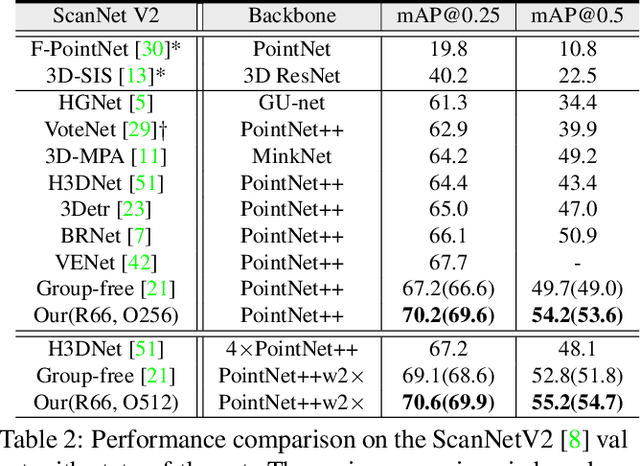
As a fundamental problem in computer vision, 3D object detection is experiencing rapid growth. To extract the point-wise features from the irregularly and sparsely distributed points, previous methods usually take a feature grouping module to aggregate the point features to an object candidate. However, these methods have not yet leveraged the surface geometry of foreground objects to enhance grouping and 3D box generation. In this paper, we propose the RBGNet framework, a voting-based 3D detector for accurate 3D object detection from point clouds. In order to learn better representations of object shape to enhance cluster features for predicting 3D boxes, we propose a ray-based feature grouping module, which aggregates the point-wise features on object surfaces using a group of determined rays uniformly emitted from cluster centers. Considering the fact that foreground points are more meaningful for box estimation, we design a novel foreground biased sampling strategy in downsample process to sample more points on object surfaces and further boost the detection performance. Our model achieves state-of-the-art 3D detection performance on ScanNet V2 and SUN RGB-D with remarkable performance gains. Code will be available at https://github.com/Haiyang-W/RBGNet.
Attribute Prototype Network for Any-Shot Learning
Apr 04, 2022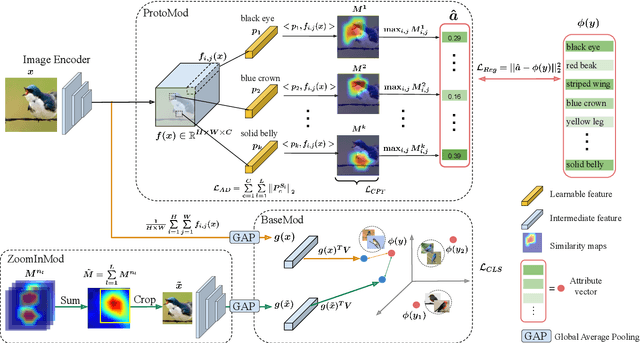
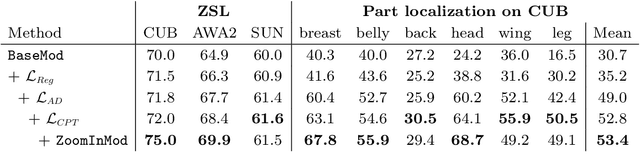
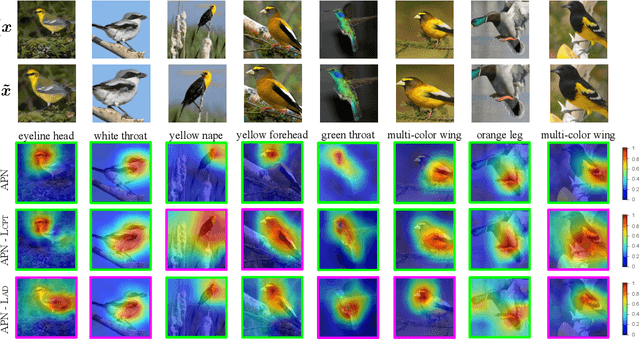
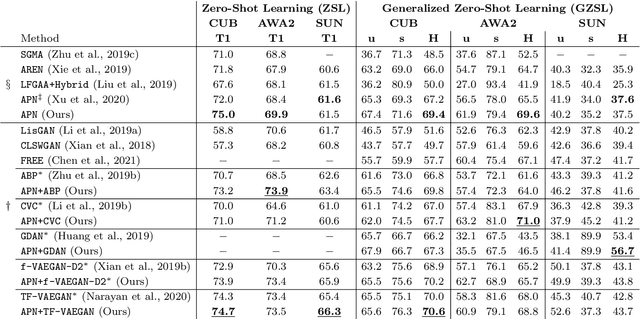
Any-shot image classification allows to recognize novel classes with only a few or even zero samples. For the task of zero-shot learning, visual attributes have been shown to play an important role, while in the few-shot regime, the effect of attributes is under-explored. To better transfer attribute-based knowledge from seen to unseen classes, we argue that an image representation with integrated attribute localization ability would be beneficial for any-shot, i.e. zero-shot and few-shot, image classification tasks. To this end, we propose a novel representation learning framework that jointly learns discriminative global and local features using only class-level attributes. While a visual-semantic embedding layer learns global features, local features are learned through an attribute prototype network that simultaneously regresses and decorrelates attributes from intermediate features. Furthermore, we introduce a zoom-in module that localizes and crops the informative regions to encourage the network to learn informative features explicitly. We show that our locality augmented image representations achieve a new state-of-the-art on challenging benchmarks, i.e. CUB, AWA2, and SUN. As an additional benefit, our model points to the visual evidence of the attributes in an image, confirming the improved attribute localization ability of our image representation. The attribute localization is evaluated quantitatively with ground truth part annotations, qualitatively with visualizations, and through well-designed user studies.
Omni-DETR: Omni-Supervised Object Detection with Transformers
Mar 30, 2022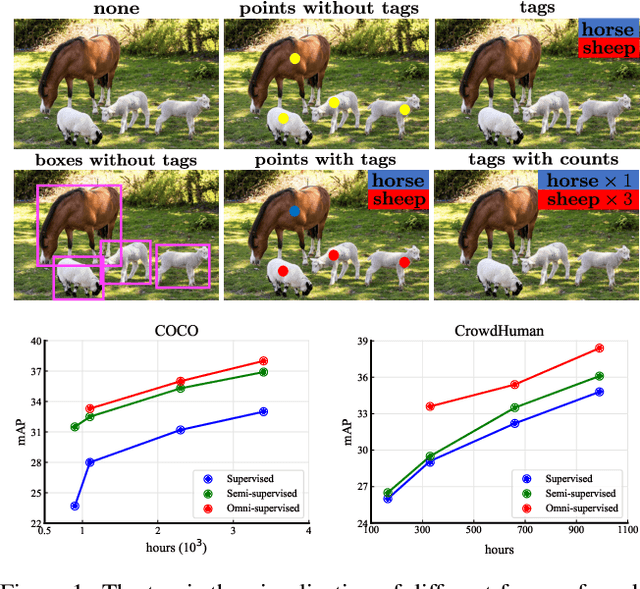


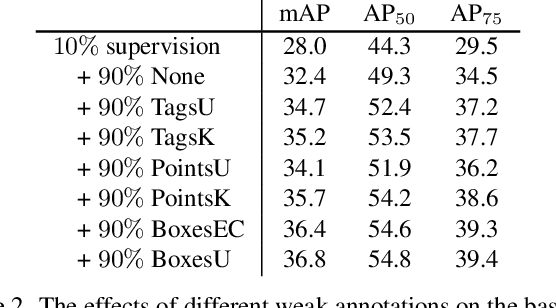
We consider the problem of omni-supervised object detection, which can use unlabeled, fully labeled and weakly labeled annotations, such as image tags, counts, points, etc., for object detection. This is enabled by a unified architecture, Omni-DETR, based on the recent progress on student-teacher framework and end-to-end transformer based object detection. Under this unified architecture, different types of weak labels can be leveraged to generate accurate pseudo labels, by a bipartite matching based filtering mechanism, for the model to learn. In the experiments, Omni-DETR has achieved state-of-the-art results on multiple datasets and settings. And we have found that weak annotations can help to improve detection performance and a mixture of them can achieve a better trade-off between annotation cost and accuracy than the standard complete annotation. These findings could encourage larger object detection datasets with mixture annotations. The code is available at https://github.com/amazon-research/omni-detr.
VGSE: Visually-Grounded Semantic Embeddings for Zero-Shot Learning
Mar 20, 2022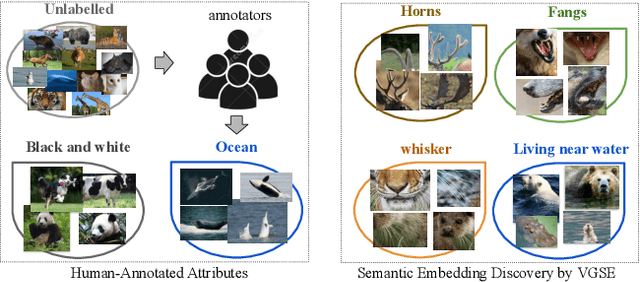
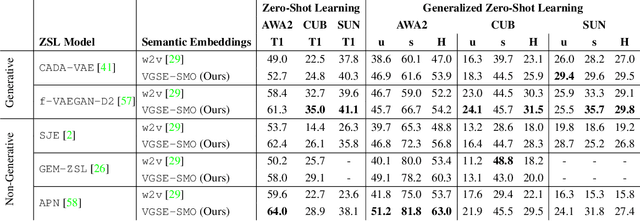
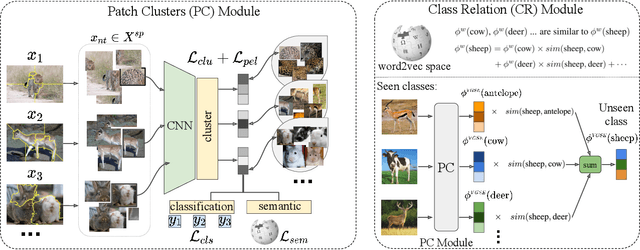
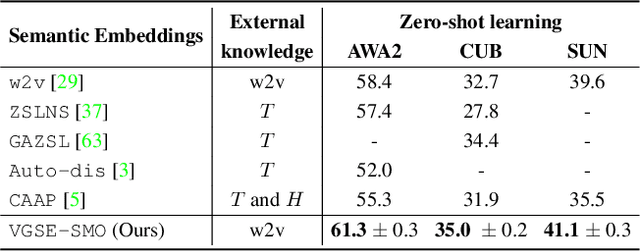
Human-annotated attributes serve as powerful semantic embeddings in zero-shot learning. However, their annotation process is labor-intensive and needs expert supervision. Current unsupervised semantic embeddings, i.e., word embeddings, enable knowledge transfer between classes. However, word embeddings do not always reflect visual similarities and result in inferior zero-shot performance. We propose to discover semantic embeddings containing discriminative visual properties for zero-shot learning, without requiring any human annotation. Our model visually divides a set of images from seen classes into clusters of local image regions according to their visual similarity, and further imposes their class discrimination and semantic relatedness. To associate these clusters with previously unseen classes, we use external knowledge, e.g., word embeddings and propose a novel class relation discovery module. Through quantitative and qualitative evaluation, we demonstrate that our model discovers semantic embeddings that model the visual properties of both seen and unseen classes. Furthermore, we demonstrate on three benchmarks that our visually-grounded semantic embeddings further improve performance over word embeddings across various ZSL models by a large margin.
A Unified Query-based Paradigm for Point Cloud Understanding
Mar 03, 2022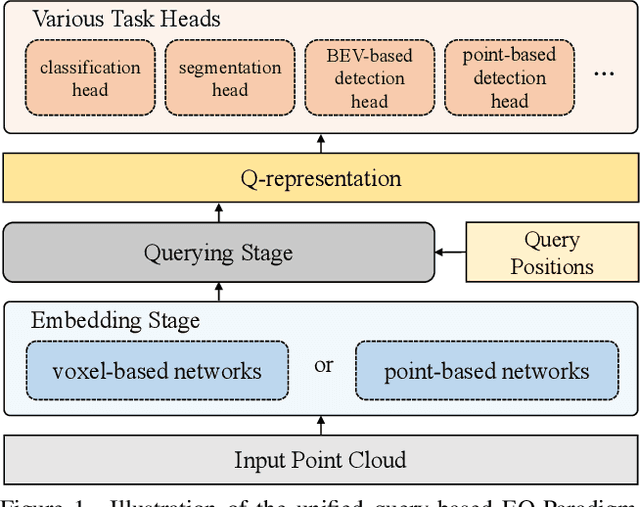
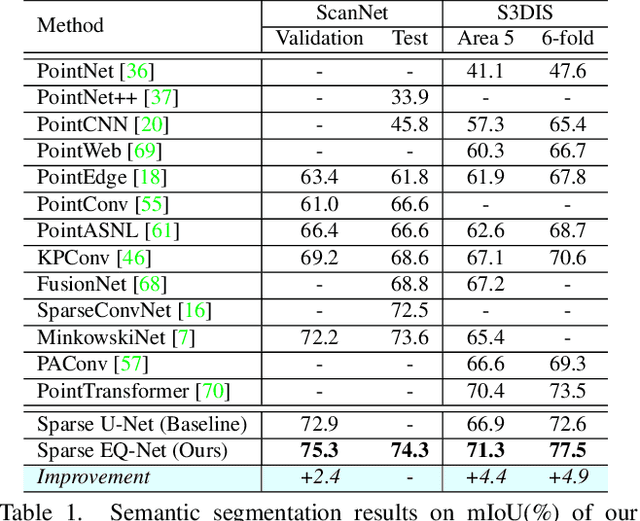
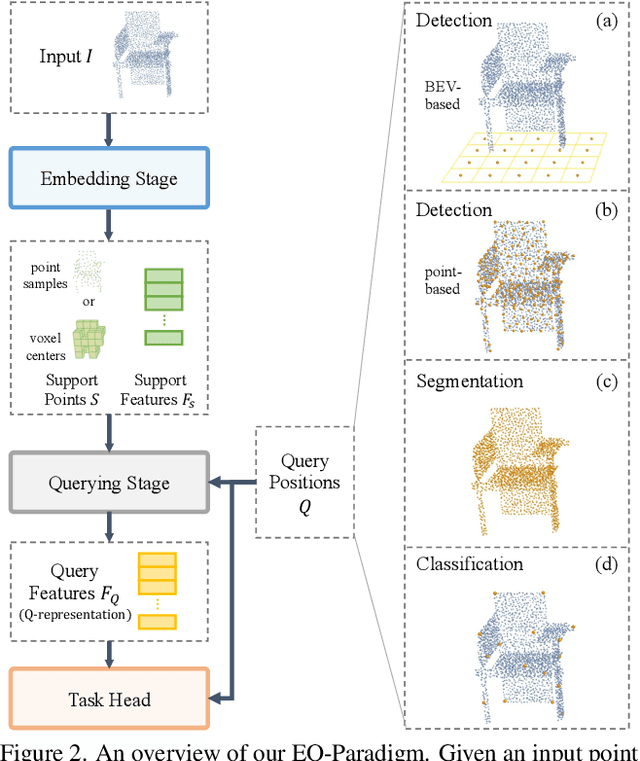
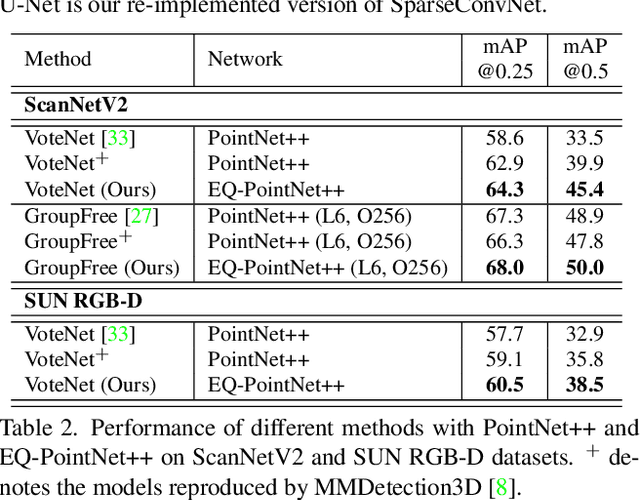
3D point cloud understanding is an important component in autonomous driving and robotics. In this paper, we present a novel Embedding-Querying paradigm (EQ-Paradigm) for 3D understanding tasks including detection, segmentation and classification. EQ-Paradigm is a unified paradigm that enables the combination of any existing 3D backbone architectures with different task heads. Under the EQ-Paradigm, the input is firstly encoded in the embedding stage with an arbitrary feature extraction architecture, which is independent of tasks and heads. Then, the querying stage enables the encoded features to be applicable for diverse task heads. This is achieved by introducing an intermediate representation, i.e., Q-representation, in the querying stage to serve as a bridge between the embedding stage and task heads. We design a novel Q-Net as the querying stage network. Extensive experimental results on various 3D tasks including semantic segmentation, object detection and shape classification show that EQ-Paradigm in tandem with Q-Net is a general and effective pipeline, which enables a flexible collaboration of backbones and heads, and further boosts the performance of the state-of-the-art methods. All codes and models will be published soon.
Improving Corruption and Adversarial Robustness by Enhancing Weak Subnets
Jan 30, 2022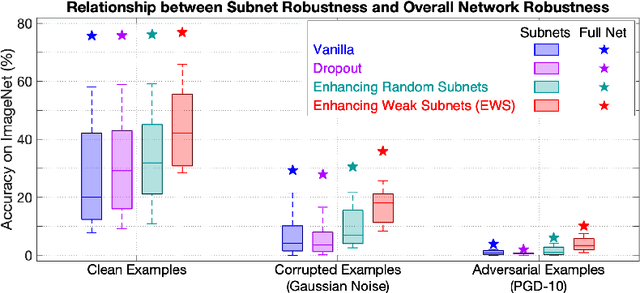
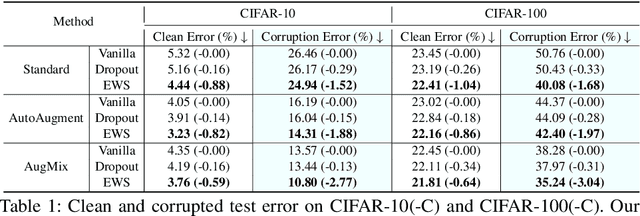
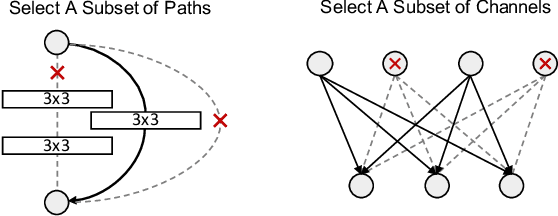
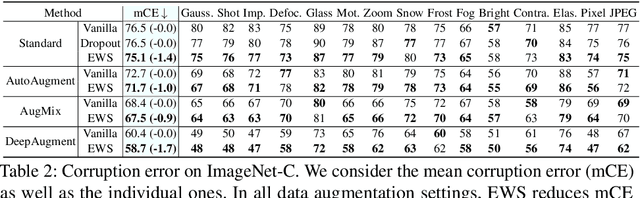
Deep neural networks have achieved great success in many computer vision tasks. However, deep networks have been shown to be very susceptible to corrupted or adversarial images, which often result in significant performance drops. In this paper, we observe that weak subnetwork (subnet) performance is correlated with a lack of robustness against corruptions and adversarial attacks. Based on that observation, we propose a novel robust training method which explicitly identifies and enhances weak subnets (EWS) during training to improve robustness. Specifically, we develop a search algorithm to find particularly weak subnets and propose to explicitly strengthen them via knowledge distillation from the full network. We show that our EWS greatly improves the robustness against corrupted images as well as the accuracy on clean data. Being complementary to many state-of-the-art data augmentation approaches, EWS consistently improves corruption robustness on top of many of these approaches. Moreover, EWS is also able to boost the adversarial robustness when combined with popular adversarial training methods.
Revisiting Consistency Regularization for Semi-Supervised Learning
Dec 10, 2021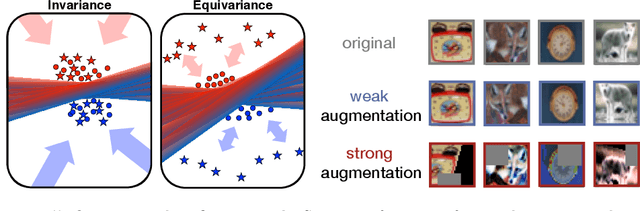
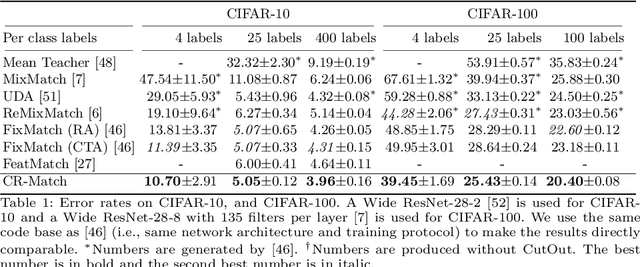
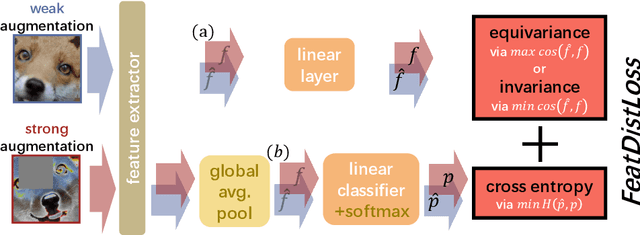
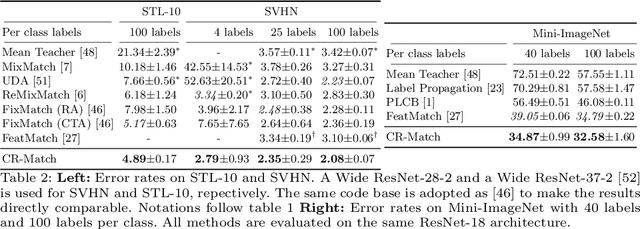
Consistency regularization is one of the most widely-used techniques for semi-supervised learning (SSL). Generally, the aim is to train a model that is invariant to various data augmentations. In this paper, we revisit this idea and find that enforcing invariance by decreasing distances between features from differently augmented images leads to improved performance. However, encouraging equivariance instead, by increasing the feature distance, further improves performance. To this end, we propose an improved consistency regularization framework by a simple yet effective technique, FeatDistLoss, that imposes consistency and equivariance on the classifier and the feature level, respectively. Experimental results show that our model defines a new state of the art for various datasets and settings and outperforms previous work by a significant margin, particularly in low data regimes. Extensive experiments are conducted to analyze the method, and the code will be published.
CoSSL: Co-Learning of Representation and Classifier for Imbalanced Semi-Supervised Learning
Dec 08, 2021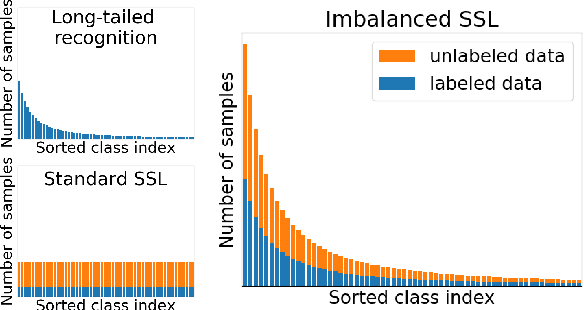
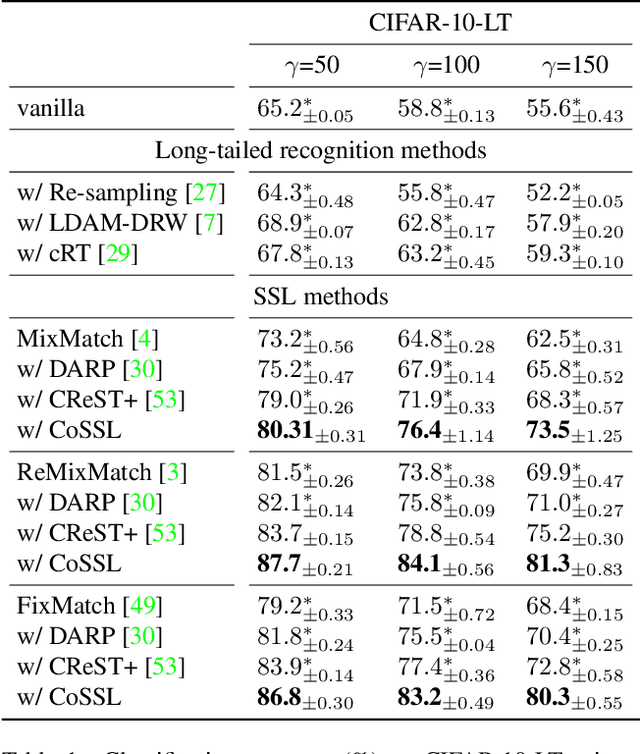
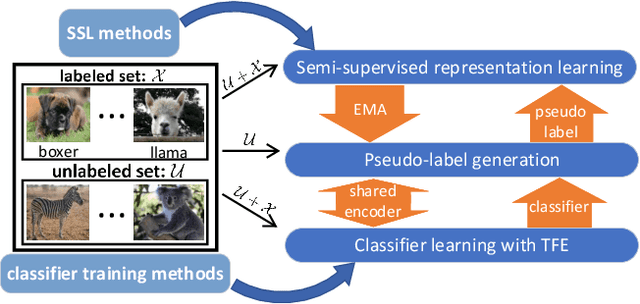
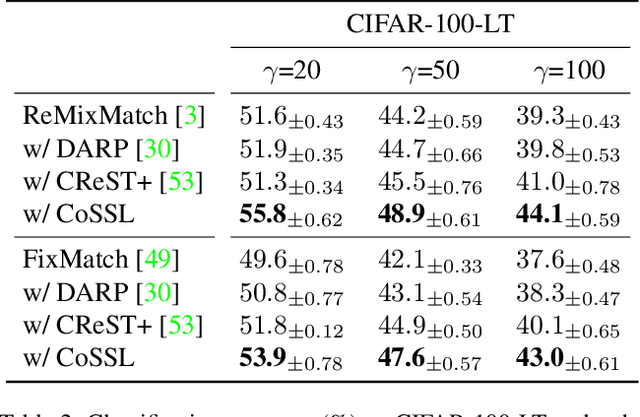
In this paper, we propose a novel co-learning framework (CoSSL) with decoupled representation learning and classifier learning for imbalanced SSL. To handle the data imbalance, we devise Tail-class Feature Enhancement (TFE) for classifier learning. Furthermore, the current evaluation protocol for imbalanced SSL focuses only on balanced test sets, which has limited practicality in real-world scenarios. Therefore, we further conduct a comprehensive evaluation under various shifted test distributions. In experiments, we show that our approach outperforms other methods over a large range of shifted distributions, achieving state-of-the-art performance on benchmark datasets ranging from CIFAR-10, CIFAR-100, ImageNet, to Food-101. Our code will be made publicly available.
Keypoint Message Passing for Video-based Person Re-Identification
Nov 16, 2021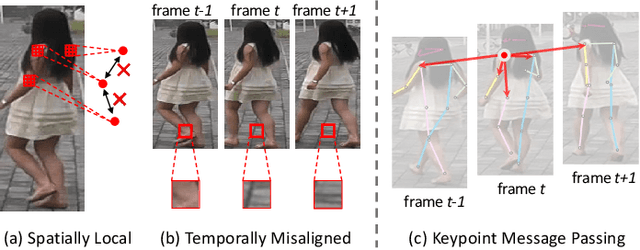
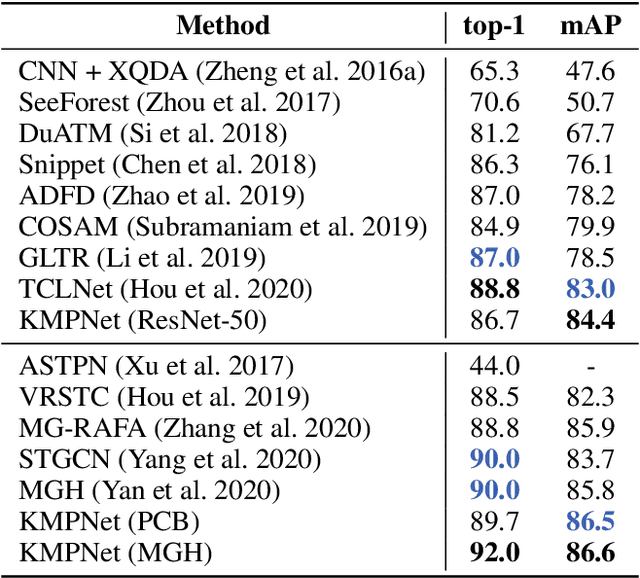
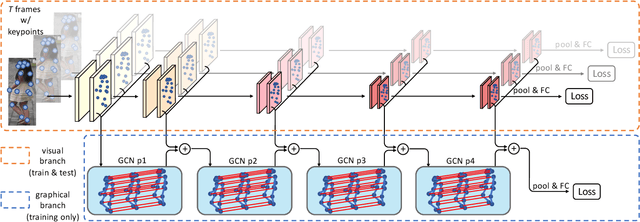
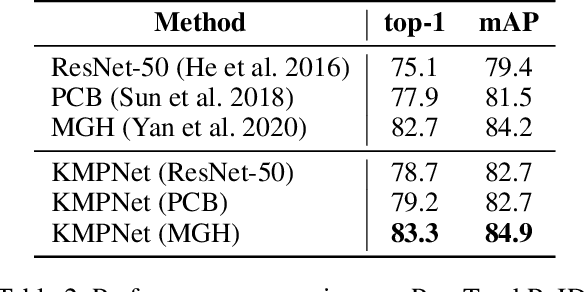
Video-based person re-identification (re-ID) is an important technique in visual surveillance systems which aims to match video snippets of people captured by different cameras. Existing methods are mostly based on convolutional neural networks (CNNs), whose building blocks either process local neighbor pixels at a time, or, when 3D convolutions are used to model temporal information, suffer from the misalignment problem caused by person movement. In this paper, we propose to overcome the limitations of normal convolutions with a human-oriented graph method. Specifically, features located at person joint keypoints are extracted and connected as a spatial-temporal graph. These keypoint features are then updated by message passing from their connected nodes with a graph convolutional network (GCN). During training, the GCN can be attached to any CNN-based person re-ID model to assist representation learning on feature maps, whilst it can be dropped after training for better inference speed. Our method brings significant improvements over the CNN-based baseline model on the MARS dataset with generated person keypoints and a newly annotated dataset: PoseTrackReID. It also defines a new state-of-the-art method in terms of top-1 accuracy and mean average precision in comparison to prior works.