 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Residual Networks with Group Knowledge
Aug 26, 2023



Recent research understands the residual networks from a new perspective of the implicit ensemble model. From this view, previous methods such as stochastic depth and stimulative training have further improved the performance of the residual network by sampling and training of its subnets. However, they both use the same supervision for all subnets of different capacities and neglect the valuable knowledge generated by subnets during training. In this manuscript, we mitigate the significant knowledge distillation gap caused by using the same kind of supervision and advocate leveraging the subnets to provide diverse knowledge. Based on this motivation, we propose a group knowledge based training framework for boosting the performance of residual networks. Specifically, we implicitly divide all subnets into hierarchical groups by subnet-in-subnet sampling, aggregate the knowledge of different subnets in each group during training, and exploit upper-level group knowledge to supervise lower-level subnet groups. Meanwhile, We also develop a subnet sampling strategy that naturally samples larger subnets, which are found to be more helpful than smaller subnets in boosting performance for hierarchical groups. Compared with typical subnet training and other methods, our method achieves the best efficiency and performance trade-offs on multiple datasets and network structures. The code will be released soon.
Stimulative Training++: Go Beyond The Performance Limits of Residual Networks
May 04, 2023



Residual networks have shown great success and become indispensable in recent deep neural network models. In this work, we aim to re-investigate the training process of residual networks from a novel social psychology perspective of loafing, and further propose a new training scheme as well as three improved strategies for boosting residual networks beyond their performance limits. Previous research has suggested that residual networks can be considered as ensembles of shallow networks, which implies that the final performance of a residual network is influenced by a group of subnetworks. We identify a previously overlooked problem that is analogous to social loafing, where subnetworks within a residual network are prone to exert less effort when working as part of a group compared to working alone. We define this problem as \textit{network loafing}. Similar to the decreased individual productivity and overall performance as demonstrated in society, network loafing inevitably causes sub-par performance. Inspired by solutions from social psychology, we first propose a novel training scheme called stimulative training, which randomly samples a residual subnetwork and calculates the KL divergence loss between the sampled subnetwork and the given residual network for extra supervision. In order to unleash the potential of stimulative training, we further propose three simple-yet-effective strategies, including a novel KL- loss that only aligns the network logits direction, random smaller inputs for subnetworks, and inter-stage sampling rules. Comprehensive experiments and analysis verify the effectiveness of stimulative training as well as its three improved strategies.
Multi-view Vision-Prompt Fusion Network: Can 2D Pre-trained Model Boost 3D Point Cloud Data-scarce Learning?
Apr 20, 2023Point cloud based 3D deep model has wide applications in many applications such as autonomous driving, house robot, and so on. Inspired by the recent prompt learning in natural language processing, this work proposes a novel Multi-view Vision-Prompt Fusion Network (MvNet) for few-shot 3D point cloud classification. MvNet investigates the possibility of leveraging the off-the-shelf 2D pre-trained models to achieve the few-shot classification, which can alleviate the over-dependence issue of the existing baseline models towards the large-scale annotated 3D point cloud data. Specifically, MvNet first encodes a 3D point cloud into multi-view image features for a number of different views. Then, a novel multi-view prompt fusion module is developed to effectively fuse information from different views to bridge the gap between 3D point cloud data and 2D pre-trained models. A set of 2D image prompts can then be derived to better describe the suitable prior knowledge for a large-scale pre-trained image model for few-shot 3D point cloud classification. Extensive experiments on ModelNet, ScanObjectNN, and ShapeNet datasets demonstrate that MvNet achieves new state-of-the-art performance for 3D few-shot point cloud image classification. The source code of this work will be available soon.
$β$-DARTS++: Bi-level Regularization for Proxy-robust Differentiable Architecture Search
Jan 16, 2023Neural Architecture Search has attracted increasing attention in recent years. Among them, differential NAS approaches such as DARTS, have gained popularity for the search efficiency. However, they still suffer from three main issues, that are, the weak stability due to the performance collapse, the poor generalization ability of the searched architectures, and the inferior robustness to different kinds of proxies. To solve the stability and generalization problems, a simple-but-effective regularization method, termed as Beta-Decay, is proposed to regularize the DARTS-based NAS searching process (i.e., $\beta$-DARTS). Specifically, Beta-Decay regularization can impose constraints to keep the value and variance of activated architecture parameters from being too large, thereby ensuring fair competition among architecture parameters and making the supernet less sensitive to the impact of input on the operation set. In-depth theoretical analyses on how it works and why it works are provided. Comprehensive experiments validate that Beta-Decay regularization can help to stabilize the searching process and makes the searched network more transferable across different datasets. To address the robustness problem, we first benchmark different NAS methods under a wide range of proxy data, proxy channels, proxy layers and proxy epochs, since the robustness of NAS under different kinds of proxies has not been explored before. We then conclude some interesting findings and find that $\beta$-DARTS always achieves the best result among all compared NAS methods under almost all proxies. We further introduce the novel flooding regularization to the weight optimization of $\beta$-DARTS (i.e., Bi-level regularization), and experimentally and theoretically verify its effectiveness for improving the proxy robustness of differentiable NAS.
Instance-aware Model Ensemble With Distillation For Unsupervised Domain Adaptation
Nov 15, 2022



The linear ensemble based strategy, i.e., averaging ensemble, has been proposed to improve the performance in unsupervised domain adaptation tasks. However, a typical UDA task is usually challenged by dynamically changing factors, such as variable weather, views, and background in the unlabeled target domain. Most previous ensemble strategies ignore UDA's dynamic and uncontrollable challenge, facing limited feature representations and performance bottlenecks. To enhance the model, adaptability between domains and reduce the computational cost when deploying the ensemble model, we propose a novel framework, namely Instance aware Model Ensemble With Distillation, IMED, which fuses multiple UDA component models adaptively according to different instances and distills these components into a small model. The core idea of IMED is a dynamic instance aware ensemble strategy, where for each instance, a nonlinear fusion subnetwork is learned that fuses the extracted features and predicted labels of multiple component models. The nonlinear fusion method can help the ensemble model handle dynamically changing factors. After learning a large capacity ensemble model with good adaptability to different changing factors, we leverage the ensemble teacher model to guide the learning of a compact student model by knowledge distillation. Furthermore, we provide the theoretical analysis of the validity of IMED for UDA. Extensive experiments conducted on various UDA benchmark datasets, e.g., Office 31, Office Home, and VisDA 2017, show the superiority of the model based on IMED to the state of the art methods under the comparable computation cost.
ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Oct 18, 2022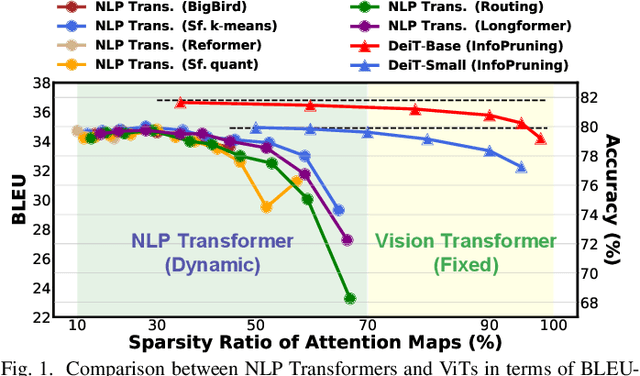
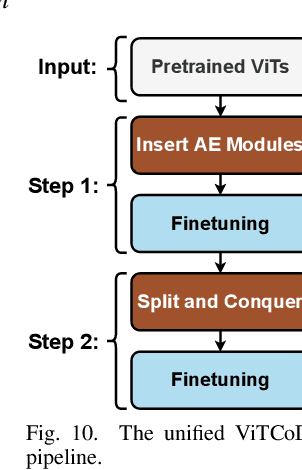
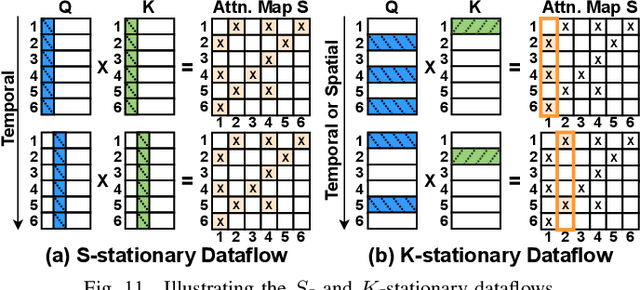
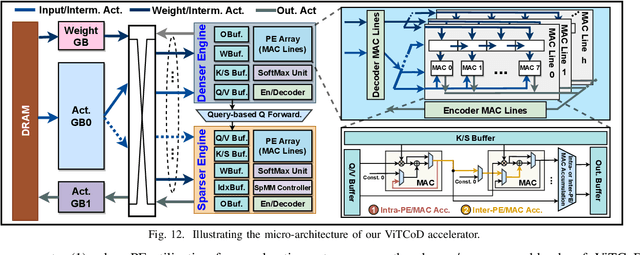
Vision Transformers (ViTs) have achieved state-of-the-art performance on various vision tasks. However, ViTs' self-attention module is still arguably a major bottleneck, limiting their achievable hardware efficiency. Meanwhile, existing accelerators dedicated to NLP Transformers are not optimal for ViTs. This is because there is a large difference between ViTs and NLP Transformers: ViTs have a relatively fixed number of input tokens, whose attention maps can be pruned by up to 90% even with fixed sparse patterns; while NLP Transformers need to handle input sequences of varying numbers of tokens and rely on on-the-fly predictions of dynamic sparse attention patterns for each input to achieve a decent sparsity (e.g., >=50%). To this end, we propose a dedicated algorithm and accelerator co-design framework dubbed ViTCoD for accelerating ViTs. Specifically, on the algorithm level, ViTCoD prunes and polarizes the attention maps to have either denser or sparser fixed patterns for regularizing two levels of workloads without hurting the accuracy, largely reducing the attention computations while leaving room for alleviating the remaining dominant data movements; on top of that, we further integrate a lightweight and learnable auto-encoder module to enable trading the dominant high-cost data movements for lower-cost computations. On the hardware level, we develop a dedicated accelerator to simultaneously coordinate the enforced denser/sparser workloads and encoder/decoder engines for boosted hardware utilization. Extensive experiments and ablation studies validate that ViTCoD largely reduces the dominant data movement costs, achieving speedups of up to 235.3x, 142.9x, 86.0x, 10.1x, and 6.8x over general computing platforms CPUs, EdgeGPUs, GPUs, and prior-art Transformer accelerators SpAtten and Sanger under an attention sparsity of 90%, respectively.
Stimulative Training of Residual Networks: A Social Psychology Perspective of Loafing
Oct 09, 2022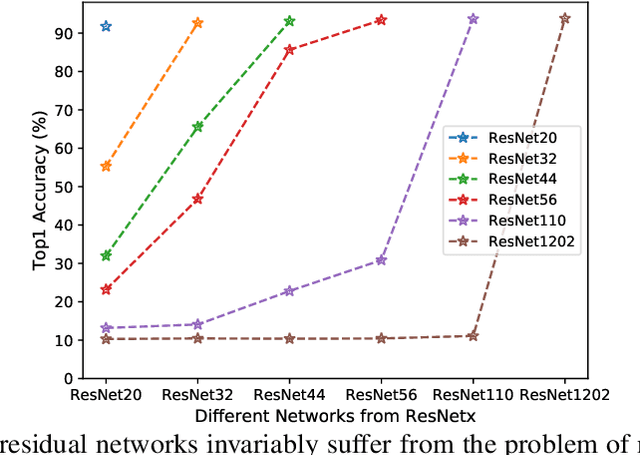
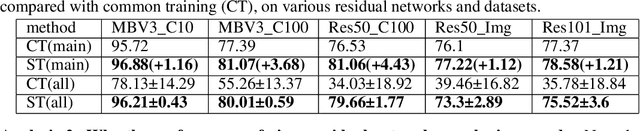
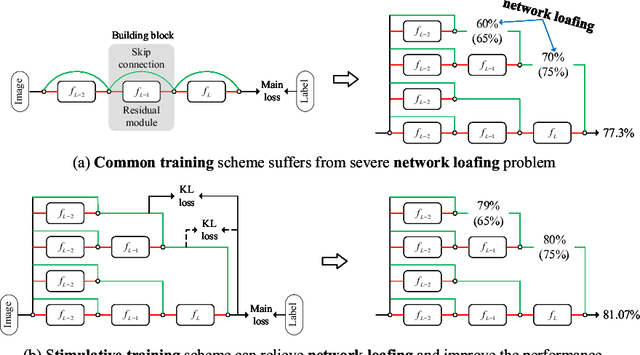
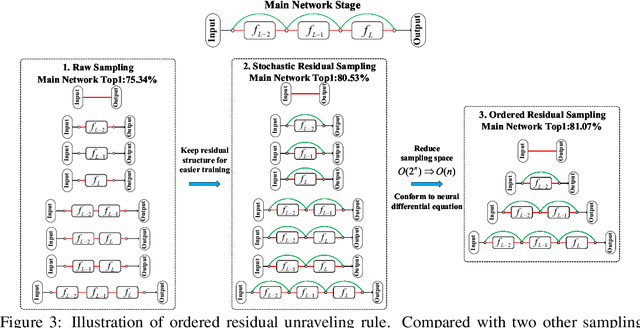
Residual networks have shown great success and become indispensable in today's deep models. In this work, we aim to re-investigate the training process of residual networks from a novel social psychology perspective of loafing, and further propose a new training strategy to strengthen the performance of residual networks. As residual networks can be viewed as ensembles of relatively shallow networks (i.e., \textit{unraveled view}) in prior works, we also start from such view and consider that the final performance of a residual network is co-determined by a group of sub-networks. Inspired by the social loafing problem of social psychology, we find that residual networks invariably suffer from similar problem, where sub-networks in a residual network are prone to exert less effort when working as part of the group compared to working alone. We define this previously overlooked problem as \textit{network loafing}. As social loafing will ultimately cause the low individual productivity and the reduced overall performance, network loafing will also hinder the performance of a given residual network and its sub-networks. Referring to the solutions of social psychology, we propose \textit{stimulative training}, which randomly samples a residual sub-network and calculates the KL-divergence loss between the sampled sub-network and the given residual network, to act as extra supervision for sub-networks and make the overall goal consistent. Comprehensive empirical results and theoretical analyses verify that stimulative training can well handle the loafing problem, and improve the performance of a residual network by improving the performance of its sub-networks. The code is available at https://github.com/Sunshine-Ye/NIPS22-ST .
Effective Invertible Arbitrary Image Rescaling
Sep 26, 2022
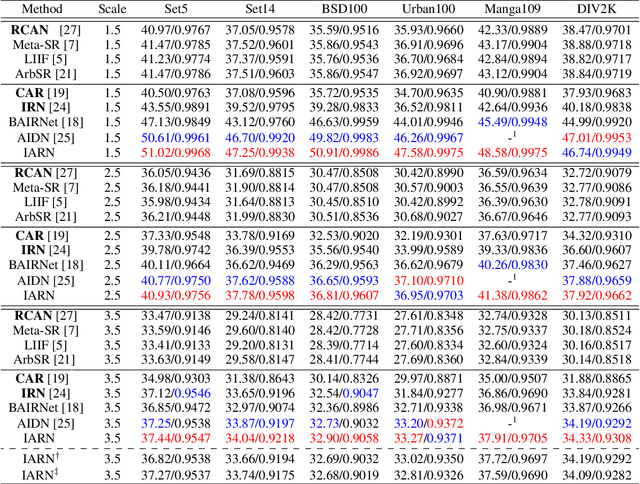
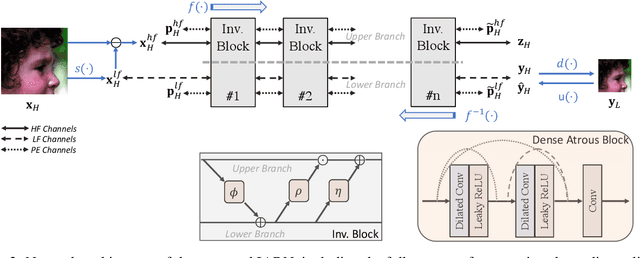
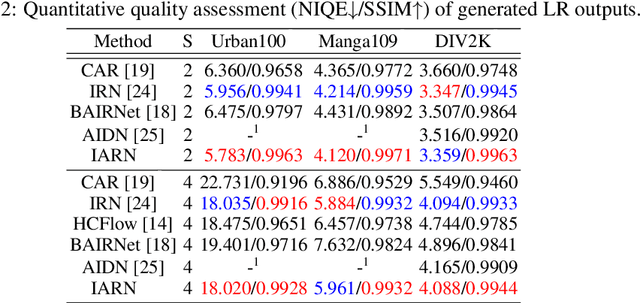
Great successes have been achieved using deep learning techniques for image super-resolution (SR) with fixed scales. To increase its real world applicability, numerous models have also been proposed to restore SR images with arbitrary scale factors, including asymmetric ones where images are resized to different scales along horizontal and vertical directions. Though most models are only optimized for the unidirectional upscaling task while assuming a predefined downscaling kernel for low-resolution (LR) inputs, recent models based on Invertible Neural Networks (INN) are able to increase upscaling accuracy significantly by optimizing the downscaling and upscaling cycle jointly. However, limited by the INN architecture, it is constrained to fixed integer scale factors and requires one model for each scale. Without increasing model complexity, a simple and effective invertible arbitrary rescaling network (IARN) is proposed to achieve arbitrary image rescaling by training only one model in this work. Using innovative components like position-aware scale encoding and preemptive channel splitting, the network is optimized to convert the non-invertible rescaling cycle to an effectively invertible process. It is shown to achieve a state-of-the-art (SOTA) performance in bidirectional arbitrary rescaling without compromising perceptual quality in LR outputs. It is also demonstrated to perform well on tests with asymmetric scales using the same network architecture.
Efficient Joint-Dimensional Search with Solution Space Regularization for Real-Time Semantic Segmentation
Aug 10, 2022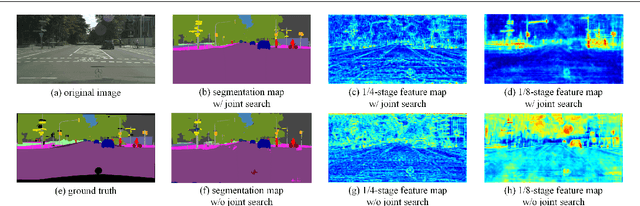
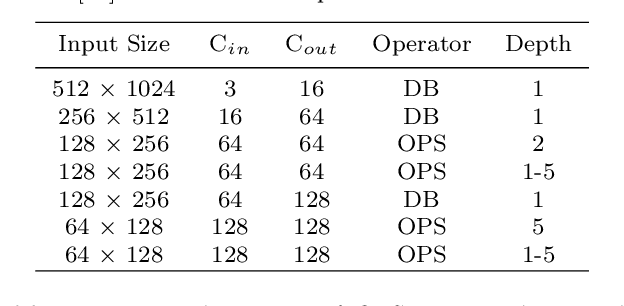
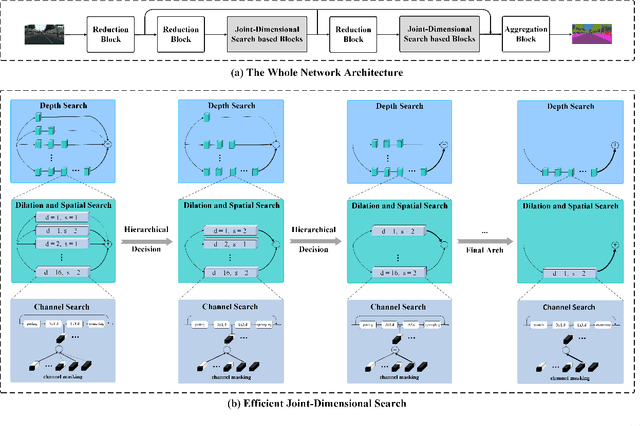
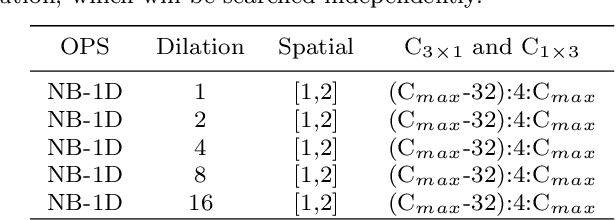
Semantic segmentation is a popular research topic in computer vision, and many efforts have been made on it with impressive results. In this paper, we intend to search an optimal network structure that can run in real-time for this problem. Towards this goal, we jointly search the depth, channel, dilation rate and feature spatial resolution, which results in a search space consisting of about 2.78*10^324 possible choices. To handle such a large search space, we leverage differential architecture search methods. However, the architecture parameters searched using existing differential methods need to be discretized, which causes the discretization gap between the architecture parameters found by the differential methods and their discretized version as the final solution for the architecture search. Hence, we relieve the problem of discretization gap from the innovative perspective of solution space regularization. Specifically, a novel Solution Space Regularization (SSR) loss is first proposed to effectively encourage the supernet to converge to its discrete one. Then, a new Hierarchical and Progressive Solution Space Shrinking method is presented to further achieve high efficiency of searching. In addition, we theoretically show that the optimization of SSR loss is equivalent to the L_0-norm regularization, which accounts for the improved search-evaluation gap. Comprehensive experiments show that the proposed search scheme can efficiently find an optimal network structure that yields an extremely fast speed (175 FPS) of segmentation with a small model size (1 M) while maintaining comparable accuracy.
SuperTickets: Drawing Task-Agnostic Lottery Tickets from Supernets via Jointly Architecture Searching and Parameter Pruning
Jul 08, 2022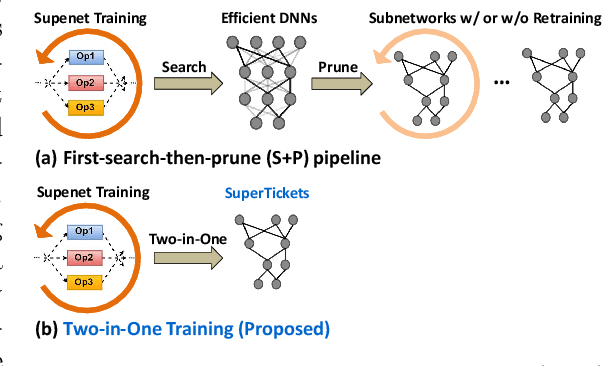
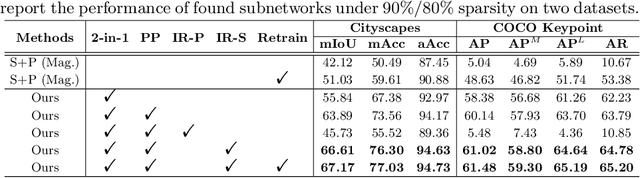
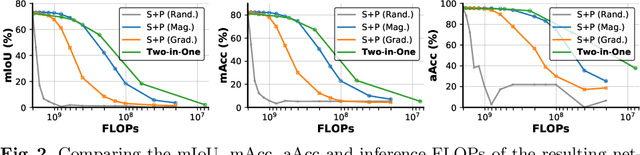
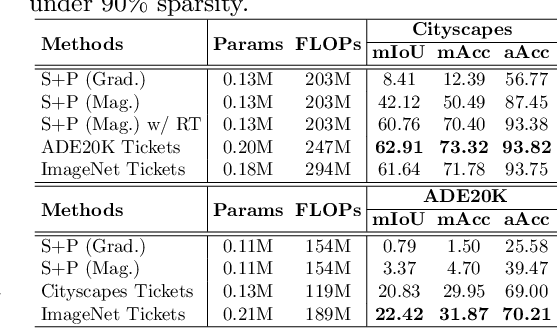
Neural architecture search (NAS) has demonstrated amazing success in searching for efficient deep neural networks (DNNs) from a given supernet. In parallel, the lottery ticket hypothesis has shown that DNNs contain small subnetworks that can be trained from scratch to achieve a comparable or higher accuracy than original DNNs. As such, it is currently a common practice to develop efficient DNNs via a pipeline of first search and then prune. Nevertheless, doing so often requires a search-train-prune-retrain process and thus prohibitive computational cost. In this paper, we discover for the first time that both efficient DNNs and their lottery subnetworks (i.e., lottery tickets) can be directly identified from a supernet, which we term as SuperTickets, via a two-in-one training scheme with jointly architecture searching and parameter pruning. Moreover, we develop a progressive and unified SuperTickets identification strategy that allows the connectivity of subnetworks to change during supernet training, achieving better accuracy and efficiency trade-offs than conventional sparse training. Finally, we evaluate whether such identified SuperTickets drawn from one task can transfer well to other tasks, validating their potential of handling multiple tasks simultaneously. Extensive experiments and ablation studies on three tasks and four benchmark datasets validate that our proposed SuperTickets achieve boosted accuracy and efficiency trade-offs than both typical NAS and pruning pipelines, regardless of having retraining or not. Codes and pretrained models are available at https://github.com/RICE-EIC/SuperTickets.