 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDS-Bench: Behavior of EHR-models under Distributional Shift--A Benchmark
Jul 17, 2021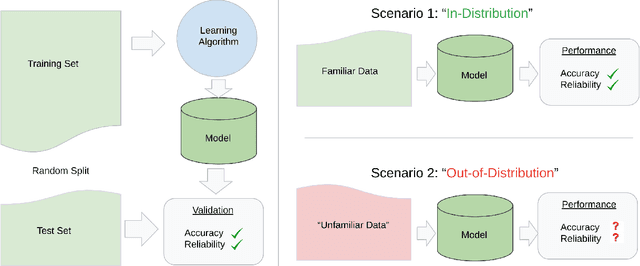
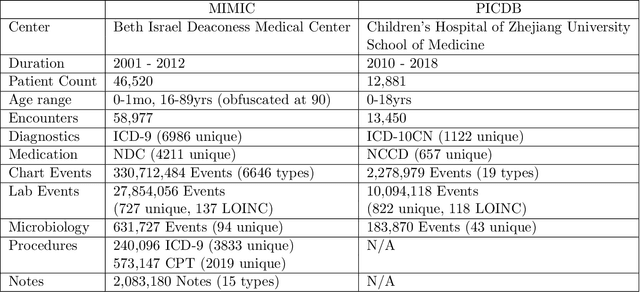
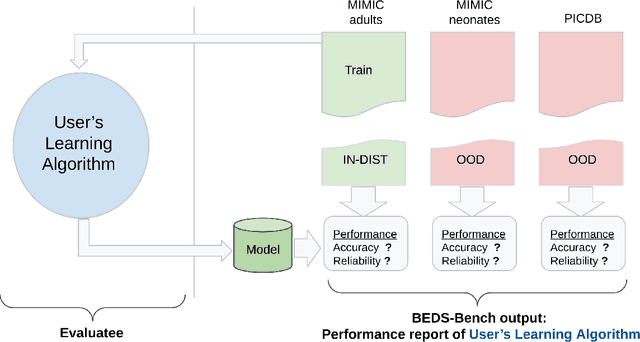
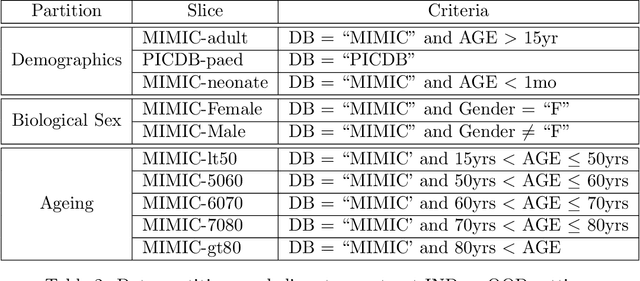
Machine learning has recently demonstrated impressive progress in predictive accuracy across a wide array of tasks. Most ML approaches focus on generalization performance on unseen data that are similar to the training data (In-Distribution, or IND). However, real world applications and deployments of ML rarely enjoy the comfort of encountering examples that are always IND. In such situations, most ML models commonly display erratic behavior on Out-of-Distribution (OOD) examples, such as assigning high confidence to wrong predictions, or vice-versa. Implications of such unusual model behavior are further exacerbated in the healthcare setting, where patient health can potentially be put at risk. It is crucial to study the behavior and robustness properties of models under distributional shift, understand common failure modes, and take mitigation steps before the model is deployed. Having a benchmark that shines light upon these aspects of a model is a first and necessary step in addressing the issue. Recent work and interest in increasing model robustness in OOD settings have focused more on image modality, while the Electronic Health Record (EHR) modality is still largely under-explored. We aim to bridge this gap by releasing BEDS-Bench, a benchmark for quantifying the behavior of ML models over EHR data under OOD settings. We use two open access, de-identified EHR datasets to construct several OOD data settings to run tests on, and measure relevant metrics that characterize crucial aspects of a model's OOD behavior. We evaluate several learning algorithms under BEDS-Bench and find that all of them show poor generalization performance under distributional shift in general. Our results highlight the need and the potential to improve robustness of EHR models under distributional shift, and BEDS-Bench provides one way to measure progress towards that goal.
Task-agnostic Continual Learning with Hybrid Probabilistic Models
Jun 24, 2021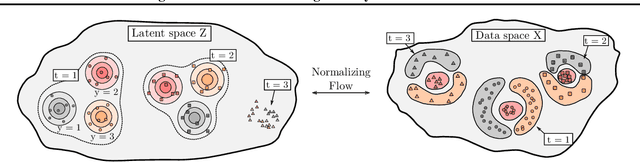
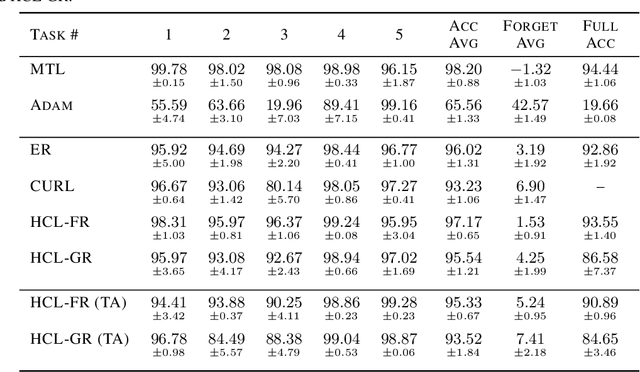
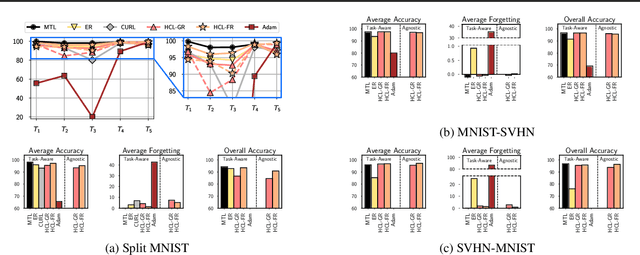
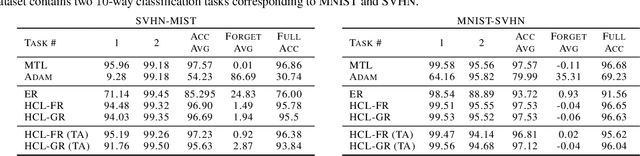
Learning new tasks continuously without forgetting on a constantly changing data distribution is essential for real-world problems but extremely challenging for modern deep learning. In this work we propose HCL, a Hybrid generative-discriminative approach to Continual Learning for classification. We model the distribution of each task and each class with a normalizing flow. The flow is used to learn the data distribution, perform classification, identify task changes, and avoid forgetting, all leveraging the invertibility and exact likelihood which are uniquely enabled by the normalizing flow model. We use the generative capabilities of the flow to avoid catastrophic forgetting through generative replay and a novel functional regularization technique. For task identification, we use state-of-the-art anomaly detection techniques based on measuring the typicality of the model's statistics. We demonstrate the strong performance of HCL on a range of continual learning benchmarks such as split-MNIST, split-CIFAR, and SVHN-MNIST.
A Simple Fix to Mahalanobis Distance for Improving Near-OOD Detection
Jun 16, 2021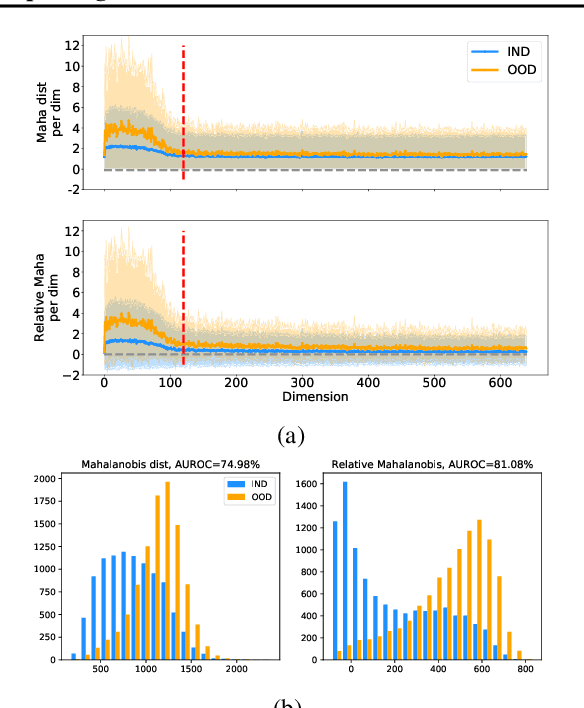
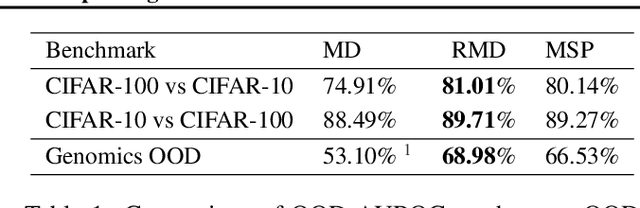
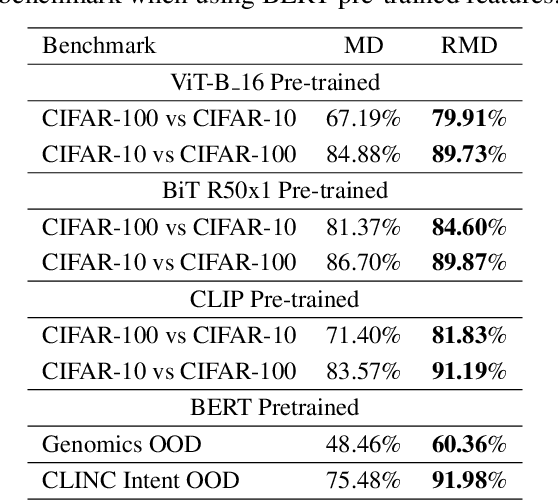
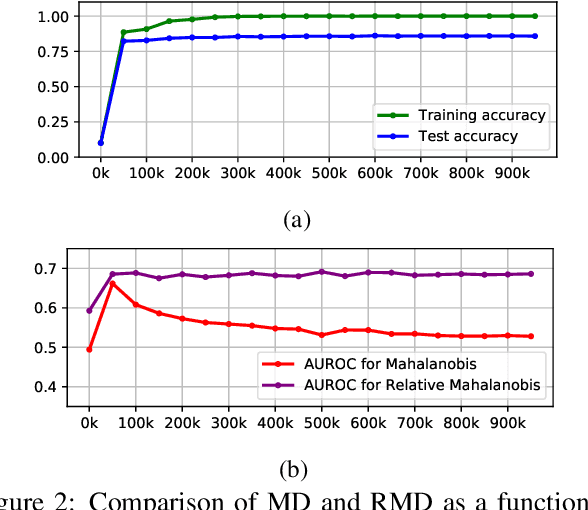
Mahalanobis distance (MD) is a simple and popular post-processing method for detecting out-of-distribution (OOD) inputs in neural networks. We analyze its failure modes for near-OOD detection and propose a simple fix called relative Mahalanobis distance (RMD) which improves performance and is more robust to hyperparameter choice. On a wide selection of challenging vision, language, and biology OOD benchmarks (CIFAR-100 vs CIFAR-10, CLINC OOD intent detection, Genomics OOD), we show that RMD meaningfully improves upon MD performance (by up to 15% AUROC on genomics OOD).
Predicting Unreliable Predictions by Shattering a Neural Network
Jun 15, 2021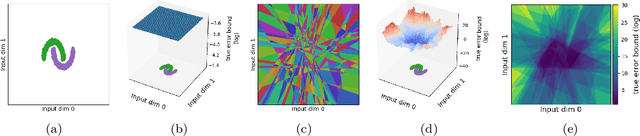
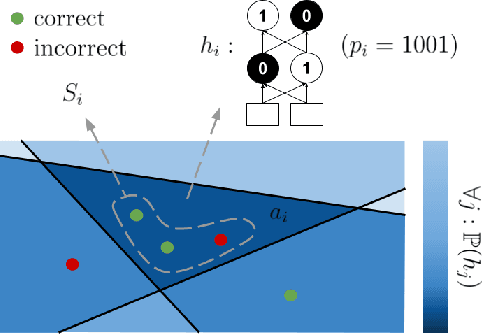

Piecewise linear neural networks can be split into subfunctions, each with its own activation pattern, domain, and empirical error. Empirical error for the full network can be written as an expectation over empirical error of subfunctions. Constructing a generalization bound on subfunction empirical error indicates that the more densely a subfunction is surrounded by training samples in representation space, the more reliable its predictions are. Further, it suggests that models with fewer activation regions generalize better, and models that abstract knowledge to a greater degree generalize better, all else equal. We propose not only a theoretical framework to reason about subfunction error bounds but also a pragmatic way of approximately evaluating it, which we apply to predicting which samples the network will not successfully generalize to. We test our method on detection of misclassification and out-of-distribution samples, finding that it performs competitively in both cases. In short, some network activation patterns are associated with higher reliability than others, and these can be identified using subfunction error bounds.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021
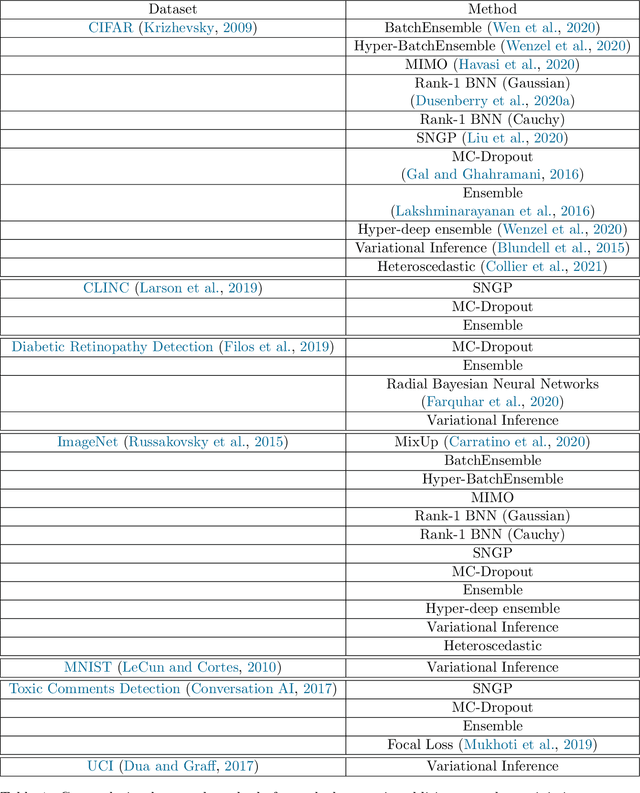
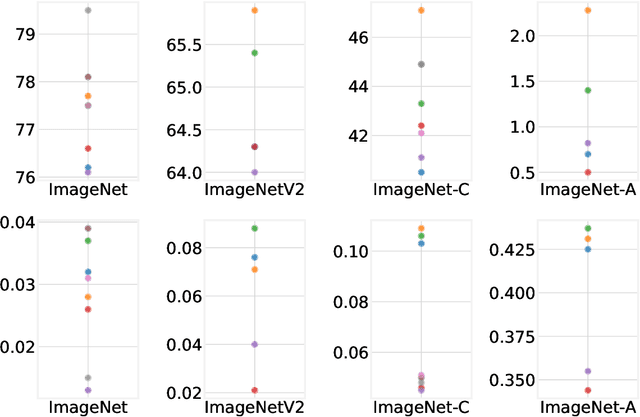
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Exploring the Limits of Out-of-Distribution Detection
Jun 06, 2021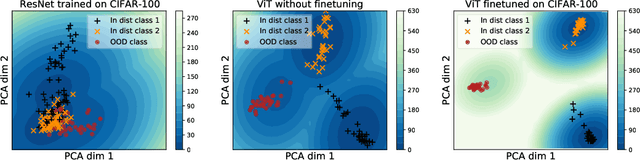
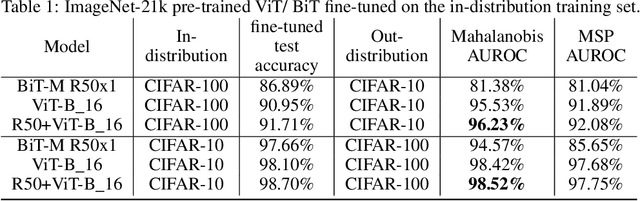
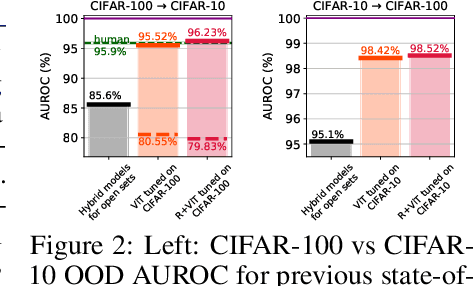

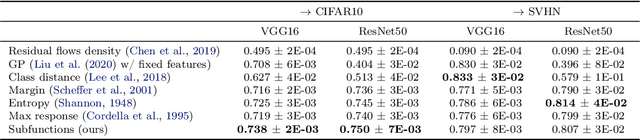
Near out-of-distribution detection (OOD) is a major challenge for deep neural networks. We demonstrate that large-scale pre-trained transformers can significantly improve the state-of-the-art (SOTA) on a range of near OOD tasks across different data modalities. For instance, on CIFAR-100 vs CIFAR-10 OOD detection, we improve the AUROC from 85% (current SOTA) to more than 96% using Vision Transformers pre-trained on ImageNet-21k. On a challenging genomics OOD detection benchmark, we improve the AUROC from 66% to 77% using transformers and unsupervised pre-training. To further improve performance, we explore the few-shot outlier exposure setting where a few examples from outlier classes may be available; we show that pre-trained transformers are particularly well-suited for outlier exposure, and that the AUROC of OOD detection on CIFAR-100 vs CIFAR-10 can be improved to 98.7% with just 1 image per OOD class, and 99.46% with 10 images per OOD class. For multi-modal image-text pre-trained transformers such as CLIP, we explore a new way of using just the names of outlier classes as a sole source of information without any accompanying images, and show that this outperforms previous SOTA on standard vision OOD benchmark tasks.
Does Your Dermatology Classifier Know What It Doesn't Know? Detecting the Long-Tail of Unseen Conditions
Apr 08, 2021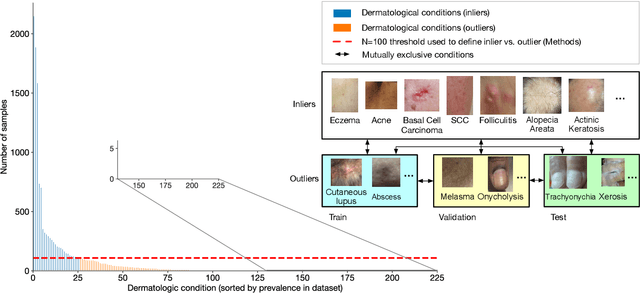
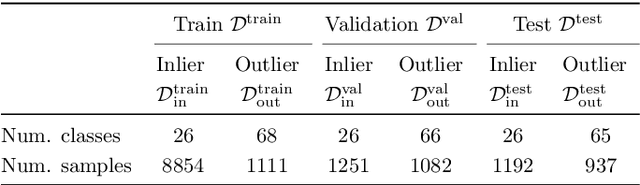
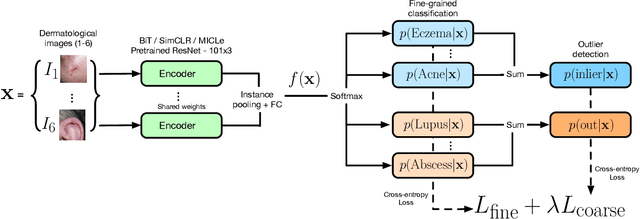
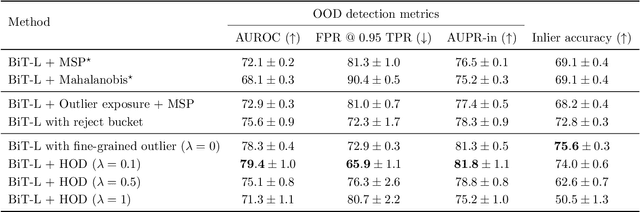
We develop and rigorously evaluate a deep learning based system that can accurately classify skin conditions while detecting rare conditions for which there is not enough data available for training a confident classifier. We frame this task as an out-of-distribution (OOD) detection problem. Our novel approach, hierarchical outlier detection (HOD) assigns multiple abstention classes for each training outlier class and jointly performs a coarse classification of inliers vs. outliers, along with fine-grained classification of the individual classes. We demonstrate the effectiveness of the HOD loss in conjunction with modern representation learning approaches (BiT, SimCLR, MICLe) and explore different ensembling strategies for further improving the results. We perform an extensive subgroup analysis over conditions of varying risk levels and different skin types to investigate how the OOD detection performance changes over each subgroup and demonstrate the gains of our framework in comparison to baselines. Finally, we introduce a cost metric to approximate downstream clinical impact. We use this cost metric to compare the proposed method against a baseline system, thereby making a stronger case for the overall system effectiveness in a real-world deployment scenario.
Combining Ensembles and Data Augmentation can Harm your Calibration
Oct 19, 2020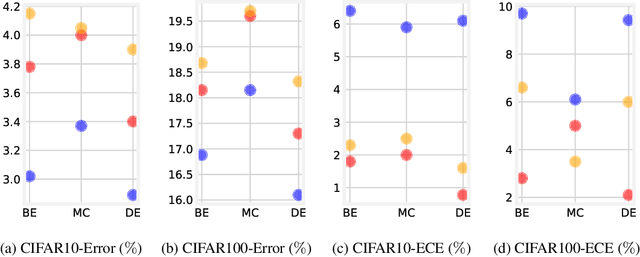
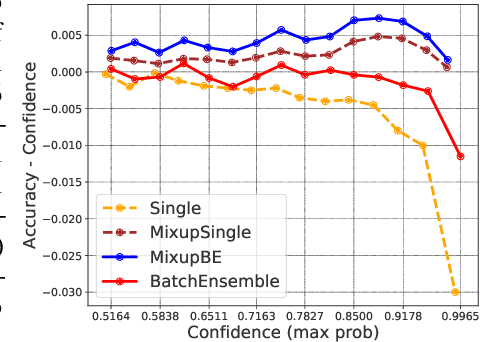
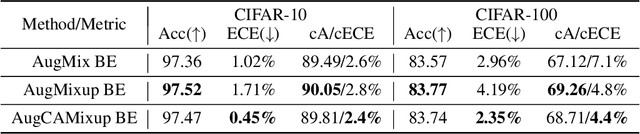
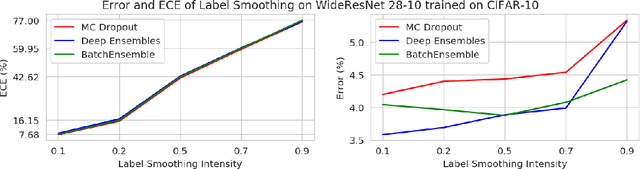
Ensemble methods which average over multiple neural network predictions are a simple approach to improve a model's calibration and robustness. Similarly, data augmentation techniques, which encode prior information in the form of invariant feature transformations, are effective for improving calibration and robustness. In this paper, we show a surprising pathology: combining ensembles and data augmentation can harm model calibration. This leads to a trade-off in practice, whereby improved accuracy by combining the two techniques comes at the expense of calibration. On the other hand, selecting only one of the techniques ensures good uncertainty estimates at the expense of accuracy. We investigate this pathology and identify a compounding under-confidence among methods which marginalize over sets of weights and data augmentation techniques which soften labels. Finally, we propose a simple correction, achieving the best of both worlds with significant accuracy and calibration gains over using only ensembles or data augmentation individually. Applying the correction produces new state-of-the art in uncertainty calibration across CIFAR-10, CIFAR-100, and ImageNet.
Training independent subnetworks for robust prediction
Oct 13, 2020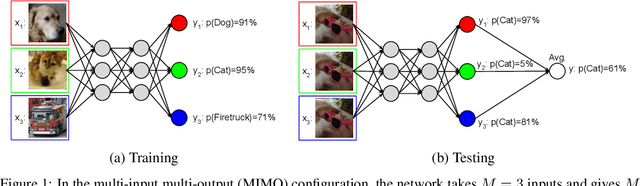
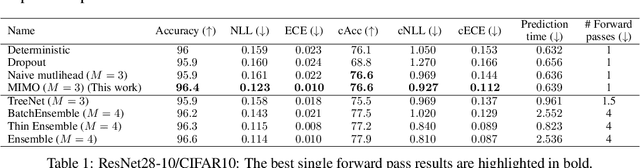

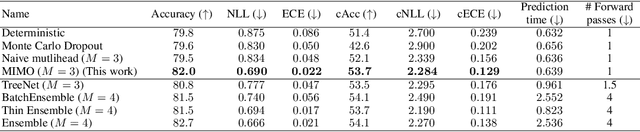
Recent approaches to efficiently ensemble neural networks have shown that strong robustness and uncertainty performance can be achieved with a negligible gain in parameters over the original network. However, these methods still require multiple forward passes for prediction, leading to a significant computational cost. In this work, we show a surprising result: the benefits of using multiple predictions can be achieved `for free' under a single model's forward pass. In particular, we show that, using a multi-input multi-output (MIMO) configuration, one can utilize a single model's capacity to train multiple subnetworks that independently learn the task at hand. By ensembling the predictions made by the subnetworks, we improve model robustness without increasing compute. We observe a significant improvement in negative log-likelihood, accuracy, and calibration error on CIFAR10, CIFAR100, ImageNet, and their out-of-distribution variants compared to previous methods.
Evaluating Prediction-Time Batch Normalization for Robustness under Covariate Shift
Jul 17, 2020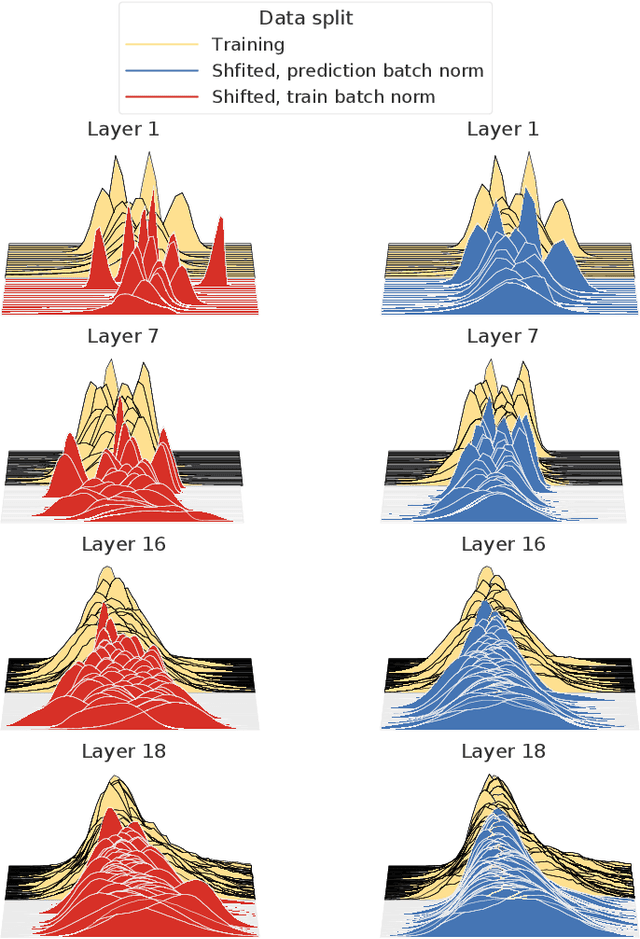
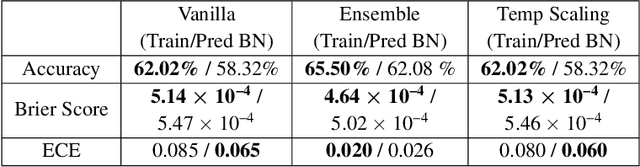
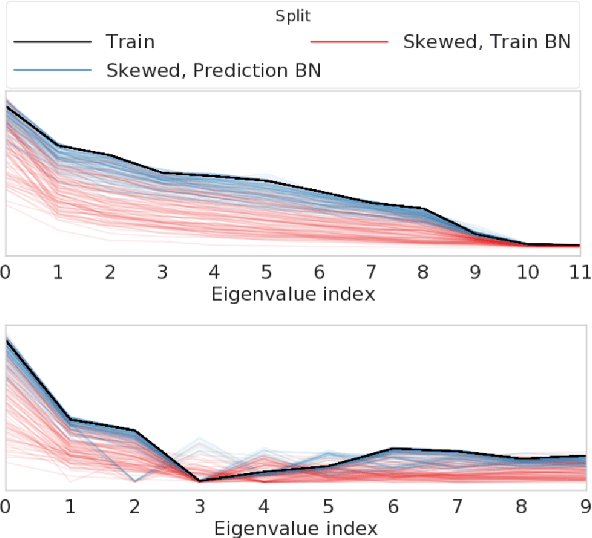
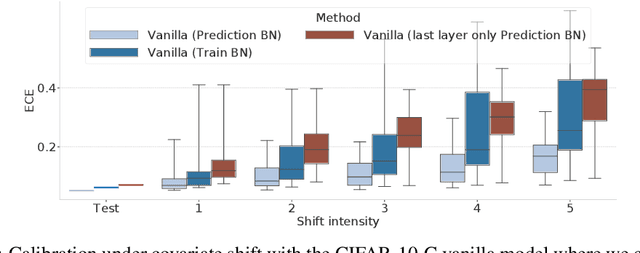
Covariate shift has been shown to sharply degrade both predictive accuracy and the calibration of uncertainty estimates for deep learning models. This is worrying, because covariate shift is prevalent in a wide range of real world deployment settings. However, in this paper, we note that frequently there exists the potential to access small unlabeled batches of the shifted data just before prediction time. This interesting observation enables a simple but surprisingly effective method which we call prediction-time batch normalization, which significantly improves model accuracy and calibration under covariate shift. Using this one line code change, we achieve state-of-the-art on recent covariate shift benchmarks and an mCE of 60.28\% on the challenging ImageNet-C dataset; to our knowledge, this is the best result for any model that does not incorporate additional data augmentation or modification of the training pipeline. We show that prediction-time batch normalization provides complementary benefits to existing state-of-the-art approaches for improving robustness (e.g. deep ensembles) and combining the two further improves performance. Our findings are supported by detailed measurements of the effect of this strategy on model behavior across rigorous ablations on various dataset modalities. However, the method has mixed results when used alongside pre-training, and does not seem to perform as well under more natural types of dataset shift, and is therefore worthy of additional study. We include links to the data in our figures to improve reproducibility, including a Python notebooks that can be run to easily modify our analysis at https://colab.research.google.com/drive/11N0wDZnMQQuLrRwRoumDCrhSaIhkqjof.