 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: AI Competitions Provide the Gold Standard for Empirical Rigor in GenAI Evaluation
May 01, 2025In this position paper, we observe that empirical evaluation in Generative AI is at a crisis point since traditional ML evaluation and benchmarking strategies are insufficient to meet the needs of evaluating modern GenAI models and systems. There are many reasons for this, including the fact that these models typically have nearly unbounded input and output spaces, typically do not have a well defined ground truth target, and typically exhibit strong feedback loops and prediction dependence based on context of previous model outputs. On top of these critical issues, we argue that the problems of {\em leakage} and {\em contamination} are in fact the most important and difficult issues to address for GenAI evaluations. Interestingly, the field of AI Competitions has developed effective measures and practices to combat leakage for the purpose of counteracting cheating by bad actors within a competition setting. This makes AI Competitions an especially valuable (but underutilized) resource. Now is time for the field to view AI Competitions as the gold standard for empirical rigor in GenAI evaluation, and to harness and harvest their results with according value.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023


The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022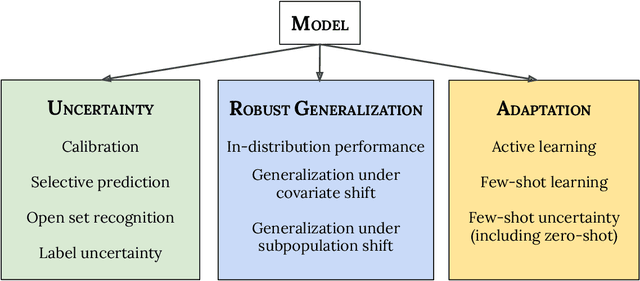

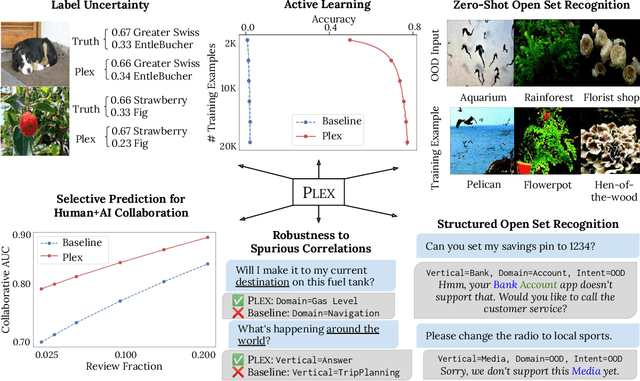

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021
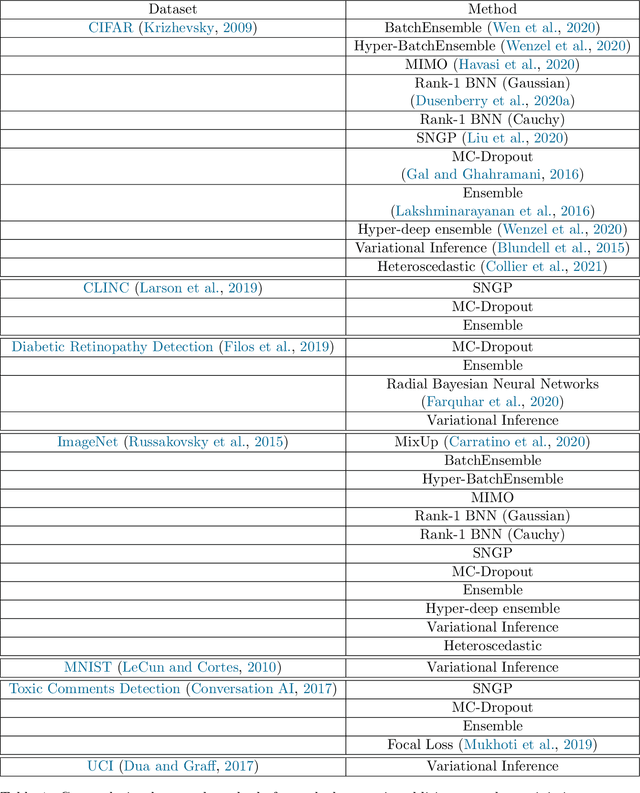
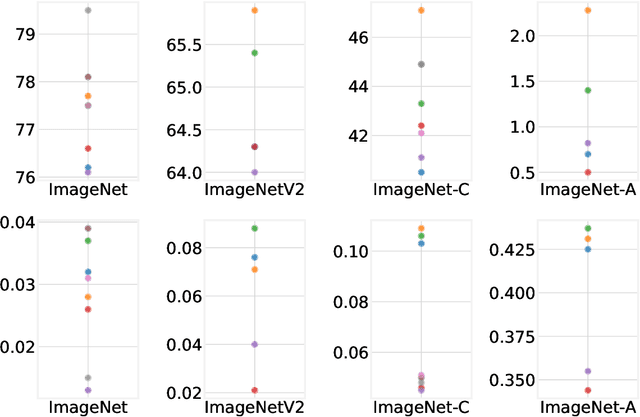
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


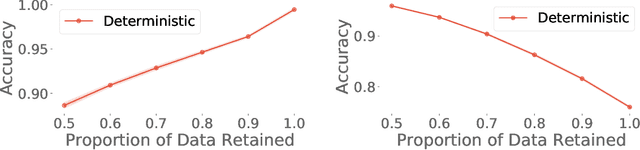
ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
Evaluating Prediction-Time Batch Normalization for Robustness under Covariate Shift
Jul 17, 2020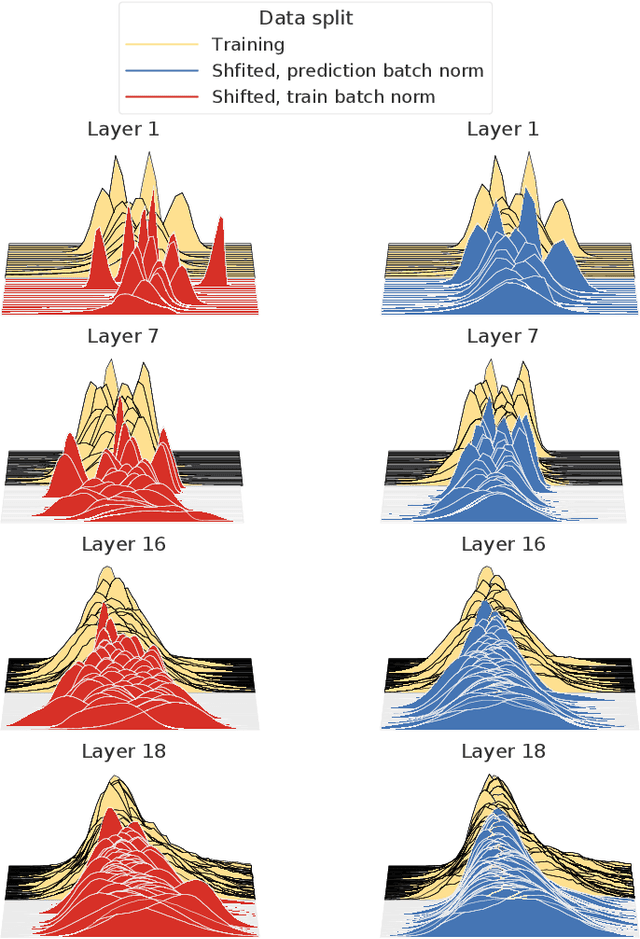
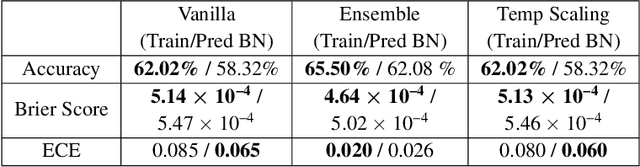
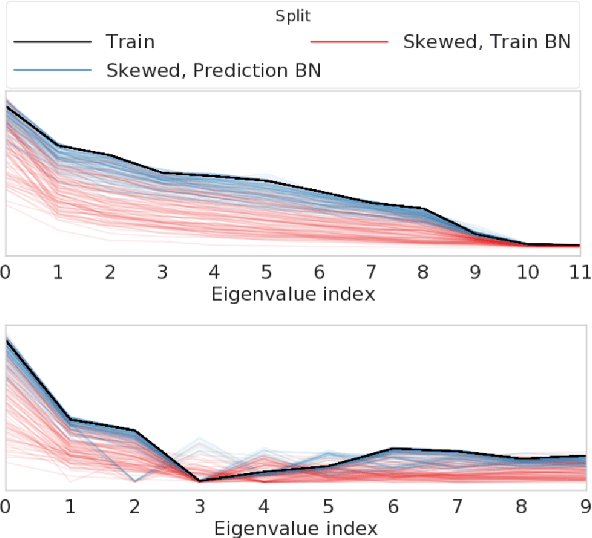
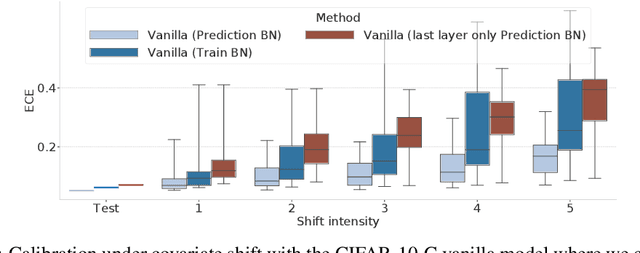
Covariate shift has been shown to sharply degrade both predictive accuracy and the calibration of uncertainty estimates for deep learning models. This is worrying, because covariate shift is prevalent in a wide range of real world deployment settings. However, in this paper, we note that frequently there exists the potential to access small unlabeled batches of the shifted data just before prediction time. This interesting observation enables a simple but surprisingly effective method which we call prediction-time batch normalization, which significantly improves model accuracy and calibration under covariate shift. Using this one line code change, we achieve state-of-the-art on recent covariate shift benchmarks and an mCE of 60.28\% on the challenging ImageNet-C dataset; to our knowledge, this is the best result for any model that does not incorporate additional data augmentation or modification of the training pipeline. We show that prediction-time batch normalization provides complementary benefits to existing state-of-the-art approaches for improving robustness (e.g. deep ensembles) and combining the two further improves performance. Our findings are supported by detailed measurements of the effect of this strategy on model behavior across rigorous ablations on various dataset modalities. However, the method has mixed results when used alongside pre-training, and does not seem to perform as well under more natural types of dataset shift, and is therefore worthy of additional study. We include links to the data in our figures to improve reproducibility, including a Python notebooks that can be run to easily modify our analysis at https://colab.research.google.com/drive/11N0wDZnMQQuLrRwRoumDCrhSaIhkqjof.
TensorFlow.js: Machine Learning for the Web and Beyond
Jan 16, 2019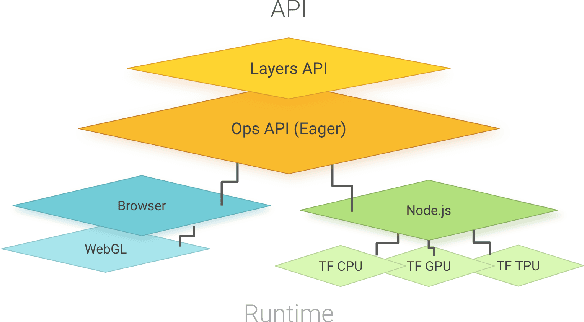
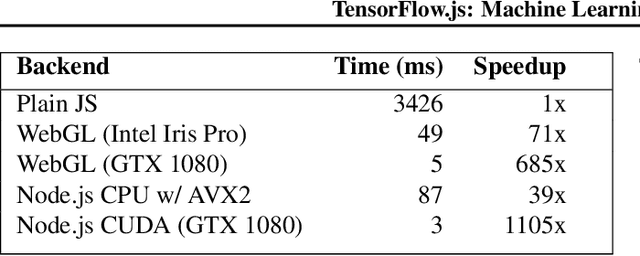


TensorFlow.js is a library for building and executing machine learning algorithms in JavaScript. TensorFlow.js models run in a web browser and in the Node.js environment. The library is part of the TensorFlow ecosystem, providing a set of APIs that are compatible with those in Python, allowing models to be ported between the Python and JavaScript ecosystems. TensorFlow.js has empowered a new set of developers from the extensive JavaScript community to build and deploy machine learning models and enabled new classes of on-device computation. This paper describes the design, API, and implementation of TensorFlow.js, and highlights some of the impactful use cases.
BriarPatches: Pixel-Space Interventions for Inducing Demographic Parity
Dec 17, 2018
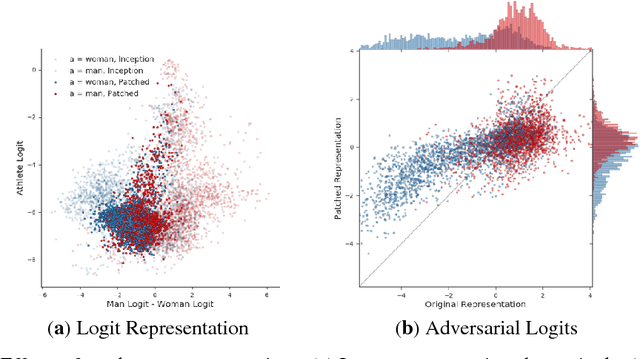
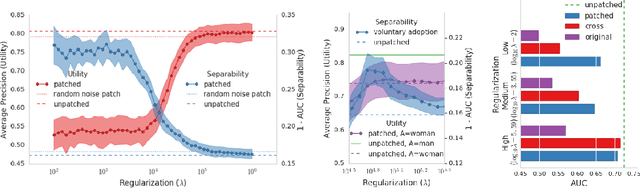
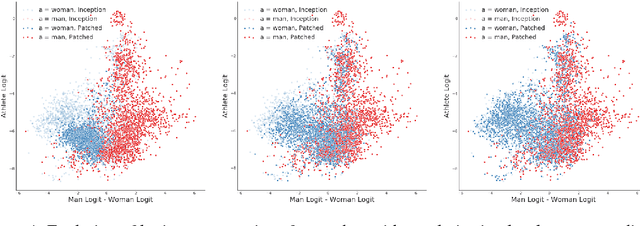
We introduce the BriarPatch, a pixel-space intervention that obscures sensitive attributes from representations encoded in pre-trained classifiers. The patches encourage internal model representations not to encode sensitive information, which has the effect of pushing downstream predictors towards exhibiting demographic parity with respect to the sensitive information. The net result is that these BriarPatches provide an intervention mechanism available at user level, and complements prior research on fair representations that were previously only applicable by model developers and ML experts.