 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-shot Generalization and Robustness of Multi-modal Models
Dec 04, 2022



Multi-modal image-text models such as CLIP and LiT have demonstrated impressive performance on image classification benchmarks and their zero-shot generalization ability is particularly exciting. While the top-5 zero-shot accuracies of these models are very high, the top-1 accuracies are much lower (over 25% gap in some cases). We investigate the reasons for this performance gap and find that many of the failure cases are caused by ambiguity in the text prompts. First, we develop a simple and efficient zero-shot post-hoc method to identify images whose top-1 prediction is likely to be incorrect, by measuring consistency of the predictions w.r.t. multiple prompts and image transformations. We show that our procedure better predicts mistakes, outperforming the popular max logit baseline on selective prediction tasks. Next, we propose a simple and efficient way to improve accuracy on such uncertain images by making use of the WordNet hierarchy; specifically we augment the original class by incorporating its parent and children from the semantic label hierarchy, and plug the augmentation into text promts. We conduct experiments on both CLIP and LiT models with five different ImageNet-based datasets. For CLIP, our method improves the top-1 accuracy by 17.13% on the uncertain subset and 3.6% on the entire ImageNet validation set. We also show that our method improves across ImageNet shifted datasets and other model architectures such as LiT. Our proposed method is hyperparameter-free, requires no additional model training and can be easily scaled to other large multi-modal architectures.
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Sep 30, 2022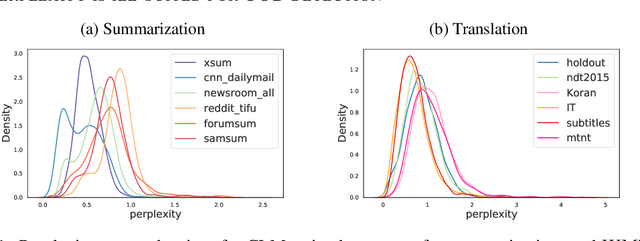
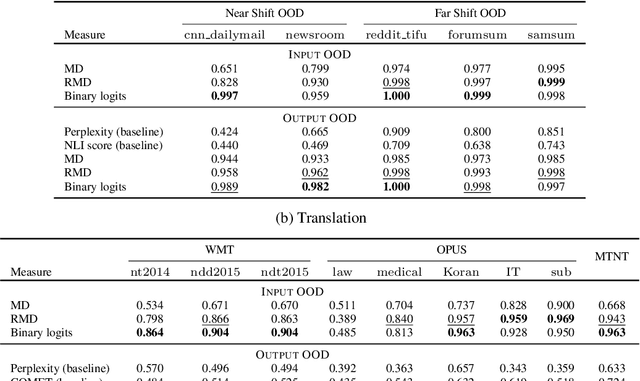
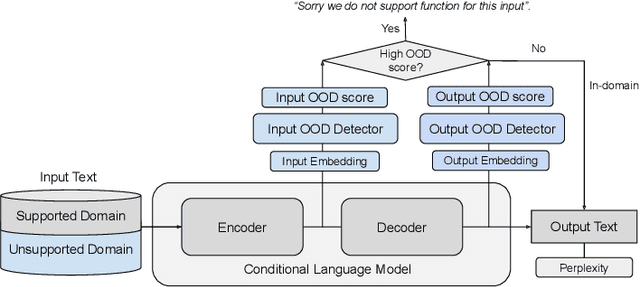
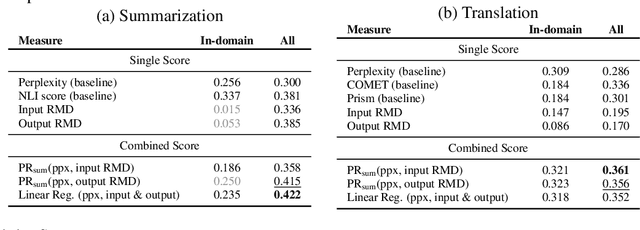
Machine learning algorithms typically assume independent and identically distributed samples in training and at test time. Much work has shown that high-performing ML classifiers can degrade significantly and provide overly-confident, wrong classification predictions, particularly for out-of-distribution (OOD) inputs. Conditional language models (CLMs) are predominantly trained to classify the next token in an output sequence, and may suffer even worse degradation on OOD inputs as the prediction is done auto-regressively over many steps. Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output. We present a highly accurate and lightweight OOD detection method for CLMs, and demonstrate its effectiveness on abstractive summarization and translation. We also show how our method can be used under the common and realistic setting of distribution shift for selective generation (analogous to selective prediction for classification) of high-quality outputs, while automatically abstaining from low-quality ones, enabling safer deployment of generative language models.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022

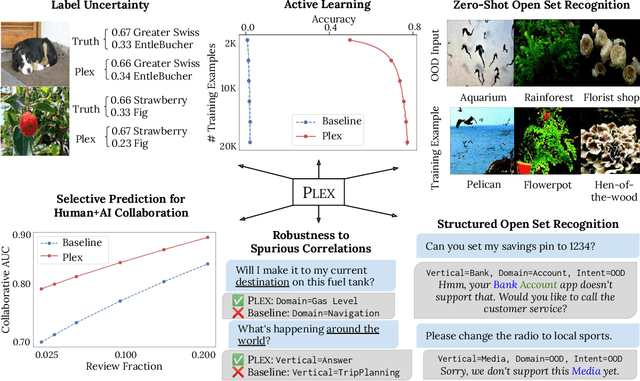

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
A Simple Approach to Improve Single-Model Deep Uncertainty via Distance-Awareness
May 01, 2022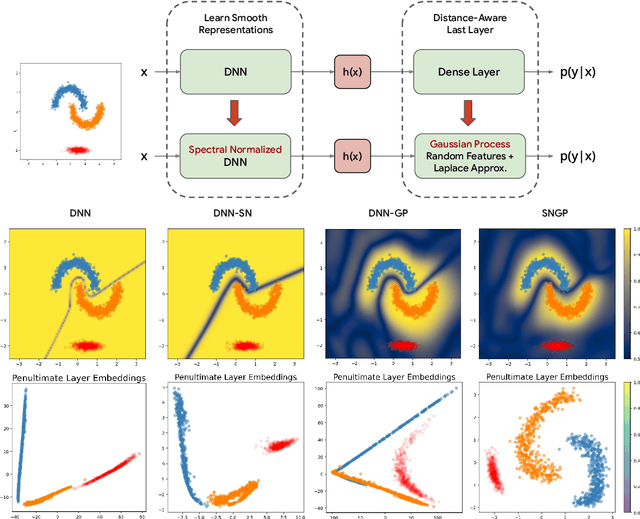
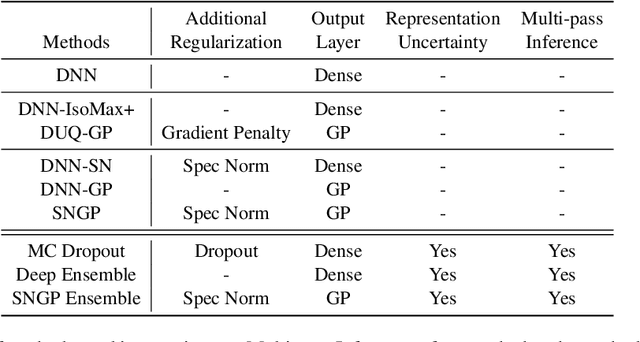
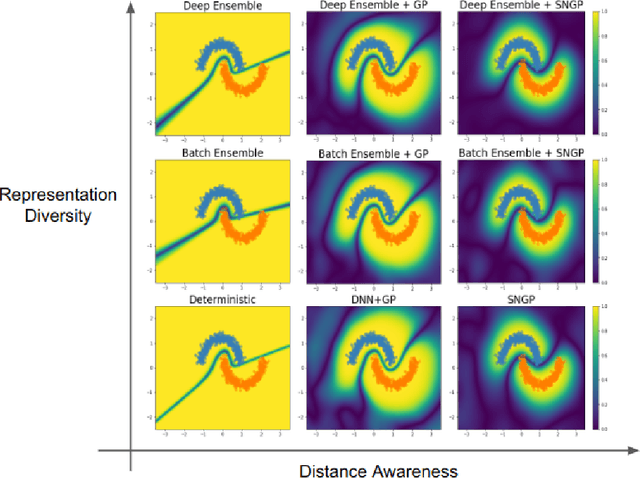
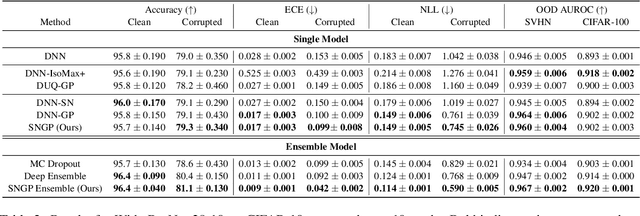
Accurate uncertainty quantification is a major challenge in deep learning, as neural networks can make overconfident errors and assign high confidence predictions to out-of-distribution (OOD) inputs. The most popular approaches to estimate predictive uncertainty in deep learning are methods that combine predictions from multiple neural networks, such as Bayesian neural networks (BNNs) and deep ensembles. However their practicality in real-time, industrial-scale applications are limited due to the high memory and computational cost. Furthermore, ensembles and BNNs do not necessarily fix all the issues with the underlying member networks. In this work, we study principled approaches to improve uncertainty property of a single network, based on a single, deterministic representation. By formalizing the uncertainty quantification as a minimax learning problem, we first identify distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs with two simple changes: (1) applying spectral normalization to hidden weights to enforce bi-Lipschitz smoothness in representations and (2) replacing the last output layer with a Gaussian process layer. On a suite of vision and language understanding benchmarks, SNGP outperforms other single-model approaches in prediction, calibration and out-of-domain detection. Furthermore, SNGP provides complementary benefits to popular techniques such as deep ensembles and data augmentation, making it a simple and scalable building block for probabilistic deep learning. Code is open-sourced at https://github.com/google/uncertainty-baselines
Reliable Graph Neural Networks for Drug Discovery Under Distributional Shift
Nov 25, 2021
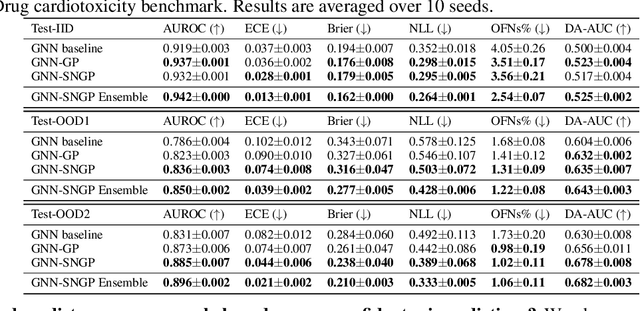
The concern of overconfident mis-predictions under distributional shift demands extensive reliability research on Graph Neural Networks used in critical tasks in drug discovery. Here we first introduce CardioTox, a real-world benchmark on drug cardio-toxicity to facilitate such efforts. Our exploratory study shows overconfident mis-predictions are often distant from training data. That leads us to develop distance-aware GNNs: GNN-SNGP. Through evaluation on CardioTox and three established benchmarks, we demonstrate GNN-SNGP's effectiveness in increasing distance-awareness, reducing overconfident mis-predictions and making better calibrated predictions without sacrificing accuracy performance. Our ablation study further reveals the representation learned by GNN-SNGP improves distance-preservation over its base architecture and is one major factor for improvements.
Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation
Oct 15, 2021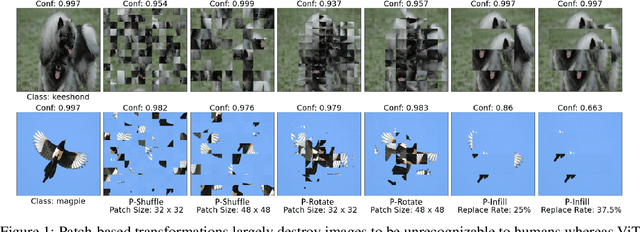

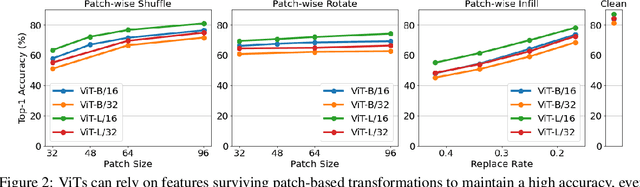
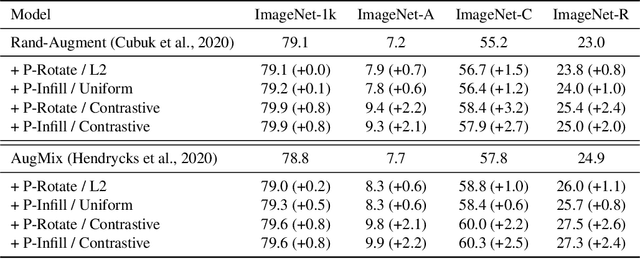
We investigate the robustness of vision transformers (ViTs) through the lens of their special patch-based architectural structure, i.e., they process an image as a sequence of image patches. We find that ViTs are surprisingly insensitive to patch-based transformations, even when the transformation largely destroys the original semantics and makes the image unrecognizable by humans. This indicates that ViTs heavily use features that survived such transformations but are generally not indicative of the semantic class to humans. Further investigations show that these features are useful but non-robust, as ViTs trained on them can achieve high in-distribution accuracy, but break down under distribution shifts. From this understanding, we ask: can training the model to rely less on these features improve ViT robustness and out-of-distribution performance? We use the images transformed with our patch-based operations as negatively augmented views and offer losses to regularize the training away from using non-robust features. This is a complementary view to existing research that mostly focuses on augmenting inputs with semantic-preserving transformations to enforce models' invariance. We show that patch-based negative augmentation consistently improves robustness of ViTs across a wide set of ImageNet based robustness benchmarks. Furthermore, we find our patch-based negative augmentation are complementary to traditional (positive) data augmentation, and together boost the performance further. All the code in this work will be open-sourced.
Sparse MoEs meet Efficient Ensembles
Oct 07, 2021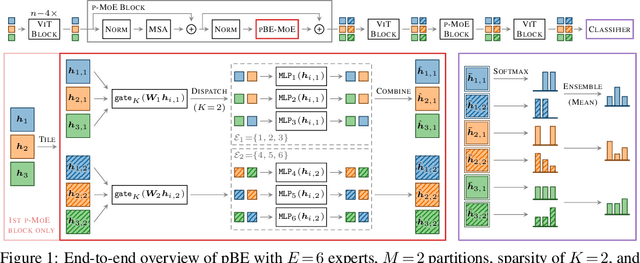

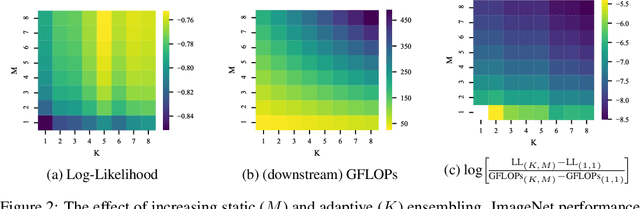
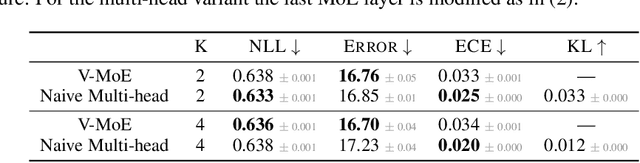
Machine learning models based on the aggregated outputs of submodels, either at the activation or prediction levels, lead to strong performance. We study the interplay of two popular classes of such models: ensembles of neural networks and sparse mixture of experts (sparse MoEs). First, we show that these two approaches have complementary features whose combination is beneficial. Then, we present partitioned batch ensembles, an efficient ensemble of sparse MoEs that takes the best of both classes of models. Extensive experiments on fine-tuned vision transformers demonstrate the accuracy, log-likelihood, few-shot learning, robustness, and uncertainty calibration improvements of our approach over several challenging baselines. Partitioned batch ensembles not only scale to models with up to 2.7B parameters, but also provide larger performance gains for larger models.
Deep Classifiers with Label Noise Modeling and Distance Awareness
Oct 06, 2021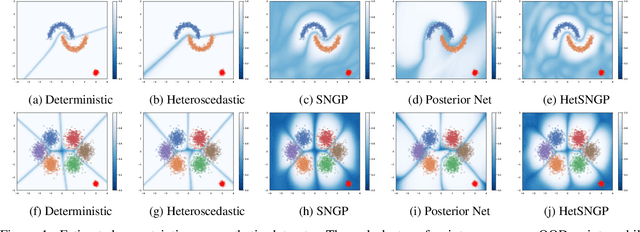



Uncertainty estimation in deep learning has recently emerged as a crucial area of interest to advance reliability and robustness in safety-critical applications. While there have been many proposed methods that either focus on distance-aware model uncertainties for out-of-distribution detection or on input-dependent label uncertainties for in-distribution calibration, both of these types of uncertainty are often necessary. In this work, we propose the HetSNGP method for jointly modeling the model and data uncertainty. We show that our proposed model affords a favorable combination between these two complementary types of uncertainty and thus outperforms the baseline methods on some challenging out-of-distribution datasets, including CIFAR-100C, Imagenet-C, and Imagenet-A. Moreover, we propose HetSNGP Ensemble, an ensembled version of our method which adds an additional type of uncertainty and also outperforms other ensemble baselines.
Soft Calibration Objectives for Neural Networks
Jul 30, 2021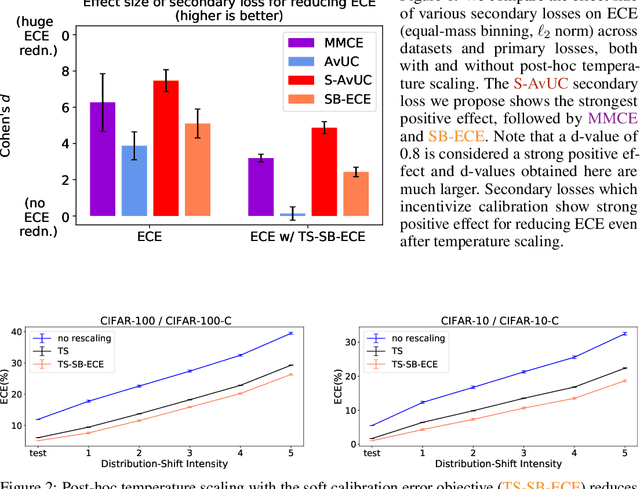
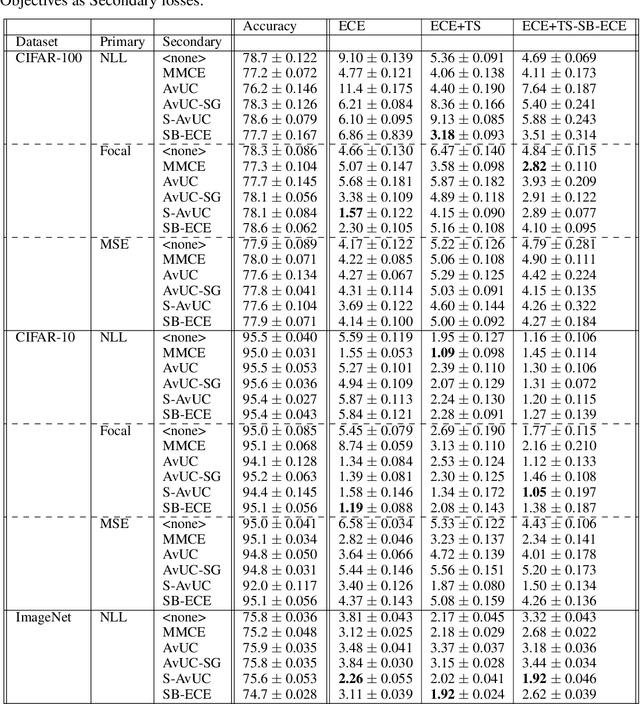
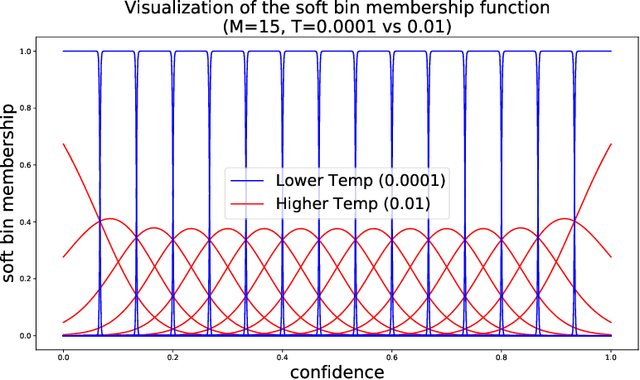
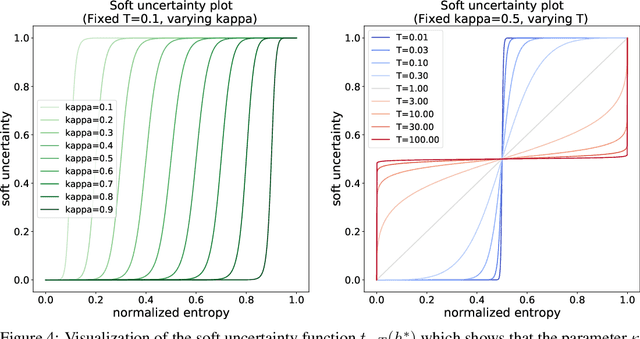
Optimal decision making requires that classifiers produce uncertainty estimates consistent with their empirical accuracy. However, deep neural networks are often under- or over-confident in their predictions. Consequently, methods have been developed to improve the calibration of their predictive uncertainty both during training and post-hoc. In this work, we propose differentiable losses to improve calibration based on a soft (continuous) version of the binning operation underlying popular calibration-error estimators. When incorporated into training, these soft calibration losses achieve state-of-the-art single-model ECE across multiple datasets with less than 1% decrease in accuracy. For instance, we observe an 82% reduction in ECE (70% relative to the post-hoc rescaled ECE) in exchange for a 0.7% relative decrease in accuracy relative to the cross entropy baseline on CIFAR-100. When incorporated post-training, the soft-binning-based calibration error objective improves upon temperature scaling, a popular recalibration method. Overall, experiments across losses and datasets demonstrate that using calibration-sensitive procedures yield better uncertainty estimates under dataset shift than the standard practice of using a cross entropy loss and post-hoc recalibration methods.
A Realistic Simulation Framework for Learning with Label Noise
Jul 23, 2021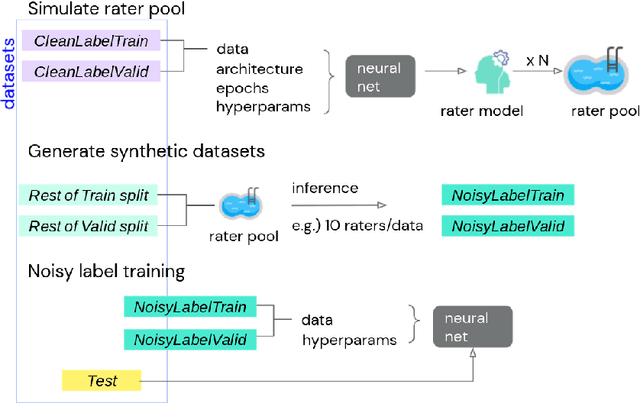
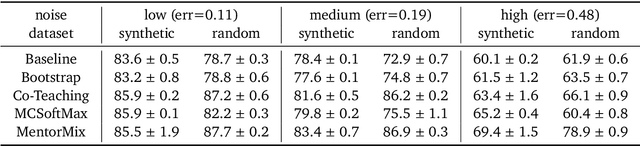
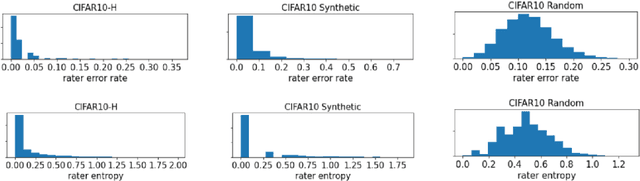
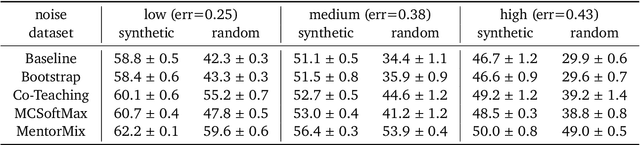
We propose a simulation framework for generating realistic instance-dependent noisy labels via a pseudo-labeling paradigm. We show that this framework generates synthetic noisy labels that exhibit important characteristics of the label noise in practical settings via comparison with the CIFAR10-H dataset. Equipped with controllable label noise, we study the negative impact of noisy labels across a few realistic settings to understand when label noise is more problematic. We also benchmark several existing algorithms for learning with noisy labels and compare their behavior on our synthetic datasets and on the datasets with independent random label noise. Additionally, with the availability of annotator information from our simulation framework, we propose a new technique, Label Quality Model (LQM), that leverages annotator features to predict and correct against noisy labels. We show that by adding LQM as a label correction step before applying existing noisy label techniques, we can further improve the models' performance.