 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022
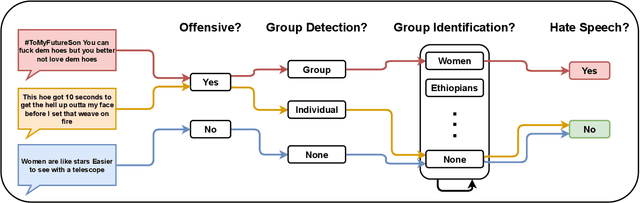

Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
A Review on Language Models as Knowledge Bases
Apr 12, 2022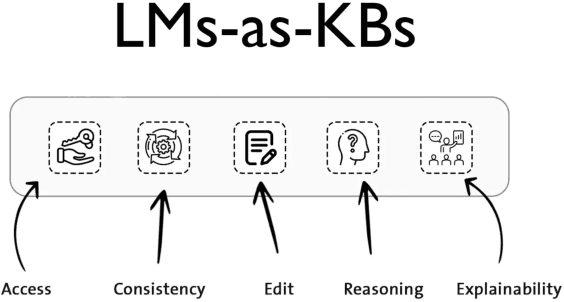
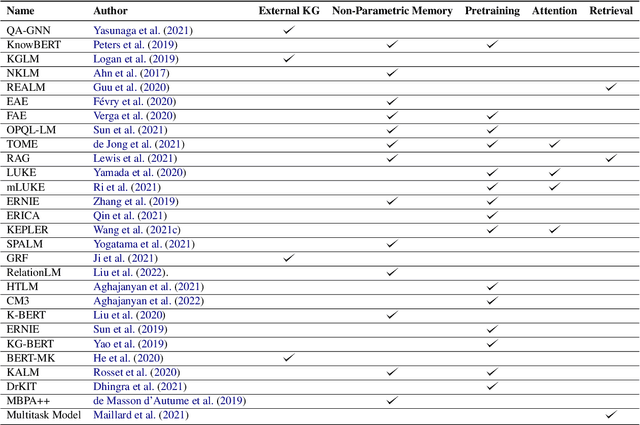
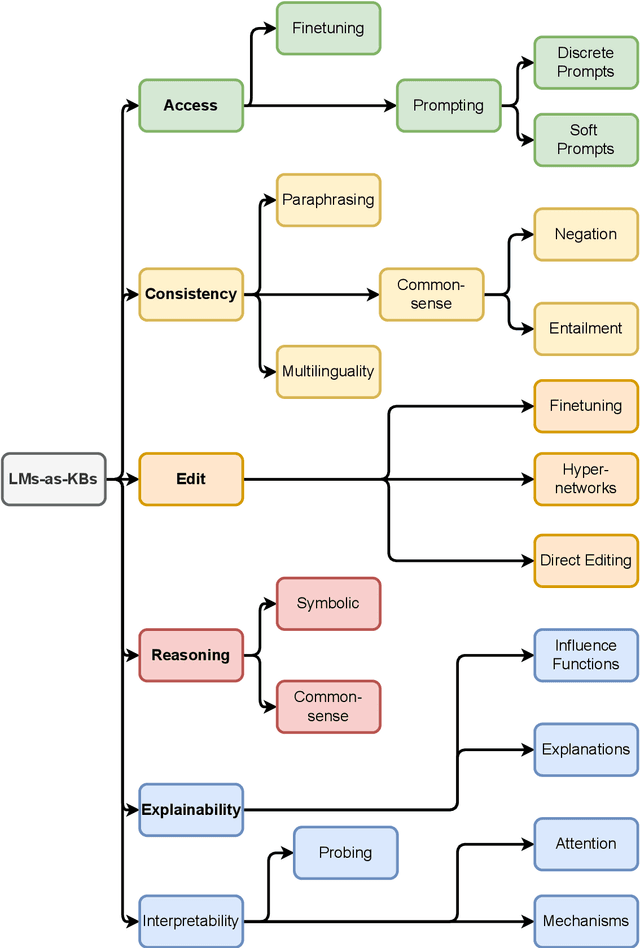
Recently, there has been a surge of interest in the NLP community on the use of pretrained Language Models (LMs) as Knowledge Bases (KBs). Researchers have shown that LMs trained on a sufficiently large (web) corpus will encode a significant amount of knowledge implicitly in its parameters. The resulting LM can be probed for different kinds of knowledge and thus acting as a KB. This has a major advantage over traditional KBs in that this method requires no human supervision. In this paper, we present a set of aspects that we deem a LM should have to fully act as a KB, and review the recent literature with respect to those aspects.
CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning
Dec 16, 2021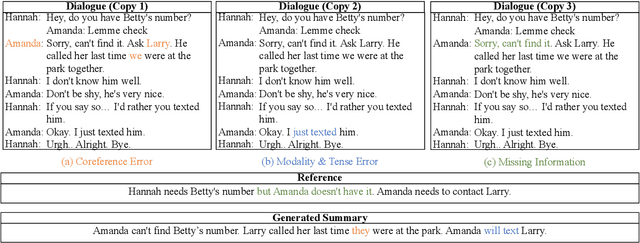
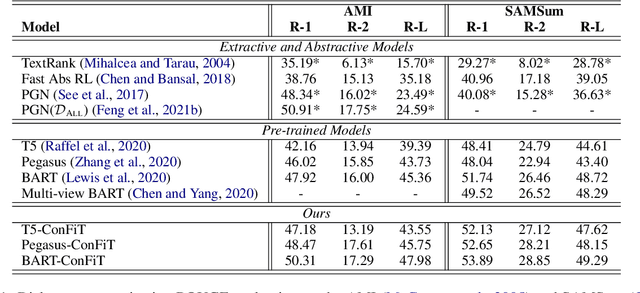
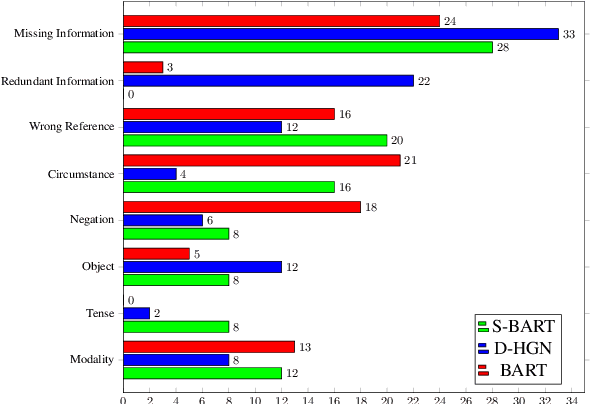
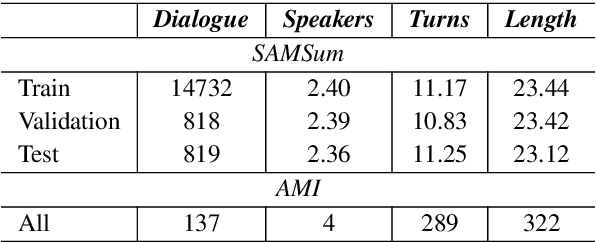
Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics.
CheckDST: Measuring Real-World Generalization of Dialogue State Tracking Performance
Dec 15, 2021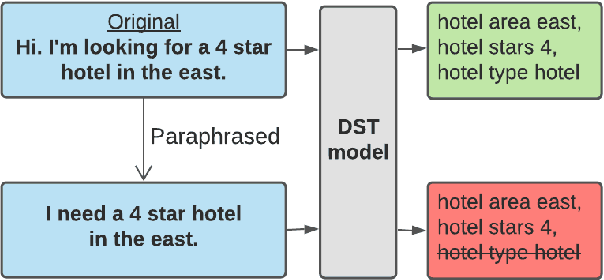
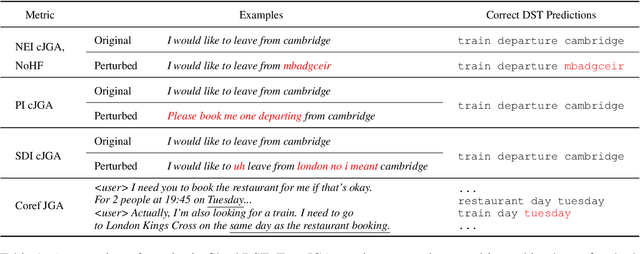
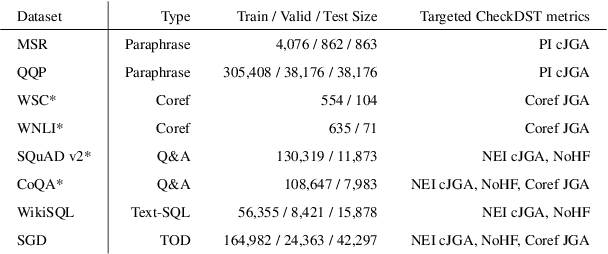
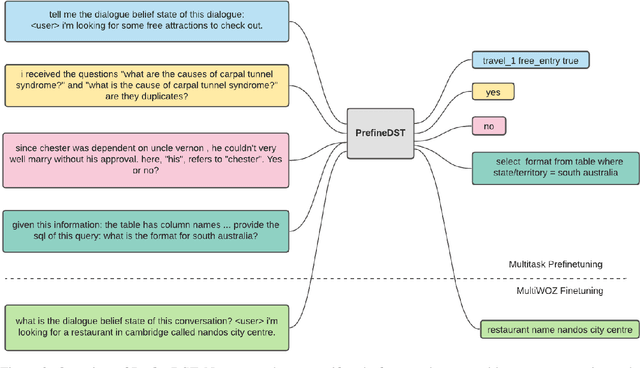
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.
Discourse-Aware Prompt Design for Text Generation
Dec 10, 2021
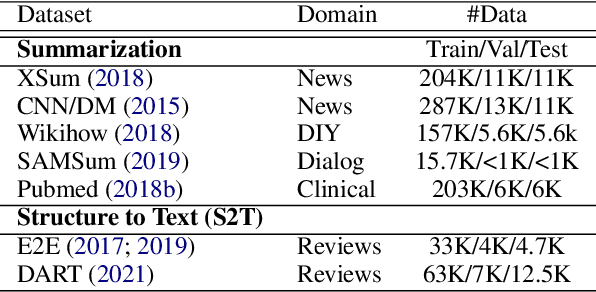
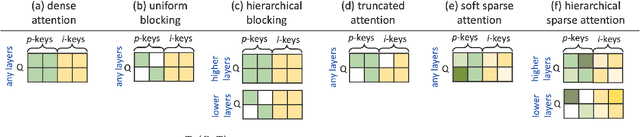

Current efficient fine-tuning methods (e.g., adapters, prefix-tuning, etc.) have optimized conditional text generation via training a small set of extra parameters of the neural language model, while freezing the rest for efficiency. While showing strong performance on some generation tasks, they don't generalize across all generation tasks. In this work, we show that prompt based conditional text generation can be improved with simple and efficient methods that simulate modeling the discourse structure of human written text. We introduce two key design choices: First we show that a higher-level discourse structure of human written text can be modelled with \textit{hierarchical blocking} on prefix parameters that enable spanning different parts of the input and output text and yield more coherent output generations. Second, we propose sparse prefix tuning by introducing \textit{attention sparsity} on the prefix parameters at different layers of the network and learn sparse transformations on the softmax-function, respectively. We find that sparse attention enables the prefix-tuning to better control of the input contents (salient facts) yielding more efficient tuning of the prefix-parameters. Experiments on a wide-variety of text generation tasks show that structured design of prefix parameters can achieve comparable results to fine-tuning all parameters while outperforming standard prefix-tuning on all generation tasks even in low-resource settings.
Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs
Nov 26, 2021

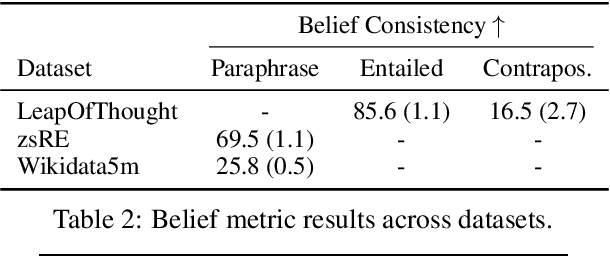
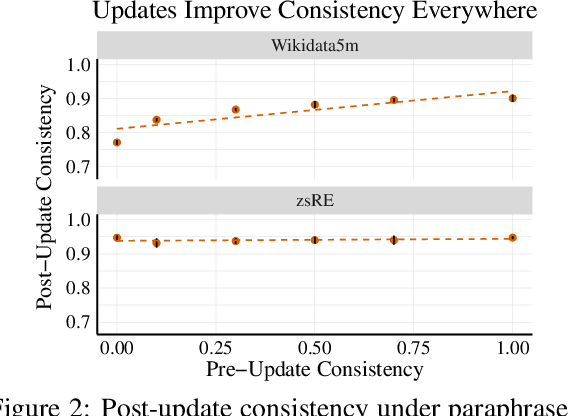
Do language models have beliefs about the world? Dennett (1995) famously argues that even thermostats have beliefs, on the view that a belief is simply an informational state decoupled from any motivational state. In this paper, we discuss approaches to detecting when models have beliefs about the world, and we improve on methods for updating model beliefs to be more truthful, with a focus on methods based on learned optimizers or hypernetworks. Our main contributions include: (1) new metrics for evaluating belief-updating methods that focus on the logical consistency of beliefs, (2) a training objective for Sequential, Local, and Generalizing model updates (SLAG) that improves the performance of learned optimizers, and (3) the introduction of the belief graph, which is a new form of interface with language models that shows the interdependencies between model beliefs. Our experiments suggest that models possess belief-like qualities to only a limited extent, but update methods can both fix incorrect model beliefs and greatly improve their consistency. Although off-the-shelf optimizers are surprisingly strong belief-updating baselines, our learned optimizers can outperform them in more difficult settings than have been considered in past work. Code is available at https://github.com/peterbhase/SLAG-Belief-Updating
How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN
Nov 18, 2021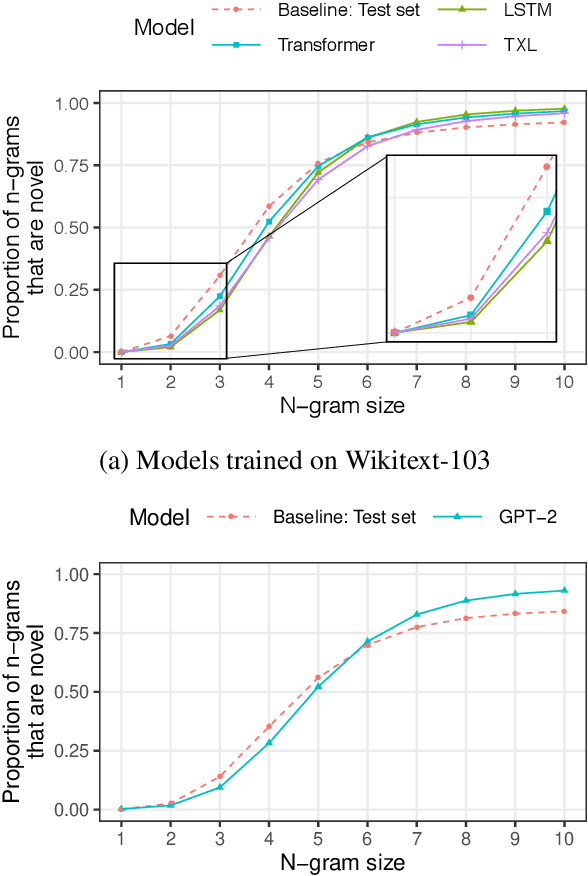
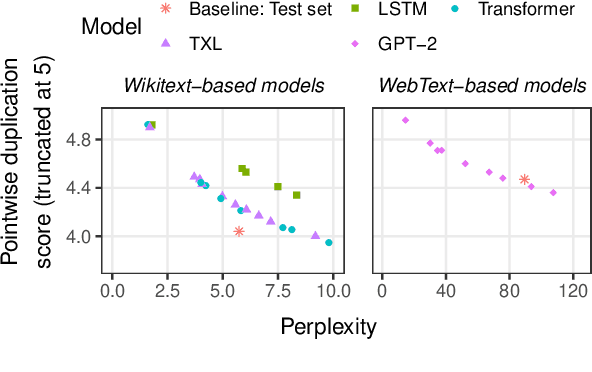
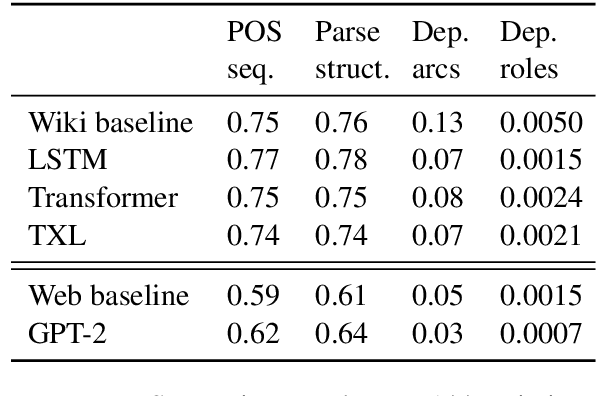
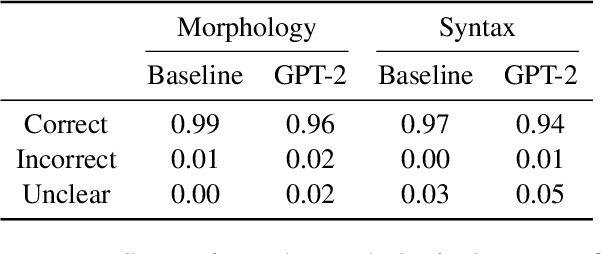
Current language models can generate high-quality text. Are they simply copying text they have seen before, or have they learned generalizable linguistic abstractions? To tease apart these possibilities, we introduce RAVEN, a suite of analyses for assessing the novelty of generated text, focusing on sequential structure (n-grams) and syntactic structure. We apply these analyses to four neural language models (an LSTM, a Transformer, Transformer-XL, and GPT-2). For local structure - e.g., individual dependencies - model-generated text is substantially less novel than our baseline of human-generated text from each model's test set. For larger-scale structure - e.g., overall sentence structure - model-generated text is as novel or even more novel than the human-generated baseline, but models still sometimes copy substantially, in some cases duplicating passages over 1,000 words long from the training set. We also perform extensive manual analysis showing that GPT-2's novel text is usually well-formed morphologically and syntactically but has reasonably frequent semantic issues (e.g., being self-contradictory).
An Exploratory Study on Long Dialogue Summarization: What Works and What's Next
Sep 10, 2021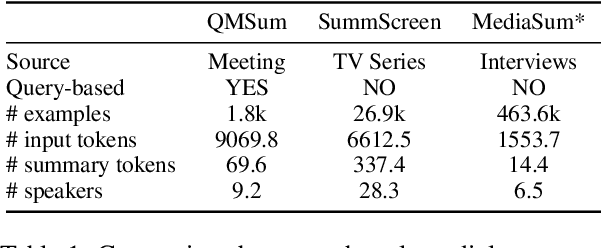
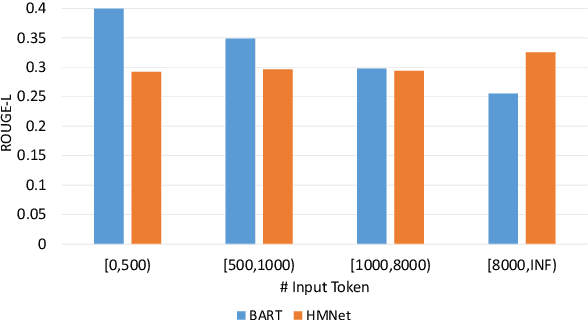
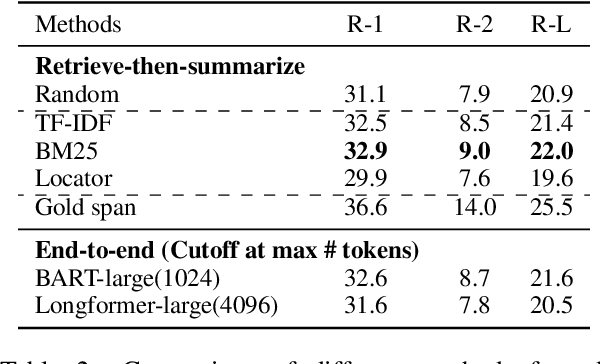
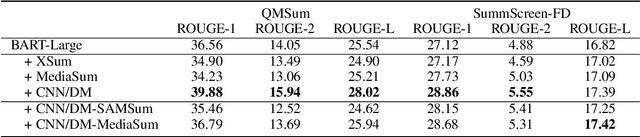
Dialogue summarization helps readers capture salient information from long conversations in meetings, interviews, and TV series. However, real-world dialogues pose a great challenge to current summarization models, as the dialogue length typically exceeds the input limits imposed by recent transformer-based pre-trained models, and the interactive nature of dialogues makes relevant information more context-dependent and sparsely distributed than news articles. In this work, we perform a comprehensive study on long dialogue summarization by investigating three strategies to deal with the lengthy input problem and locate relevant information: (1) extended transformer models such as Longformer, (2) retrieve-then-summarize pipeline models with several dialogue utterance retrieval methods, and (3) hierarchical dialogue encoding models such as HMNet. Our experimental results on three long dialogue datasets (QMSum, MediaSum, SummScreen) show that the retrieve-then-summarize pipeline models yield the best performance. We also demonstrate that the summary quality can be further improved with a stronger retrieval model and pretraining on proper external summarization datasets.
EmailSum: Abstractive Email Thread Summarization
Jul 30, 2021
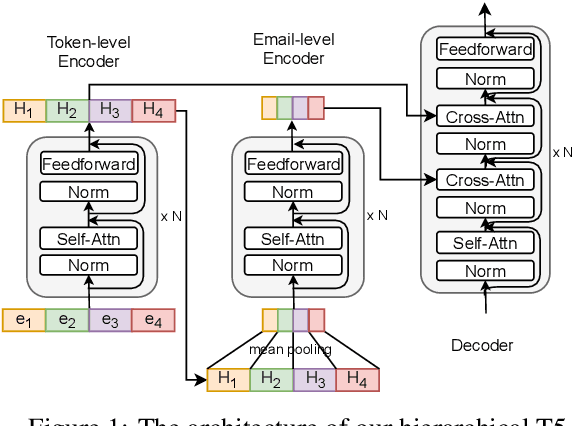
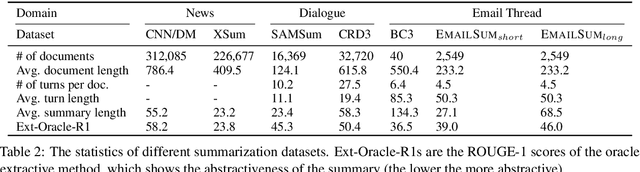
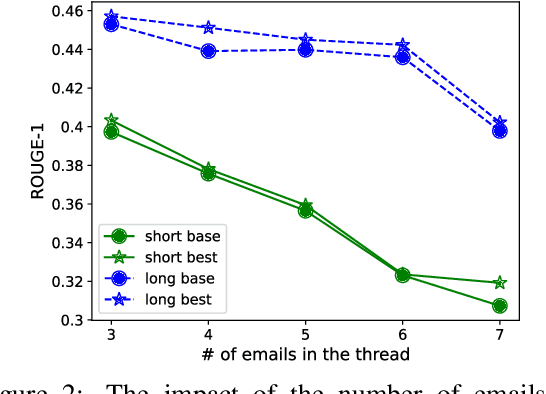
Recent years have brought about an interest in the challenging task of summarizing conversation threads (meetings, online discussions, etc.). Such summaries help analysis of the long text to quickly catch up with the decisions made and thus improve our work or communication efficiency. To spur research in thread summarization, we have developed an abstractive Email Thread Summarization (EmailSum) dataset, which contains human-annotated short (<30 words) and long (<100 words) summaries of 2549 email threads (each containing 3 to 10 emails) over a wide variety of topics. We perform a comprehensive empirical study to explore different summarization techniques (including extractive and abstractive methods, single-document and hierarchical models, as well as transfer and semisupervised learning) and conduct human evaluations on both short and long summary generation tasks. Our results reveal the key challenges of current abstractive summarization models in this task, such as understanding the sender's intent and identifying the roles of sender and receiver. Furthermore, we find that widely used automatic evaluation metrics (ROUGE, BERTScore) are weakly correlated with human judgments on this email thread summarization task. Hence, we emphasize the importance of human evaluation and the development of better metrics by the community. Our code and summary data have been made available at: https://github.com/ZhangShiyue/EmailSum
Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization
Jun 02, 2021
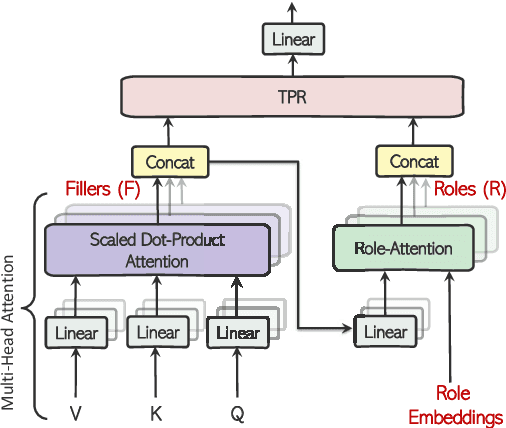
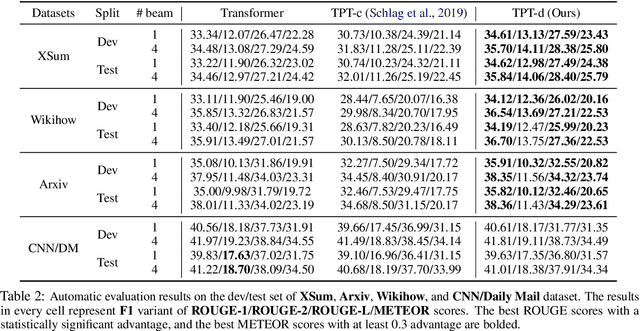
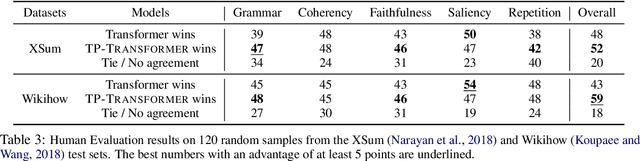
Abstractive summarization, the task of generating a concise summary of input documents, requires: (1) reasoning over the source document to determine the salient pieces of information scattered across the long document, and (2) composing a cohesive text by reconstructing these salient facts into a shorter summary that faithfully reflects the complex relations connecting these facts. In this paper, we adapt TP-TRANSFORMER (Schlag et al., 2019), an architecture that enriches the original Transformer (Vaswani et al., 2017) with the explicitly compositional Tensor Product Representation (TPR), for the task of abstractive summarization. The key feature of our model is a structural bias that we introduce by encoding two separate representations for each token to represent the syntactic structure (with role vectors) and semantic content (with filler vectors) separately. The model then binds the role and filler vectors into the TPR as the layer output. We argue that the structured intermediate representations enable the model to take better control of the contents (salient facts) and structures (the syntax that connects the facts) when generating the summary. Empirically, we show that our TP-TRANSFORMER outperforms the Transformer and the original TP-TRANSFORMER significantly on several abstractive summarization datasets based on both automatic and human evaluations. On several syntactic and semantic probing tasks, we demonstrate the emergent structural information in the role vectors and improved syntactic interpretability in the TPR layer outputs. Code and models are available at https://github.com/jiangycTarheel/TPT-Summ.