 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Language Models Learn and When? The Implicit Curriculum Hypothesis
Apr 09, 2026Large language models (LLMs) can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($ρ= .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R^2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
Do Natural Language Descriptions of Model Activations Convey Privileged Information?
Sep 16, 2025Recent interpretability methods have proposed to translate LLM internal representations into natural language descriptions using a second verbalizer LLM. This is intended to illuminate how the target model represents and operates on inputs. But do such activation verbalization approaches actually provide privileged knowledge about the internal workings of the target model, or do they merely convey information about its inputs? We critically evaluate popular verbalization methods across datasets used in prior work and find that they succeed at benchmarks without any access to target model internals, suggesting that these datasets are not ideal for evaluating verbalization methods. We then run controlled experiments which reveal that verbalizations often reflect the parametric knowledge of the verbalizer LLM which generated them, rather than the activations of the target LLM being decoded. Taken together, our results indicate a need for targeted benchmarks and experimental controls to rigorously assess whether verbalization methods provide meaningful insights into the operations of LLMs.
Multi-Field Adaptive Retrieval
Oct 26, 2024



Document retrieval for tasks such as search and retrieval-augmented generation typically involves datasets that are unstructured: free-form text without explicit internal structure in each document. However, documents can have a structured form, consisting of fields such as an article title, message body, or HTML header. To address this gap, we introduce Multi-Field Adaptive Retrieval (MFAR), a flexible framework that accommodates any number of and any type of document indices on structured data. Our framework consists of two main steps: (1) the decomposition of an existing document into fields, each indexed independently through dense and lexical methods, and (2) learning a model which adaptively predicts the importance of a field by conditioning on the document query, allowing on-the-fly weighting of the most likely field(s). We find that our approach allows for the optimized use of dense versus lexical representations across field types, significantly improves in document ranking over a number of existing retrievers, and achieves state-of-the-art performance for multi-field structured data.
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aug 02, 2024


Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
A Review on Language Models as Knowledge Bases
Apr 12, 2022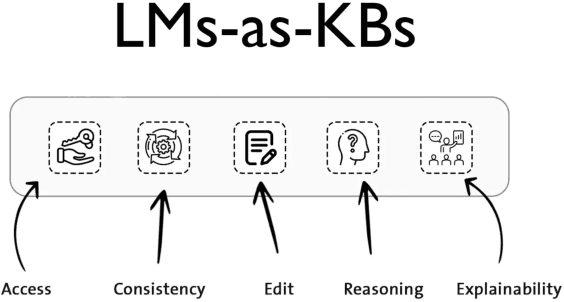
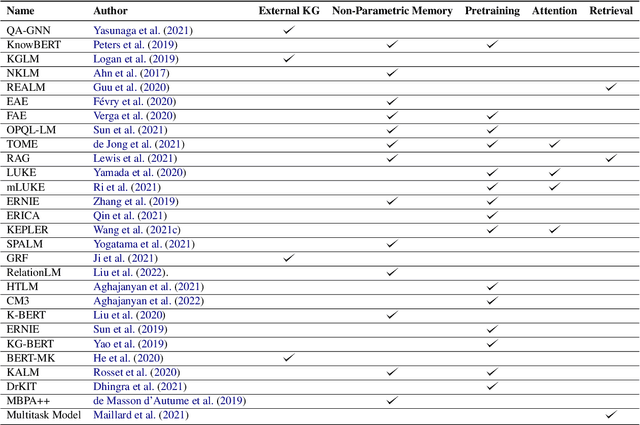
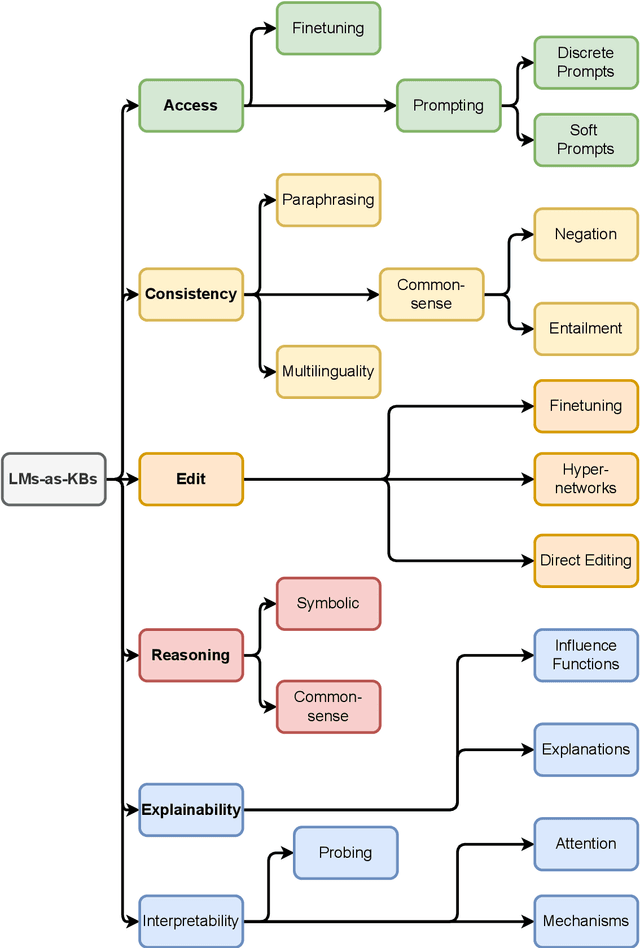
Recently, there has been a surge of interest in the NLP community on the use of pretrained Language Models (LMs) as Knowledge Bases (KBs). Researchers have shown that LMs trained on a sufficiently large (web) corpus will encode a significant amount of knowledge implicitly in its parameters. The resulting LM can be probed for different kinds of knowledge and thus acting as a KB. This has a major advantage over traditional KBs in that this method requires no human supervision. In this paper, we present a set of aspects that we deem a LM should have to fully act as a KB, and review the recent literature with respect to those aspects.