 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaSS: Parallel Speculative Sampling
Nov 22, 2023Scaling the size of language models to tens of billions of parameters has led to impressive performance on a wide range of tasks. At generation, these models are used auto-regressively, requiring a forward pass for each generated token, and thus reading the full set of parameters from memory. This memory access forms the primary bottleneck for generation and it worsens as the model size increases. Moreover, executing a forward pass for multiple tokens in parallel often takes nearly the same time as it does for just one token. These two observations lead to the development of speculative sampling, where a second smaller model is used to draft a few tokens, that are then validated or rejected using a single forward pass of the large model. Unfortunately, this method requires two models that share the same tokenizer and thus limits its adoption. As an alternative, we propose to use parallel decoding as a way to draft multiple tokens from a single model with no computational cost, nor the need for a second model. Our approach only requires an additional input token that marks the words that will be generated simultaneously. We show promising performance (up to $30\%$ speed-up) while requiring only as few as $O(d_{emb})$ additional parameters.
ImageBind: One Embedding Space To Bind Them All
May 09, 2023We present ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. We show that all combinations of paired data are not necessary to train such a joint embedding, and only image-paired data is sufficient to bind the modalities together. ImageBind can leverage recent large scale vision-language models, and extends their zero-shot capabilities to new modalities just by using their natural pairing with images. It enables novel emergent applications 'out-of-the-box' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation. The emergent capabilities improve with the strength of the image encoder and we set a new state-of-the-art on emergent zero-shot recognition tasks across modalities, outperforming specialist supervised models. Finally, we show strong few-shot recognition results outperforming prior work, and that ImageBind serves as a new way to evaluate vision models for visual and non-visual tasks.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023



The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mar 23, 2023



This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.
LLaMA: Open and Efficient Foundation Language Models
Feb 27, 2023



We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
Few-shot Learning with Retrieval Augmented Language Models
Aug 08, 2022
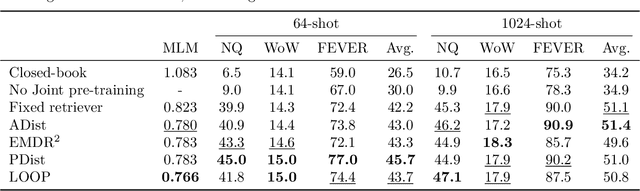


Large language models have shown impressive few-shot results on a wide range of tasks. However, when knowledge is key for such results, as is the case for tasks such as question answering and fact checking, massive parameter counts to store knowledge seem to be needed. Retrieval augmented models are known to excel at knowledge intensive tasks without the need for as many parameters, but it is unclear whether they work in few-shot settings. In this work we present Atlas, a carefully designed and pre-trained retrieval augmented language model able to learn knowledge intensive tasks with very few training examples. We perform evaluations on a wide range of tasks, including MMLU, KILT and NaturalQuestions, and study the impact of the content of the document index, showing that it can easily be updated. Notably, Atlas reaches over 42% accuracy on Natural Questions using only 64 examples, outperforming a 540B parameters model by 3% despite having 50x fewer parameters.
Improving Wikipedia Verifiability with AI
Jul 08, 2022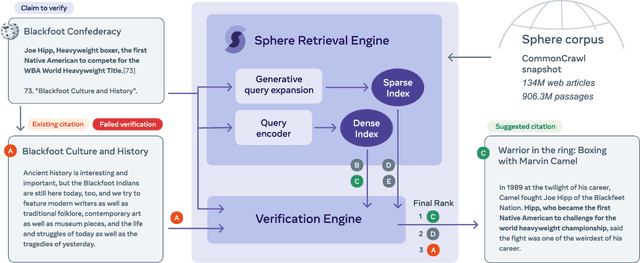

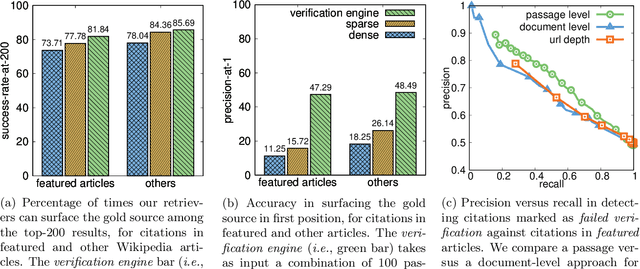
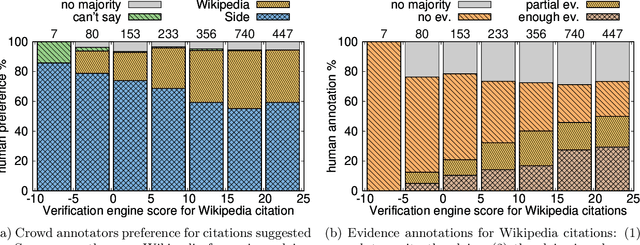
Verifiability is a core content policy of Wikipedia: claims that are likely to be challenged need to be backed by citations. There are millions of articles available online and thousands of new articles are released each month. For this reason, finding relevant sources is a difficult task: many claims do not have any references that support them. Furthermore, even existing citations might not support a given claim or become obsolete once the original source is updated or deleted. Hence, maintaining and improving the quality of Wikipedia references is an important challenge and there is a pressing need for better tools to assist humans in this effort. Here, we show that the process of improving references can be tackled with the help of artificial intelligence (AI). We develop a neural network based system, called Side, to identify Wikipedia citations that are unlikely to support their claims, and subsequently recommend better ones from the web. We train this model on existing Wikipedia references, therefore learning from the contributions and combined wisdom of thousands of Wikipedia editors. Using crowd-sourcing, we observe that for the top 10% most likely citations to be tagged as unverifiable by our system, humans prefer our system's suggested alternatives compared to the originally cited reference 70% of the time. To validate the applicability of our system, we built a demo to engage with the English-speaking Wikipedia community and find that Side's first citation recommendation collects over 60% more preferences than existing Wikipedia citations for the same top 10% most likely unverifiable claims according to Side. Our results indicate that an AI-based system could be used, in tandem with humans, to improve the verifiability of Wikipedia. More generally, we hope that our work can be used to assist fact checking efforts and increase the general trustworthiness of information online.
OmniMAE: Single Model Masked Pretraining on Images and Videos
Jun 16, 2022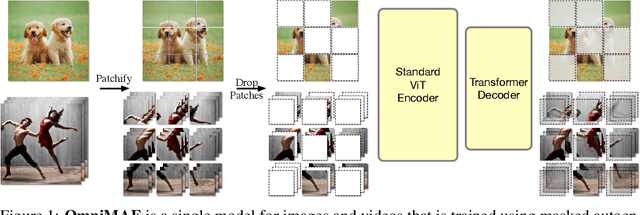

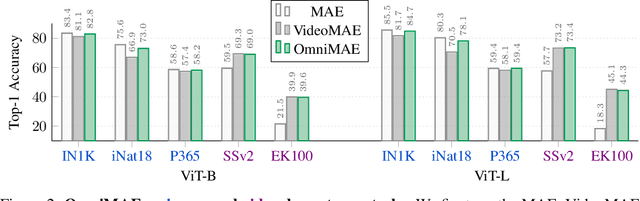
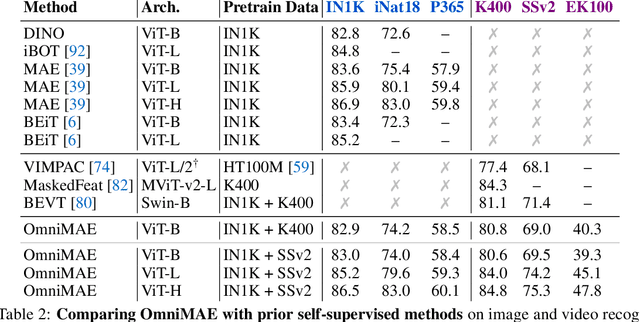
Transformer-based architectures have become competitive across a variety of visual domains, most notably images and videos. While prior work has studied these modalities in isolation, having a common architecture suggests that one can train a single unified model for multiple visual modalities. Prior attempts at unified modeling typically use architectures tailored for vision tasks, or obtain worse performance compared to single modality models. In this work, we show that masked autoencoding can be used to train a simple Vision Transformer on images and videos, without requiring any labeled data. This single model learns visual representations that are comparable to or better than single-modality representations on both image and video benchmarks, while using a much simpler architecture. In particular, our single pretrained model can be finetuned to achieve 86.5% on ImageNet and 75.3% on the challenging Something Something-v2 video benchmark. Furthermore, this model can be learned by dropping 90% of the image and 95% of the video patches, enabling extremely fast training.
Masked Siamese Networks for Label-Efficient Learning
Apr 14, 2022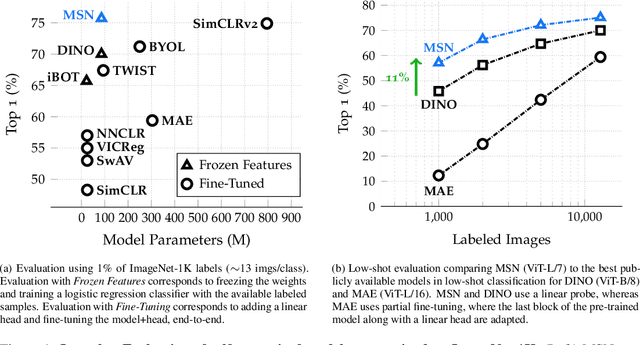
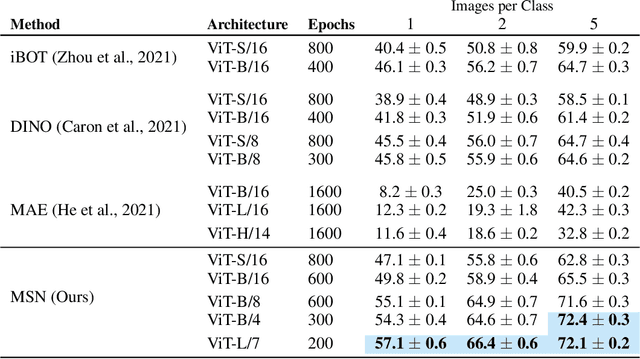

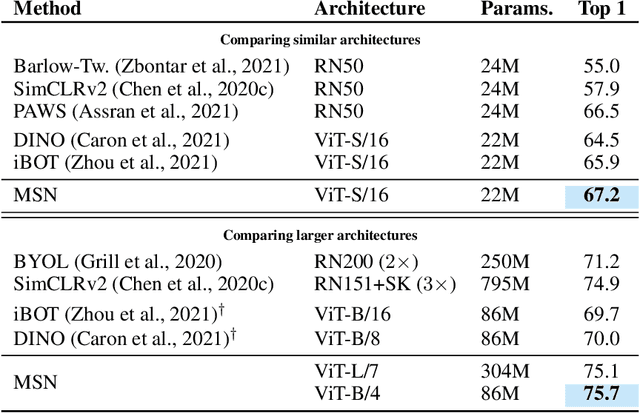
We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our approach matches the representation of an image view containing randomly masked patches to the representation of the original unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures, while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance, on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy, and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark. Our code is publicly available.
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022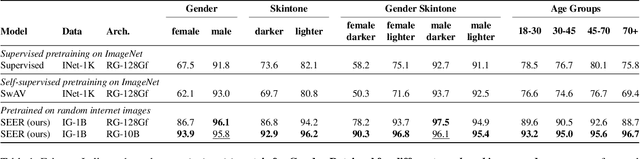
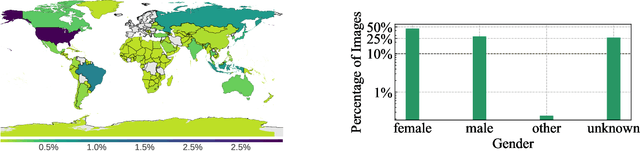
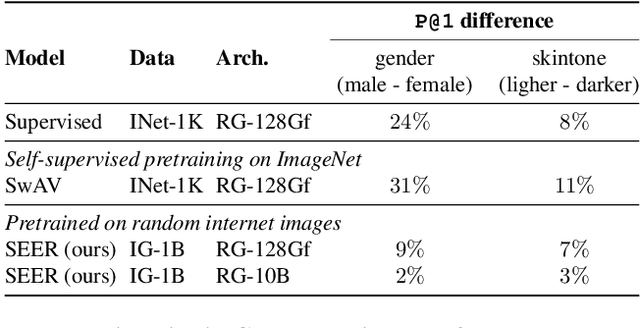
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.