 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtral of Experts
Jan 08, 2024



We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
Mistral 7B
Oct 10, 2023



We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
LLaMA: Open and Efficient Foundation Language Models
Feb 27, 2023



We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
HyperTree Proof Search for Neural Theorem Proving
May 23, 2022

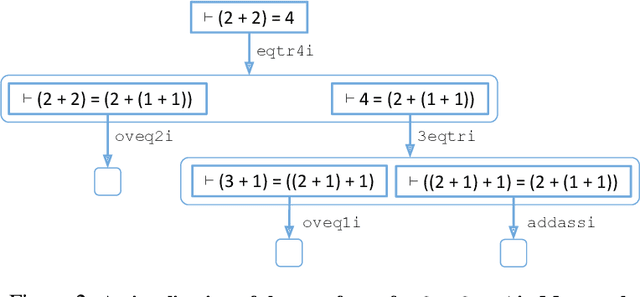
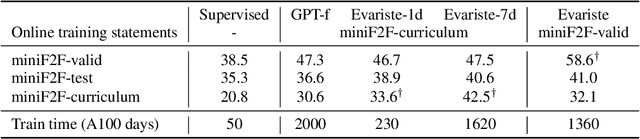
We propose an online training procedure for a transformer-based automated theorem prover. Our approach leverages a new search algorithm, HyperTree Proof Search (HTPS), inspired by the recent success of AlphaZero. Our model learns from previous proof searches through online training, allowing it to generalize to domains far from the training distribution. We report detailed ablations of our pipeline's main components by studying performance on three environments of increasing complexity. In particular, we show that with HTPS alone, a model trained on annotated proofs manages to prove 65.4% of a held-out set of Metamath theorems, significantly outperforming the previous state of the art of 56.5% by GPT-f. Online training on these unproved theorems increases accuracy to 82.6%. With a similar computational budget, we improve the state of the art on the Lean-based miniF2F-curriculum dataset from 31% to 42% proving accuracy.
DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
Feb 16, 2021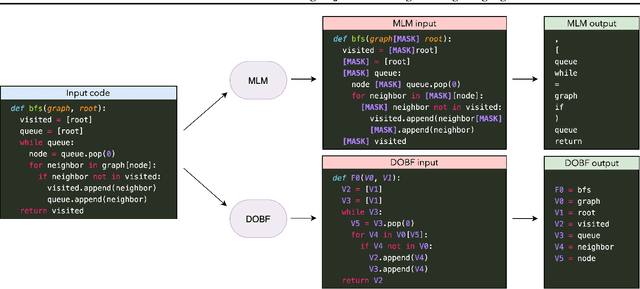


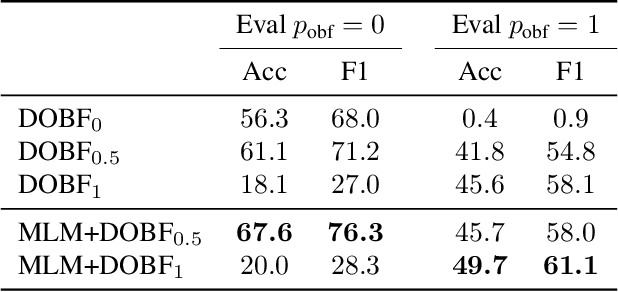
Recent advances in self-supervised learning have dramatically improved the state of the art on a wide variety of tasks. However, research in language model pre-training has mostly focused on natural languages, and it is unclear whether models like BERT and its variants provide the best pre-training when applied to other modalities, such as source code. In this paper, we introduce a new pre-training objective, DOBF, that leverages the structural aspect of programming languages and pre-trains a model to recover the original version of obfuscated source code. We show that models pre-trained with DOBF significantly outperform existing approaches on multiple downstream tasks, providing relative improvements of up to 13% in unsupervised code translation, and 24% in natural language code search. Incidentally, we found that our pre-trained model is able to de-obfuscate fully obfuscated source files, and to suggest descriptive variable names.
Target Conditioning for One-to-Many Generation
Sep 21, 2020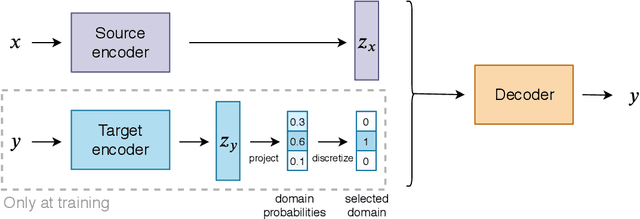
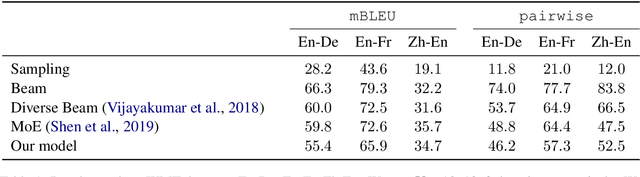
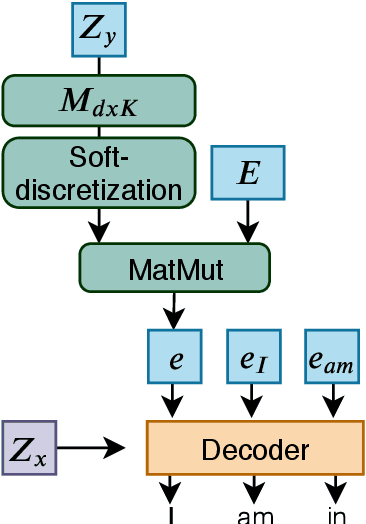
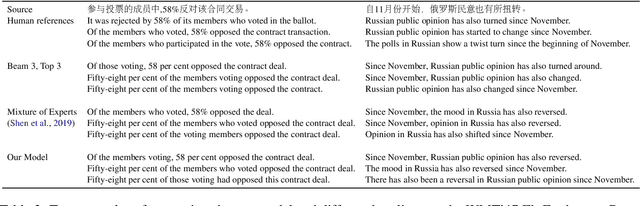
Neural Machine Translation (NMT) models often lack diversity in their generated translations, even when paired with search algorithm, like beam search. A challenge is that the diversity in translations are caused by the variability in the target language, and cannot be inferred from the source sentence alone. In this paper, we propose to explicitly model this one-to-many mapping by conditioning the decoder of a NMT model on a latent variable that represents the domain of target sentences. The domain is a discrete variable generated by a target encoder that is jointly trained with the NMT model. The predicted domain of target sentences are given as input to the decoder during training. At inference, we can generate diverse translations by decoding with different domains. Unlike our strongest baseline (Shen et al., 2019), our method can scale to any number of domains without affecting the performance or the training time. We assess the quality and diversity of translations generated by our model with several metrics, on three different datasets.
Unsupervised Translation of Programming Languages
Jun 05, 2020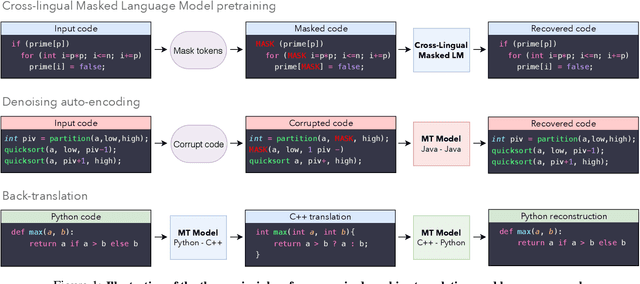



A transcompiler, also known as source-to-source translator, is a system that converts source code from a high-level programming language (such as C++ or Python) to another. Transcompilers are primarily used for interoperability, and to port codebases written in an obsolete or deprecated language (e.g. COBOL, Python 2) to a modern one. They typically rely on handcrafted rewrite rules, applied to the source code abstract syntax tree. Unfortunately, the resulting translations often lack readability, fail to respect the target language conventions, and require manual modifications in order to work properly. The overall translation process is timeconsuming and requires expertise in both the source and target languages, making code-translation projects expensive. Although neural models significantly outperform their rule-based counterparts in the context of natural language translation, their applications to transcompilation have been limited due to the scarcity of parallel data in this domain. In this paper, we propose to leverage recent approaches in unsupervised machine translation to train a fully unsupervised neural transcompiler. We train our model on source code from open source GitHub projects, and show that it can translate functions between C++, Java, and Python with high accuracy. Our method relies exclusively on monolingual source code, requires no expertise in the source or target languages, and can easily be generalized to other programming languages. We also build and release a test set composed of 852 parallel functions, along with unit tests to check the correctness of translations. We show that our model outperforms rule-based commercial baselines by a significant margin.
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Nov 15, 2019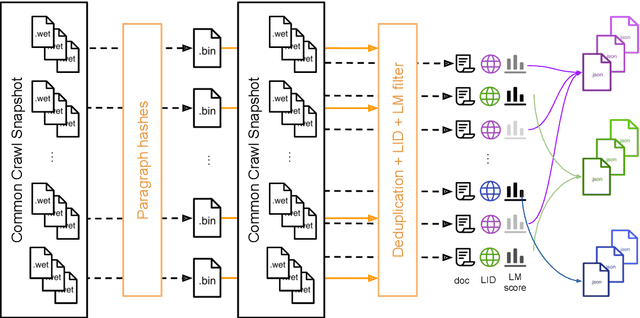
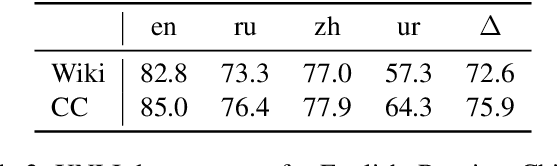
Pre-training text representations have led to significant improvements in many areas of natural language processing. The quality of these models benefits greatly from the size of the pretraining corpora as long as its quality is preserved. In this paper, we describe an automatic pipeline to extract massive high-quality monolingual datasets from Common Crawl for a variety of languages. Our pipeline follows the data processing introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that deduplicates documents and identifies their language. We augment this pipeline with a filtering step to select documents that are close to high quality corpora like Wikipedia.
Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers
Apr 22, 2019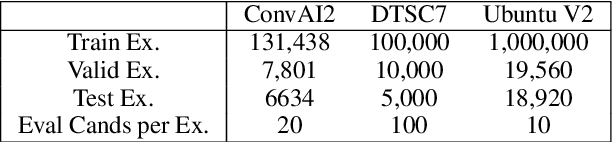
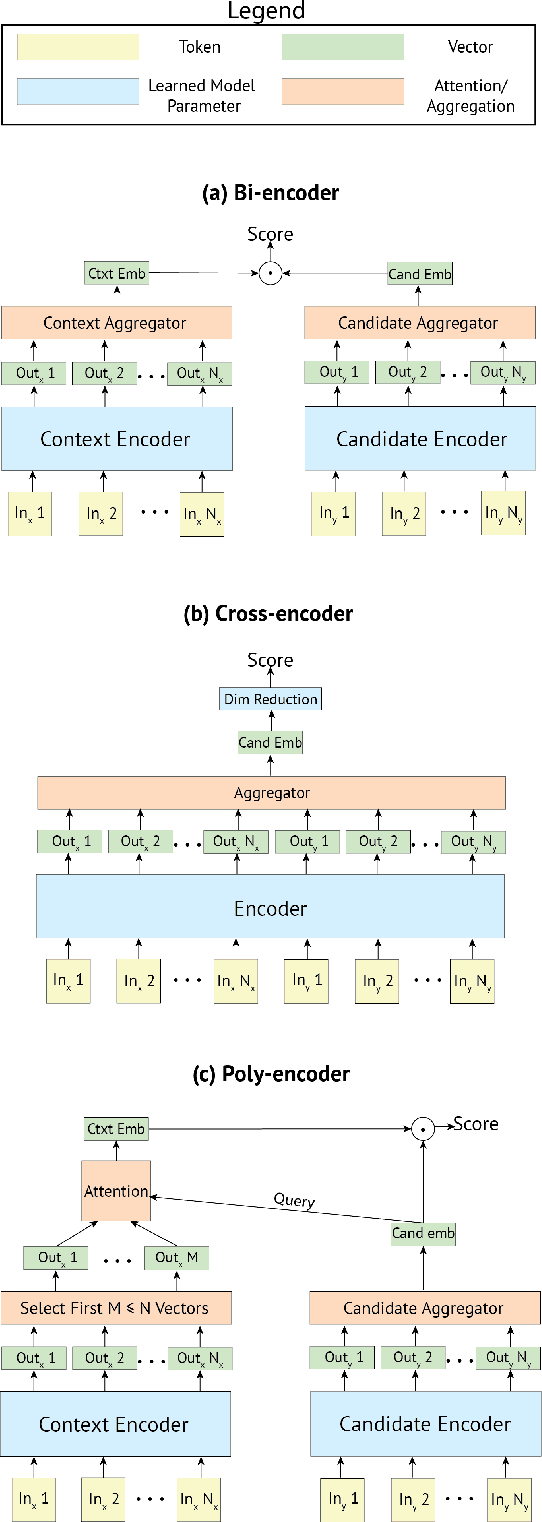

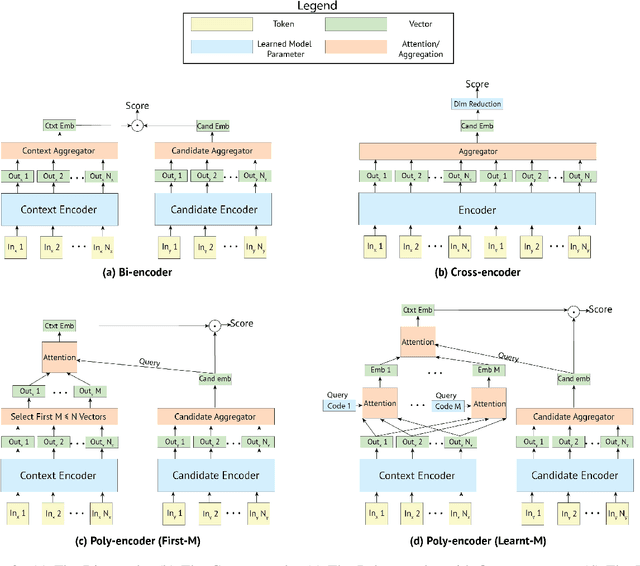
The use of deep pretrained bidirectional transformers has led to remarkable progress in learning multi-sentence representations for downstream language understanding tasks (Devlin et al., 2018). For tasks that make pairwise comparisons, e.g. matching a given context with a corresponding response, two approaches have permeated the literature. A Cross-encoder performs full self-attention over the pair; a Bi-encoder performs self-attention for each sequence separately, and the final representation is a function of the pair. While Cross-encoders nearly always outperform Bi-encoders on various tasks, both in our work and others' (Urbanek et al., 2019), they are orders of magnitude slower, which hampers their ability to perform real-time inference. In this work, we develop a new architecture, the Poly-encoder, that is designed to approach the performance of the Cross-encoder while maintaining reasonable computation time. Additionally, we explore two pretraining schemes with different datasets to determine how these affect the performance on our chosen dialogue tasks: ConvAI2 and DSTC7 Track 1. We show that our models achieve state-of-the-art results on both tasks; that the Poly-encoder is a suitable replacement for Bi-encoders and Cross-encoders; and that even better results can be obtained by pretraining on a large dialogue dataset.