 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Trained Language Models for Interactive Decision-Making
Feb 03, 2022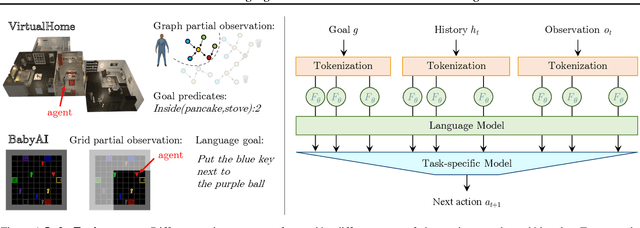
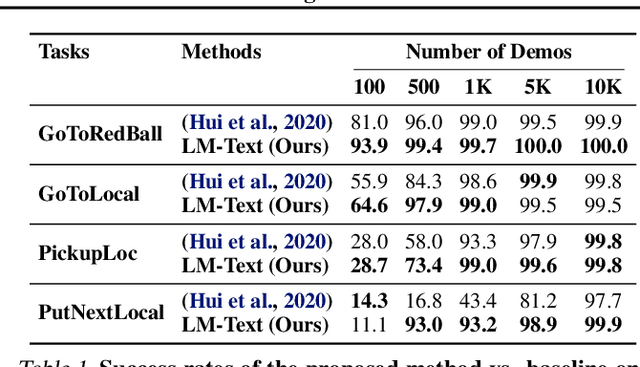
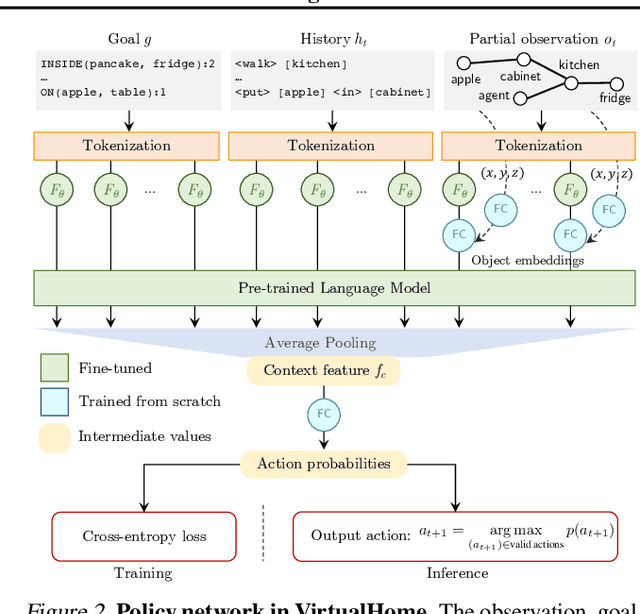
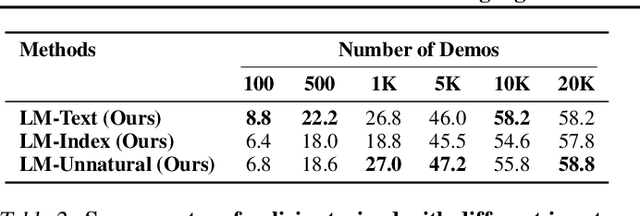
Language model (LM) pre-training has proven useful for a wide variety of language processing tasks, but can such pre-training be leveraged for more general machine learning problems? We investigate the effectiveness of language modeling to scaffold learning and generalization in autonomous decision-making. We describe a framework for imitation learning in which goals and observations are represented as a sequence of embeddings, and translated into actions using a policy network initialized with a pre-trained transformer LM. We demonstrate that this framework enables effective combinatorial generalization across different environments, such as VirtualHome and BabyAI. In particular, for test tasks involving novel goals or novel scenes, initializing policies with language models improves task completion rates by 43.6% in VirtualHome. We hypothesize and investigate three possible factors underlying the effectiveness of LM-based policy initialization. We find that sequential representations (vs. fixed-dimensional feature vectors) and the LM objective (not just the transformer architecture) are both important for generalization. Surprisingly, however, the format of the policy inputs encoding (e.g. as a natural language string vs. an arbitrary sequential encoding) has little influence. Together, these results suggest that language modeling induces representations that are useful for modeling not just language, but also goals and plans; these representations can aid learning and generalization even outside of language processing.
Natural Language Descriptions of Deep Visual Features
Jan 26, 2022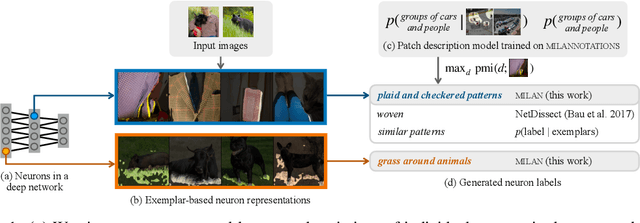
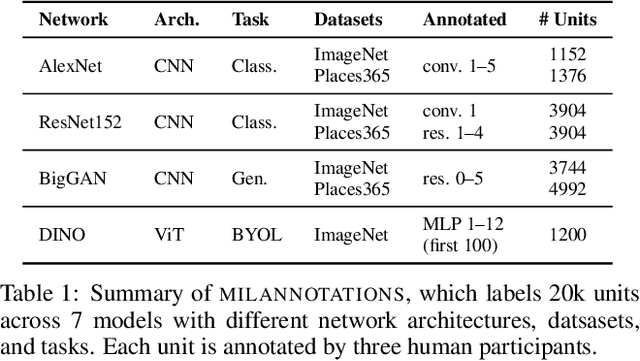
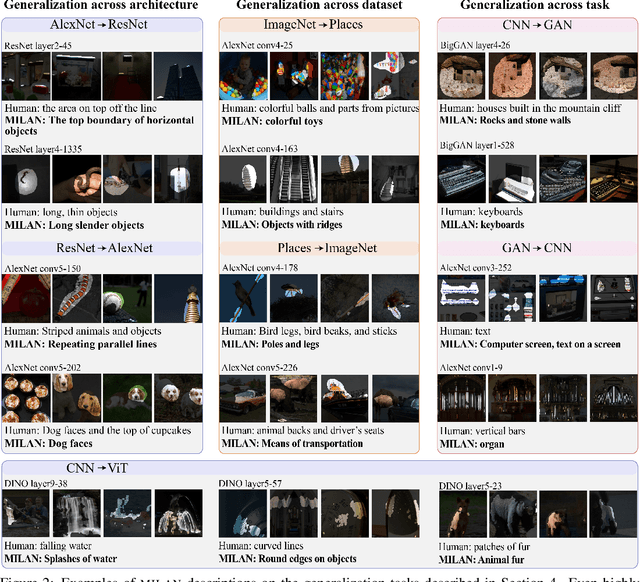
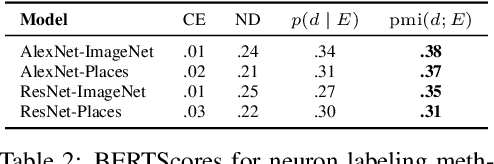
Some neurons in deep networks specialize in recognizing highly specific perceptual, structural, or semantic features of inputs. In computer vision, techniques exist for identifying neurons that respond to individual concept categories like colors, textures, and object classes. But these techniques are limited in scope, labeling only a small subset of neurons and behaviors in any network. Is a richer characterization of neuron-level computation possible? We introduce a procedure (called MILAN, for mutual-information-guided linguistic annotation of neurons) that automatically labels neurons with open-ended, compositional, natural language descriptions. Given a neuron, MILAN generates a description by searching for a natural language string that maximizes pointwise mutual information with the image regions in which the neuron is active. MILAN produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These descriptions obtain high agreement with human-generated feature descriptions across a diverse set of model architectures and tasks, and can aid in understanding and controlling learned models. We highlight three applications of natural language neuron descriptions. First, we use MILAN for analysis, characterizing the distribution and importance of neurons selective for attribute, category, and relational information in vision models. Second, we use MILAN for auditing, surfacing neurons sensitive to protected categories like race and gender in models trained on datasets intended to obscure these features. Finally, we use MILAN for editing, improving robustness in an image classifier by deleting neurons sensitive to text features spuriously correlated with class labels.
BigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations
Jan 12, 2022

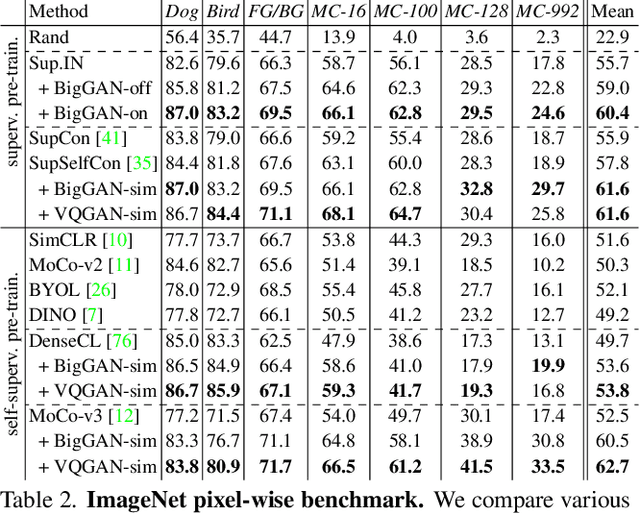
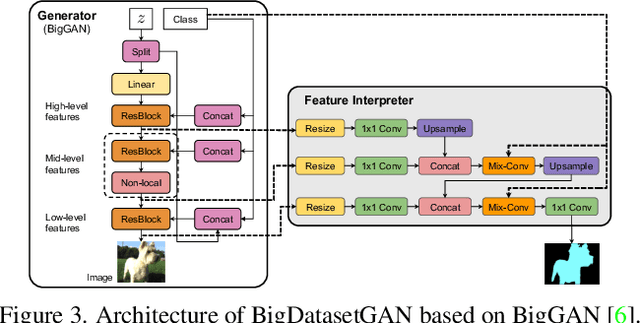
Annotating images with pixel-wise labels is a time-consuming and costly process. Recently, DatasetGAN showcased a promising alternative - to synthesize a large labeled dataset via a generative adversarial network (GAN) by exploiting a small set of manually labeled, GAN-generated images. Here, we scale DatasetGAN to ImageNet scale of class diversity. We take image samples from the class-conditional generative model BigGAN trained on ImageNet, and manually annotate 5 images per class, for all 1k classes. By training an effective feature segmentation architecture on top of BigGAN, we turn BigGAN into a labeled dataset generator. We further show that VQGAN can similarly serve as a dataset generator, leveraging the already annotated data. We create a new ImageNet benchmark by labeling an additional set of 8k real images and evaluate segmentation performance in a variety of settings. Through an extensive ablation study we show big gains in leveraging a large generated dataset to train different supervised and self-supervised backbone models on pixel-wise tasks. Furthermore, we demonstrate that using our synthesized datasets for pre-training leads to improvements over standard ImageNet pre-training on several downstream datasets, such as PASCAL-VOC, MS-COCO, Cityscapes and chest X-ray, as well as tasks (detection, segmentation). Our benchmark will be made public and maintain a leaderboard for this challenging task. Project Page: https://nv-tlabs.github.io/big-datasetgan/
Robust Contrastive Learning against Noisy Views
Jan 12, 2022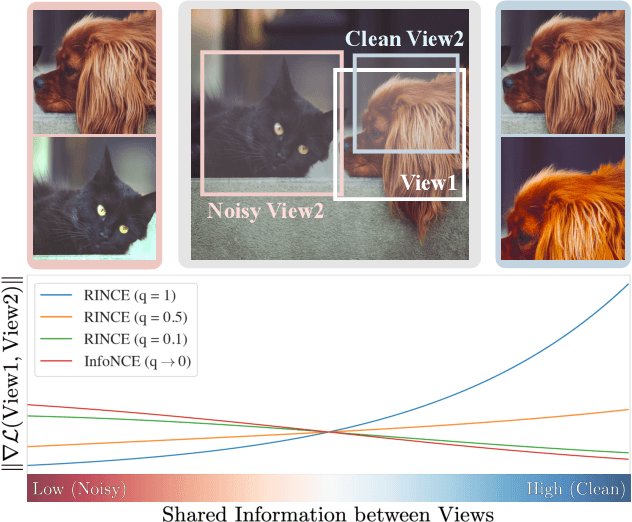
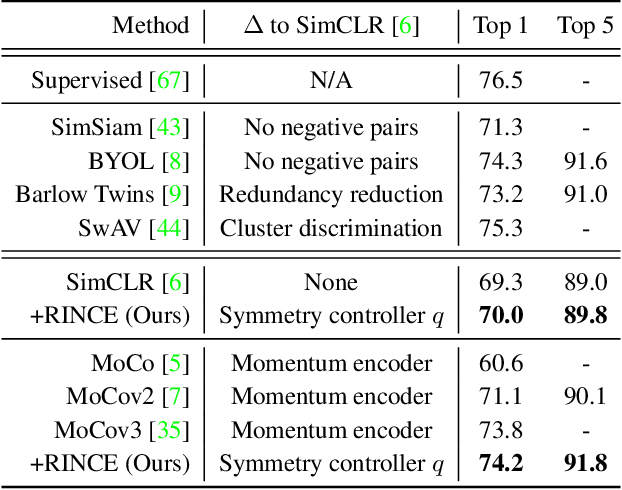

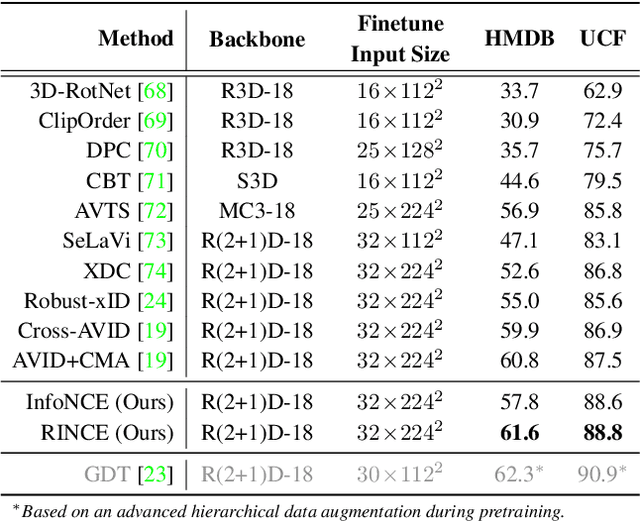
Contrastive learning relies on an assumption that positive pairs contain related views, e.g., patches of an image or co-occurring multimodal signals of a video, that share certain underlying information about an instance. But what if this assumption is violated? The literature suggests that contrastive learning produces suboptimal representations in the presence of noisy views, e.g., false positive pairs with no apparent shared information. In this work, we propose a new contrastive loss function that is robust against noisy views. We provide rigorous theoretical justifications by showing connections to robust symmetric losses for noisy binary classification and by establishing a new contrastive bound for mutual information maximization based on the Wasserstein distance measure. The proposed loss is completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss, which makes it easy to apply to existing contrastive frameworks. We show that our approach provides consistent improvements over the state-of-the-art on image, video, and graph contrastive learning benchmarks that exhibit a variety of real-world noise patterns.
Incidents1M: a large-scale dataset of images with natural disasters, damage, and incidents
Jan 11, 2022
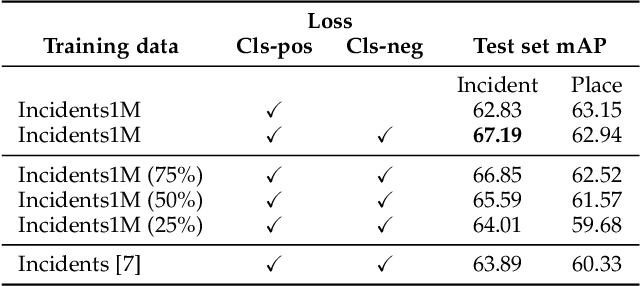
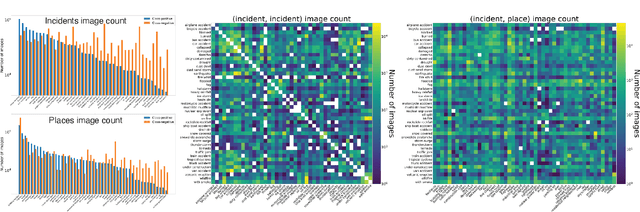
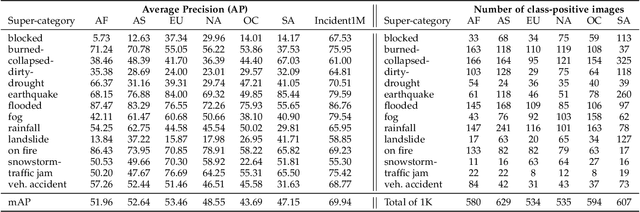
Natural disasters, such as floods, tornadoes, or wildfires, are increasingly pervasive as the Earth undergoes global warming. It is difficult to predict when and where an incident will occur, so timely emergency response is critical to saving the lives of those endangered by destructive events. Fortunately, technology can play a role in these situations. Social media posts can be used as a low-latency data source to understand the progression and aftermath of a disaster, yet parsing this data is tedious without automated methods. Prior work has mostly focused on text-based filtering, yet image and video-based filtering remains largely unexplored. In this work, we present the Incidents1M Dataset, a large-scale multi-label dataset which contains 977,088 images, with 43 incident and 49 place categories. We provide details of the dataset construction, statistics and potential biases; introduce and train a model for incident detection; and perform image-filtering experiments on millions of images on Flickr and Twitter. We also present some applications on incident analysis to encourage and enable future work in computer vision for humanitarian aid. Code, data, and models are available at http://incidentsdataset.csail.mit.edu.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021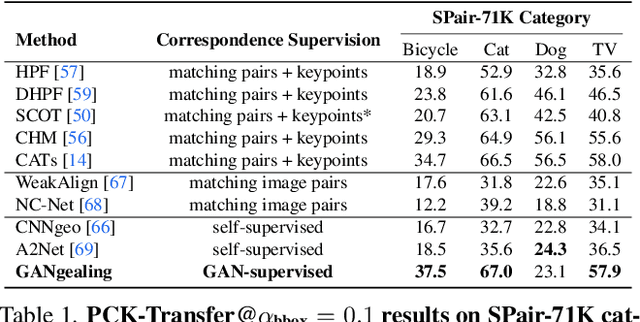
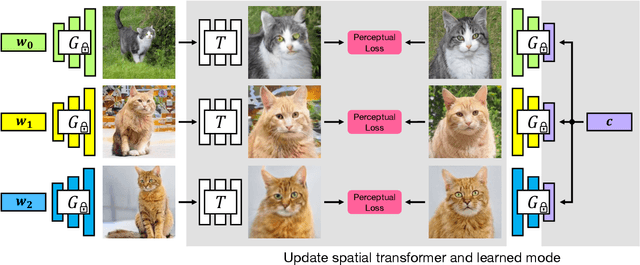


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.
PTR: A Benchmark for Part-based Conceptual, Relational, and Physical Reasoning
Dec 09, 2021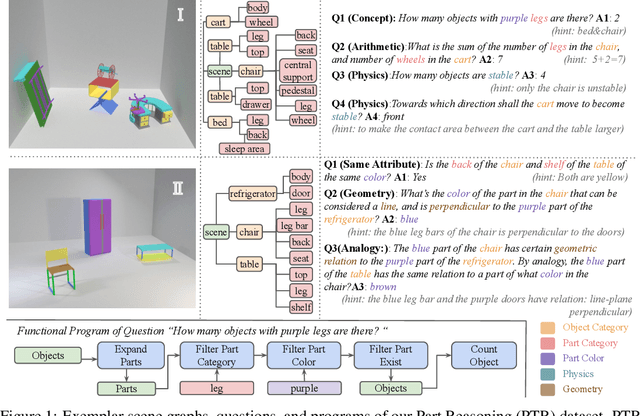
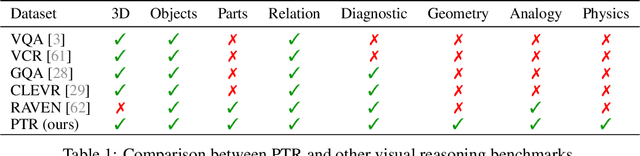
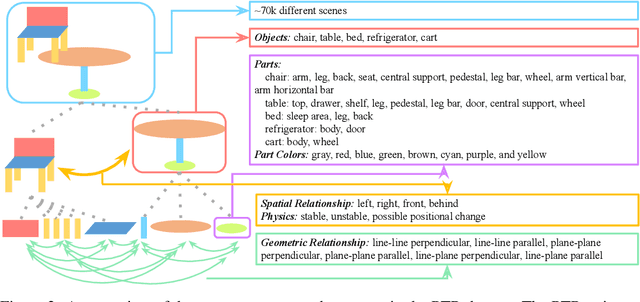
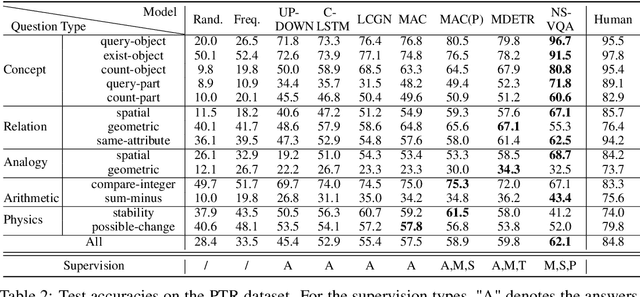
A critical aspect of human visual perception is the ability to parse visual scenes into individual objects and further into object parts, forming part-whole hierarchies. Such composite structures could induce a rich set of semantic concepts and relations, thus playing an important role in the interpretation and organization of visual signals as well as for the generalization of visual perception and reasoning. However, existing visual reasoning benchmarks mostly focus on objects rather than parts. Visual reasoning based on the full part-whole hierarchy is much more challenging than object-centric reasoning due to finer-grained concepts, richer geometry relations, and more complex physics. Therefore, to better serve for part-based conceptual, relational and physical reasoning, we introduce a new large-scale diagnostic visual reasoning dataset named PTR. PTR contains around 70k RGBD synthetic images with ground truth object and part level annotations regarding semantic instance segmentation, color attributes, spatial and geometric relationships, and certain physical properties such as stability. These images are paired with 700k machine-generated questions covering various types of reasoning types, making them a good testbed for visual reasoning models. We examine several state-of-the-art visual reasoning models on this dataset and observe that they still make many surprising mistakes in situations where humans can easily infer the correct answer. We believe this dataset will open up new opportunities for part-based reasoning.
Editing a classifier by rewriting its prediction rules
Dec 02, 2021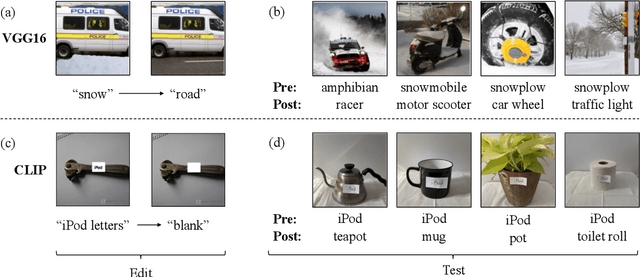

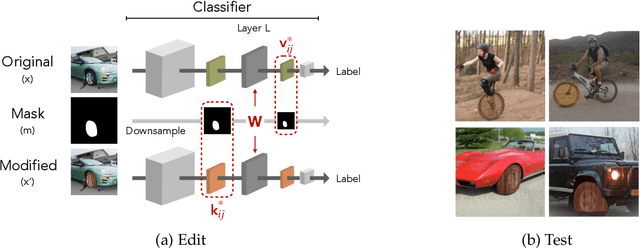
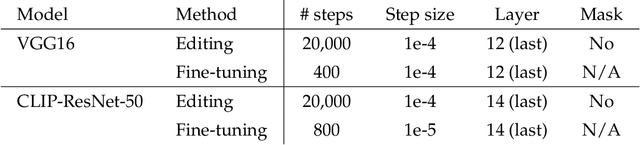
We present a methodology for modifying the behavior of a classifier by directly rewriting its prediction rules. Our approach requires virtually no additional data collection and can be applied to a variety of settings, including adapting a model to new environments, and modifying it to ignore spurious features. Our code is available at https://github.com/MadryLab/EditingClassifiers .
Learning to Compose Visual Relations
Nov 17, 2021
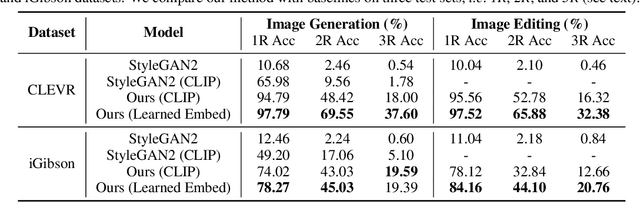
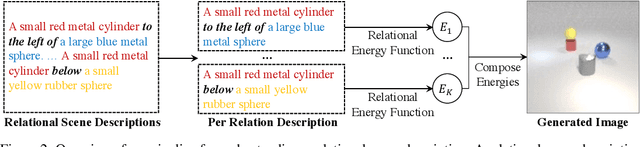
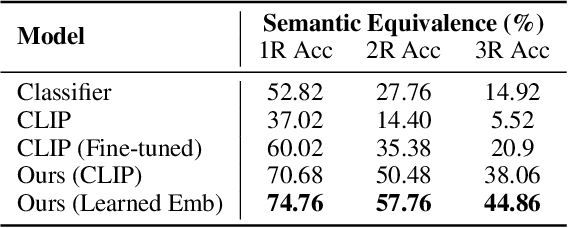
The visual world around us can be described as a structured set of objects and their associated relations. An image of a room may be conjured given only the description of the underlying objects and their associated relations. While there has been significant work on designing deep neural networks which may compose individual objects together, less work has been done on composing the individual relations between objects. A principal difficulty is that while the placement of objects is mutually independent, their relations are entangled and dependent on each other. To circumvent this issue, existing works primarily compose relations by utilizing a holistic encoder, in the form of text or graphs. In this work, we instead propose to represent each relation as an unnormalized density (an energy-based model), enabling us to compose separate relations in a factorized manner. We show that such a factorized decomposition allows the model to both generate and edit scenes that have multiple sets of relations more faithfully. We further show that decomposition enables our model to effectively understand the underlying relational scene structure. Project page at: https://composevisualrelations.github.io/.
EditGAN: High-Precision Semantic Image Editing
Nov 04, 2021
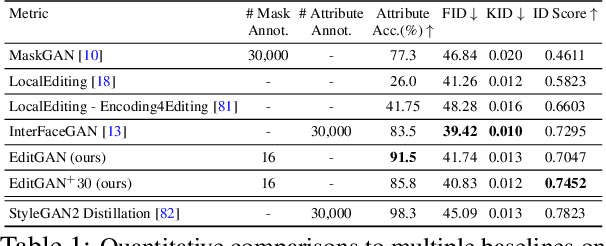
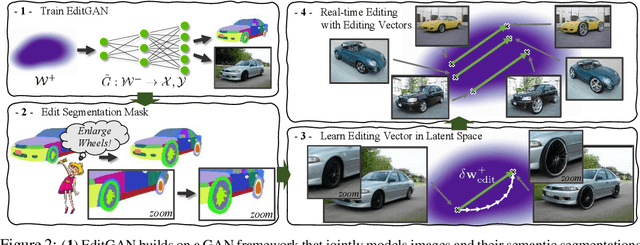
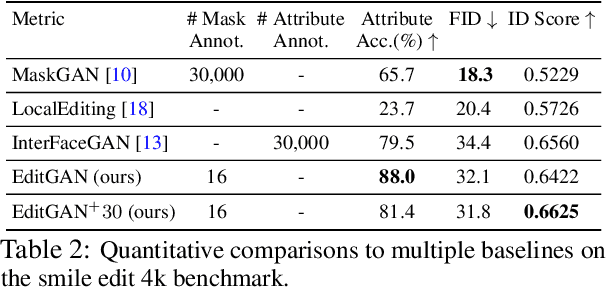
Generative adversarial networks (GANs) have recently found applications in image editing. However, most GAN based image editing methods often require large scale datasets with semantic segmentation annotations for training, only provide high level control, or merely interpolate between different images. Here, we propose EditGAN, a novel method for high quality, high precision semantic image editing, allowing users to edit images by modifying their highly detailed part segmentation masks, e.g., drawing a new mask for the headlight of a car. EditGAN builds on a GAN framework that jointly models images and their semantic segmentations, requiring only a handful of labeled examples, making it a scalable tool for editing. Specifically, we embed an image into the GAN latent space and perform conditional latent code optimization according to the segmentation edit, which effectively also modifies the image. To amortize optimization, we find editing vectors in latent space that realize the edits. The framework allows us to learn an arbitrary number of editing vectors, which can then be directly applied on other images at interactive rates. We experimentally show that EditGAN can manipulate images with an unprecedented level of detail and freedom, while preserving full image quality.We can also easily combine multiple edits and perform plausible edits beyond EditGAN training data. We demonstrate EditGAN on a wide variety of image types and quantitatively outperform several previous editing methods on standard editing benchmark tasks.