 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints-to-3D: Structure-Aware 3D Generation with Point Cloud Priors
Mar 19, 2026Recent progress in 3D generation has been driven largely by models conditioned on images or text, while readily available 3D priors are still underused. In many real-world scenarios, the visible-region point cloud are easy to obtain from active sensors such as LiDAR or from feed-forward predictors like VGGT, offering explicit geometric constraints that current methods fail to exploit. In this work, we introduce Points-to-3D, a diffusion-based framework that leverages point cloud priors for geometry-controllable 3D asset and scene generation. Built on a latent 3D diffusion model TRELLIS, Points-to-3D first replaces pure-noise sparse structure latent initialization with a point cloud priors tailored input formulation.A structure inpainting network, trained within the TRELLIS framework on task-specific data designed to learn global structural inpainting, is then used for inference with a staged sampling strategy (structural inpainting followed by boundary refinement), completing the global geometry while preserving the visible regions of the input priors.In practice, Points-to-3D can take either accurate point-cloud priors or VGGT-estimated point clouds from single images as input. Experiments on both objects and scene scenarios consistently demonstrate superior performance over state-of-the-art baselines in terms of rendering quality and geometric fidelity, highlighting the effectiveness of explicitly embedding point-cloud priors for achieving more accurate and structurally controllable 3D generation.
Chem4DLLM: 4D Multimodal LLMs for Chemical Dynamics Understanding
Mar 12, 2026Existing chemical understanding tasks primarily rely on static molecular representations, limiting their ability to model inherently dynamic phenomena such as bond breaking or conformational changes, which are essential for a chemist to understand chemical reactions. To address this gap, we introduce Chemical Dynamics Understanding (ChemDU), a new task that translates 4D molecular trajectories into interpretable natural-language explanations. ChemDU focuses on fundamental dynamic scenarios, including gas-phase and catalytic reactions, and requires models to reason about key events along molecular trajectories, such as bond formation and dissociation, and to generate coherent, mechanistically grounded narratives. To benchmark this capability, we construct Chem4DBench, the first dataset pairing 4D molecular trajectories with expert-authored explanations across these settings. We further propose Chem4DLLM, a unified model that integrates an equivariant graph encoder with a pretrained large language model to explicitly capture molecular geometry and rotational dynamics. We hope that ChemDU, together with Chem4DBench and Chem4DLLM, will stimulate further research in dynamic chemical understanding and multimodal scientific reasoning.
Overthinking Causes Hallucination: Tracing Confounder Propagation in Vision Language Models
Mar 08, 2026Vision Language models (VLMs) often hallucinate non-existent objects. Detecting hallucination is analogous to detecting deception: a single final statement is insufficient, one must examine the underlying reasoning process. Yet existing detectors rely mostly on final-layer signals. Attention-based methods assume hallucinated tokens exhibit low attention, while entropy-based ones use final-step uncertainty. Our analysis reveals the opposite: hallucinated objects can exhibit peaked attention due to contextual priors; and models often express high confidence because intermediate layers have already converged to an incorrect hypothesis. We show that the key to hallucination detection lies within the model's thought process, not its final output. By probing decoder layers, we uncover a previously overlooked behavior, overthinking: models repeatedly revise object hypotheses across layers before committing to an incorrect answer. Once the model latches onto a confounded hypothesis, it can propagate through subsequent layers, ultimately causing hallucination. To capture this behavior, we introduce the Overthinking Score, a metric to measure how many competing hypotheses the model entertains and how unstable these hypotheses are across layers. This score significantly improves hallucination detection: 78.9% F1 on MSCOCO and 71.58% on AMBER.
LangMap: A Hierarchical Benchmark for Open-Vocabulary Goal Navigation
Feb 02, 2026The relationships between objects and language are fundamental to meaningful communication between humans and AI, and to practically useful embodied intelligence. We introduce HieraNav, a multi-granularity, open-vocabulary goal navigation task where agents interpret natural language instructions to reach targets at four semantic levels: scene, room, region, and instance. To this end, we present Language as a Map (LangMap), a large-scale benchmark built on real-world 3D indoor scans with comprehensive human-verified annotations and tasks spanning these levels. LangMap provides region labels, discriminative region descriptions, discriminative instance descriptions covering 414 object categories, and over 18K navigation tasks. Each target features both concise and detailed descriptions, enabling evaluation across different instruction styles. LangMap achieves superior annotation quality, outperforming GOAT-Bench by 23.8% in discriminative accuracy using four times fewer words. Comprehensive evaluations of zero-shot and supervised models on LangMap reveal that richer context and memory improve success, while long-tailed, small, context-dependent, and distant goals, as well as multi-goal completion, remain challenging. HieraNav and LangMap establish a rigorous testbed for advancing language-driven embodied navigation. Project: https://bo-miao.github.io/LangMap
Concept Component Analysis: A Principled Approach for Concept Extraction in LLMs
Jan 29, 2026Developing human understandable interpretation of large language models (LLMs) becomes increasingly critical for their deployment in essential domains. Mechanistic interpretability seeks to mitigate the issues through extracts human-interpretable process and concepts from LLMs' activations. Sparse autoencoders (SAEs) have emerged as a popular approach for extracting interpretable and monosemantic concepts by decomposing the LLM internal representations into a dictionary. Despite their empirical progress, SAEs suffer from a fundamental theoretical ambiguity: the well-defined correspondence between LLM representations and human-interpretable concepts remains unclear. This lack of theoretical grounding gives rise to several methodological challenges, including difficulties in principled method design and evaluation criteria. In this work, we show that, under mild assumptions, LLM representations can be approximated as a {linear mixture} of the log-posteriors over concepts given the input context, through the lens of a latent variable model where concepts are treated as latent variables. This motivates a principled framework for concept extraction, namely Concept Component Analysis (ConCA), which aims to recover the log-posterior of each concept from LLM representations through a {unsupervised} linear unmixing process. We explore a specific variant, termed sparse ConCA, which leverages a sparsity prior to address the inherent ill-posedness of the unmixing problem. We implement 12 sparse ConCA variants and demonstrate their ability to extract meaningful concepts across multiple LLMs, offering theory-backed advantages over SAEs.
Procedural Pretraining: Warming Up Language Models with Abstract Data
Jan 29, 2026Pretraining directly on web-scale corpora is the de facto paradigm for building language models. We study an alternative setting where the model is initially exposed to abstract structured data, as a means to ease the subsequent acquisition of rich semantic knowledge, much like humans learn simple logic and mathematics before higher reasoning. We specifically focus on procedural data, generated by formal languages and other simple algorithms, as such abstract data. We first diagnose the algorithmic skills that different forms of procedural data can improve, often significantly. For example, on context recall (Needle-in-a-haystack), the accuracy jumps from 10 to 98% when pretraining on Dyck sequences (balanced brackets). Second, we study how these gains are reflected in pretraining larger models (up to 1.3B). We find that front-loading as little as 0.1% procedural data significantly outperforms standard pretraining on natural language, code, and informal mathematics (C4, CodeParrot, and DeepMind-Math datasets). Notably, this procedural pretraining enables the models to reach the same loss value with only 55, 67, 86% of the original data. Third, we explore the mechanisms behind and find that procedural pretraining instils non-trivial structure in both attention and MLP layers. The former is particularly important for structured domains (e.g. code), and the latter for language. Finally, we lay a path for combining multiple forms of procedural data. Our results show that procedural pretraining is a simple, lightweight means to improving performance and accelerating language model pretraining, ultimately suggesting the promise of disentangling knowledge acquisition from reasoning in LLMs.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025



Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
Can You Learn to See Without Images? Procedural Warm-Up for Vision Transformers
Nov 17, 2025



Transformers show remarkable versatility across domains, suggesting the existence of inductive biases beneficial across modalities. In this work, we explore a new way to instil such generic biases in vision transformers (ViTs) by pretraining on procedurally-generated data devoid of visual or semantic content. We generate this data with simple algorithms such as formal grammars, so the results bear no relationship to either natural or synthetic images. We use this procedurally-generated data to pretrain ViTs in a warm-up phase that bypasses their visual patch embedding mechanisms, thus encouraging the models to internalise abstract computational priors. When followed by standard image-based training, this warm-up significantly improves data efficiency, convergence speed, and downstream performance. On ImageNet-1k for example, allocating just 1% of the training budget to procedural data improves final accuracy by over 1.7%. In terms of its effect on performance, 1% procedurally generated data is thus equivalent to 28% of the ImageNet-1k data. These findings suggest a promising path toward new data-efficient and domain-agnostic pretraining strategies.
Towards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri--Rao Product
Aug 01, 2025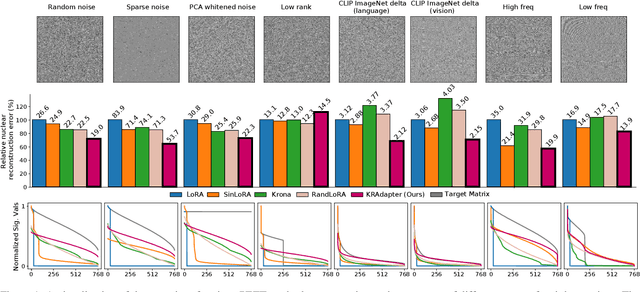
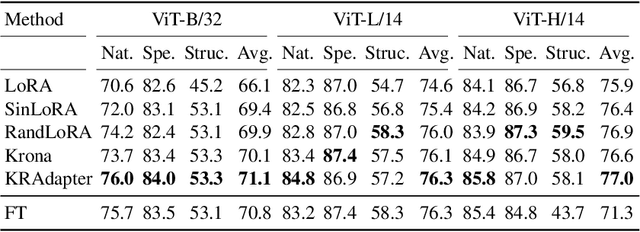
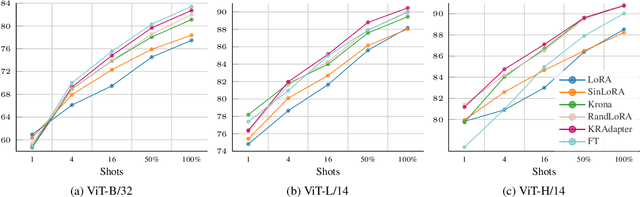
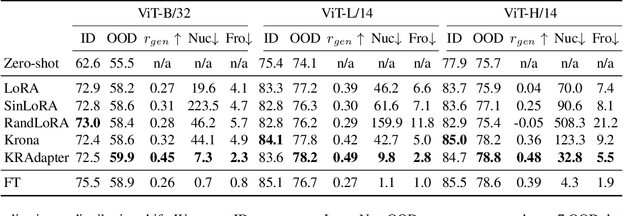
Parameter-efficient fine-tuning (PEFT) has become a standard approach for adapting large pre-trained models. Amongst PEFT methods, low-rank adaptation (LoRA) has achieved notable success. However, recent studies have highlighted its limitations compared against full-rank alternatives, particularly when applied to multimodal and large language models. In this work, we present a quantitative comparison amongst full-rank and low-rank PEFT methods using a synthetic matrix approximation benchmark with controlled spectral properties. Our results confirm that LoRA struggles to approximate matrices with relatively flat spectrums or high frequency components -- signs of high effective ranks. To this end, we introduce KRAdapter, a novel PEFT algorithm that leverages the Khatri-Rao product to produce weight updates, which, by construction, tends to produce matrix product with a high effective rank. We demonstrate performance gains with KRAdapter on vision-language models up to 1B parameters and on large language models up to 8B parameters, particularly on unseen common-sense reasoning tasks. In addition, KRAdapter maintains the memory and compute efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models.
Let Your Video Listen to Your Music!
Jun 23, 2025Aligning the rhythm of visual motion in a video with a given music track is a practical need in multimedia production, yet remains an underexplored task in autonomous video editing. Effective alignment between motion and musical beats enhances viewer engagement and visual appeal, particularly in music videos, promotional content, and cinematic editing. Existing methods typically depend on labor-intensive manual cutting, speed adjustments, or heuristic-based editing techniques to achieve synchronization. While some generative models handle joint video and music generation, they often entangle the two modalities, limiting flexibility in aligning video to music beats while preserving the full visual content. In this paper, we propose a novel and efficient framework, termed MVAA (Music-Video Auto-Alignment), that automatically edits video to align with the rhythm of a given music track while preserving the original visual content. To enhance flexibility, we modularize the task into a two-step process in our MVAA: aligning motion keyframes with audio beats, followed by rhythm-aware video inpainting. Specifically, we first insert keyframes at timestamps aligned with musical beats, then use a frame-conditioned diffusion model to generate coherent intermediate frames, preserving the original video's semantic content. Since comprehensive test-time training can be time-consuming, we adopt a two-stage strategy: pretraining the inpainting module on a small video set to learn general motion priors, followed by rapid inference-time fine-tuning for video-specific adaptation. This hybrid approach enables adaptation within 10 minutes with one epoch on a single NVIDIA 4090 GPU using CogVideoX-5b-I2V as the backbone. Extensive experiments show that our approach can achieve high-quality beat alignment and visual smoothness.