 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask the Target: A Plug-and-Play Regularizer Against LoRA Forgetting
May 28, 2026Low-Rank Adaptation (LoRA) has become one of the most widely used fine-tuning mechanisms for adapting large language models to new domains, tasks, and users. Yet adaptation performance alone can obscure an important failure mode: LoRA updates may improve performance on the target distribution while degrading prior capabilities learned during pretraining and alignment. We show that this forgetting becomes especially severe when the adaptation distribution differs substantially from the models original training or alignment distributions. The challenge is amplified in practical settings, where the original training and alignment data are typically unavailable. Motivated by this constraint, we study how LoRA based adaptation balances new learning against forgetting in a replay-free setting, and introduce a simple output space regularizer that can be added directly to existing training pipelines. Our method removes the ground-truth token from both the base and adapted model distributions, renormalizes the remaining probabilities, and applies KL regularization only over the non-target vocabulary. This preserves the base models relative preferences among alternative tokens without directly opposing the cross-entropy signal required for adaptation. As the regularizer acts only at the loss level, it requires no replay data, architectural changes, adapter redesign, or inference-time overhead, and can be applied directly to existing LoRA variants. Across all LoRA variants tested and across various backbones, our method improves the frontier between new learning and forgetting when the adaptation distribution differs substantially from the base models original training or alignment distributions, suggesting a broadly applicable route toward more reliable LLM updating.
The Quantization Benefits of Residual-Free Transformers
May 25, 2026Large-scale transformer training and deployment are increasingly constrained by the transfer of activations, gradients, and optimizer states across accelerators. Low-bit quantization offers a natural remedy, but transformer activations are often heavy-tailed and outlier-dominated, making simple quantization highly lossy. We show that this difficulty is not only a property of the quantizer, but also of the architecture. Specifically, residual connections can drive transformer activations away from Gaussianity during training. Using controlled comparisons between residual and residual-free transformers, we demonstrate that this effect leads to substantially higher quantization error and accuracy degradation at low precision in residual models. We explain the phenomenon through an excess kurtosis analysis, showing that residual mixing can amplify non-Gaussianity, whereas dense mixing in residual-free contracts non-Gaussianity. We then show that residual-free transformers can be made trainable using orthogonal initialization, spectral or second-order optimization, and depth-aware scaling of attention temperature. In language tasks, while there is a small drop in full precision performance, these models retain near-Gaussian activations and exhibit significantly improved robustness to low-bit quantization. Our results identify an accuracy--compressibility trade-off in transformer design and motivate architecture-level approaches to quantization-friendly foundation models.
Preconditioned Attention: Enhancing Efficiency in Transformers
Mar 28, 2026Central to the success of Transformers is the attention block, which effectively models global dependencies among input tokens associated to a dataset. However, we theoretically demonstrate that standard attention mechanisms in transformers often produce ill-conditioned matrices with large condition numbers. This ill-conditioning is a well-known obstacle for gradient-based optimizers, leading to inefficient training. To address this issue, we introduce preconditioned attention, a novel approach that incorporates a conditioning matrix into each attention head. Our theoretical analysis shows that this method significantly reduces the condition number of attention matrices, resulting in better-conditioned matrices that improve optimization. Conditioned attention serves as a simple drop-in replacement for a wide variety of attention mechanisms in the literature. We validate the effectiveness of preconditioned attention across a diverse set of transformer applications, including image classification, object detection, instance segmentation, long sequence modeling and language modeling.
The Inlet Rank Collapse in Implicit Neural Representations: Diagnosis and Unified Remedy
Feb 02, 2026Implicit Neural Representations (INRs) have revolutionized continuous signal modeling, yet they struggle to recover fine-grained details within finite training budgets. While empirical techniques, such as positional encoding (PE), sinusoidal activations (SIREN), and batch normalization (BN), effectively mitigate this, their theoretical justifications are predominantly post hoc, focusing on the global NTK spectrum only after modifications are applied. In this work, we reverse this paradigm by introducing a structural diagnostic framework. By performing a layer-wise decomposition of the NTK, we mathematically identify the ``Inlet Rank Collapse'': a phenomenon where the low-dimensional input coordinates fail to span the high-dimensional embedding space, creating a fundamental rank deficiency at the first layer that acts as an expressive bottleneck for the entire network. This framework provides a unified perspective to re-interpret PE, SIREN, and BN as different forms of rank restoration. Guided by this diagnosis, we derive a Rank-Expanding Initialization, a minimalist remedy that ensures the representation rank scales with the layer width without architectural modifications or computational overhead. Our results demonstrate that this principled remedy enables standard MLPs to achieve high-fidelity reconstructions, proving that the key to empowering INRs lies in the structural optimization of the initial rank propagation to effectively populate the latent space.
Procedural Pretraining: Warming Up Language Models with Abstract Data
Jan 29, 2026Pretraining directly on web-scale corpora is the de facto paradigm for building language models. We study an alternative setting where the model is initially exposed to abstract structured data, as a means to ease the subsequent acquisition of rich semantic knowledge, much like humans learn simple logic and mathematics before higher reasoning. We specifically focus on procedural data, generated by formal languages and other simple algorithms, as such abstract data. We first diagnose the algorithmic skills that different forms of procedural data can improve, often significantly. For example, on context recall (Needle-in-a-haystack), the accuracy jumps from 10 to 98% when pretraining on Dyck sequences (balanced brackets). Second, we study how these gains are reflected in pretraining larger models (up to 1.3B). We find that front-loading as little as 0.1% procedural data significantly outperforms standard pretraining on natural language, code, and informal mathematics (C4, CodeParrot, and DeepMind-Math datasets). Notably, this procedural pretraining enables the models to reach the same loss value with only 55, 67, 86% of the original data. Third, we explore the mechanisms behind and find that procedural pretraining instils non-trivial structure in both attention and MLP layers. The former is particularly important for structured domains (e.g. code), and the latter for language. Finally, we lay a path for combining multiple forms of procedural data. Our results show that procedural pretraining is a simple, lightweight means to improving performance and accelerating language model pretraining, ultimately suggesting the promise of disentangling knowledge acquisition from reasoning in LLMs.
Can You Learn to See Without Images? Procedural Warm-Up for Vision Transformers
Nov 17, 2025



Transformers show remarkable versatility across domains, suggesting the existence of inductive biases beneficial across modalities. In this work, we explore a new way to instil such generic biases in vision transformers (ViTs) by pretraining on procedurally-generated data devoid of visual or semantic content. We generate this data with simple algorithms such as formal grammars, so the results bear no relationship to either natural or synthetic images. We use this procedurally-generated data to pretrain ViTs in a warm-up phase that bypasses their visual patch embedding mechanisms, thus encouraging the models to internalise abstract computational priors. When followed by standard image-based training, this warm-up significantly improves data efficiency, convergence speed, and downstream performance. On ImageNet-1k for example, allocating just 1% of the training budget to procedural data improves final accuracy by over 1.7%. In terms of its effect on performance, 1% procedurally generated data is thus equivalent to 28% of the ImageNet-1k data. These findings suggest a promising path toward new data-efficient and domain-agnostic pretraining strategies.
Data Denoising and Derivative Estimation for Data-Driven Modeling of Nonlinear Dynamical Systems
Sep 17, 2025Data-driven modeling of nonlinear dynamical systems is often hampered by measurement noise. We propose a denoising framework, called Runge-Kutta and Total Variation Based Implicit Neural Representation (RKTV-INR), that represents the state trajectory with an implicit neural representation (INR) fitted directly to noisy observations. Runge-Kutta integration and total variation are imposed as constraints to ensure that the reconstructed state is a trajectory of a dynamical system that remains close to the original data. The trained INR yields a clean, continuous trajectory and provides accurate first-order derivatives via automatic differentiation. These denoised states and derivatives are then supplied to Sparse Identification of Nonlinear Dynamics (SINDy) to recover the governing equations. Experiments demonstrate effective noise suppression, precise derivative estimation, and reliable system identification.
Towards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri--Rao Product
Aug 01, 2025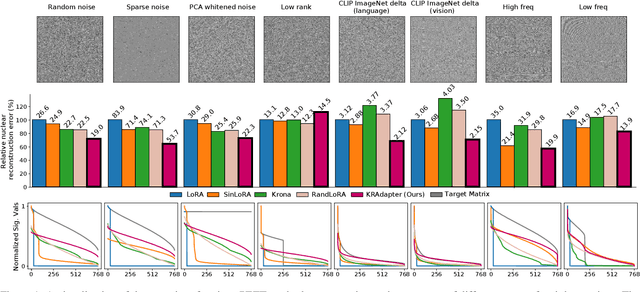
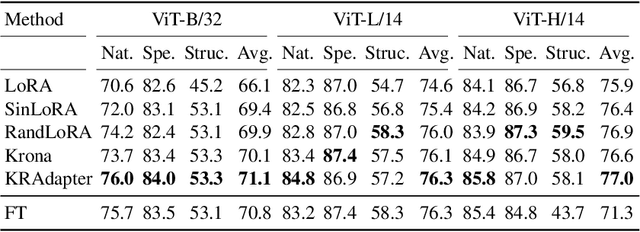
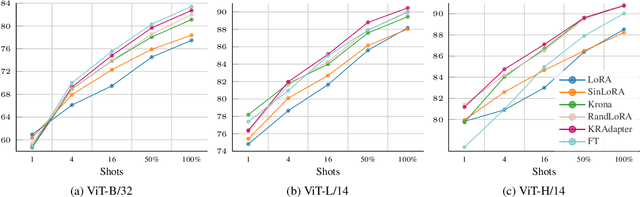
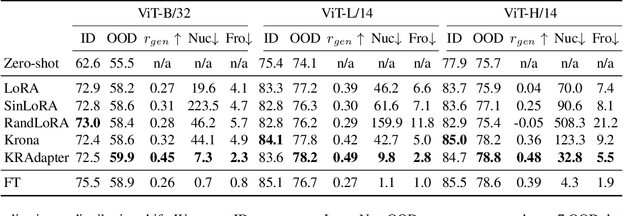
Parameter-efficient fine-tuning (PEFT) has become a standard approach for adapting large pre-trained models. Amongst PEFT methods, low-rank adaptation (LoRA) has achieved notable success. However, recent studies have highlighted its limitations compared against full-rank alternatives, particularly when applied to multimodal and large language models. In this work, we present a quantitative comparison amongst full-rank and low-rank PEFT methods using a synthetic matrix approximation benchmark with controlled spectral properties. Our results confirm that LoRA struggles to approximate matrices with relatively flat spectrums or high frequency components -- signs of high effective ranks. To this end, we introduce KRAdapter, a novel PEFT algorithm that leverages the Khatri-Rao product to produce weight updates, which, by construction, tends to produce matrix product with a high effective rank. We demonstrate performance gains with KRAdapter on vision-language models up to 1B parameters and on large language models up to 8B parameters, particularly on unseen common-sense reasoning tasks. In addition, KRAdapter maintains the memory and compute efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models.
Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning
May 28, 2025Pretraining on large, semantically rich datasets is key for developing language models. Surprisingly, recent studies have shown that even synthetic data, generated procedurally through simple semantic-free algorithms, can yield some of the same benefits as natural language pretraining. It is unclear what specific capabilities such simple synthetic data instils in a model, where these capabilities reside in the architecture, and how they manifest within its weights. In this short paper, we identify several beneficial forms of procedural data, together with specific algorithmic reasoning skills that improve in small transformers. Our core finding is that different procedural rules instil distinct but complementary inductive structures in the model. With extensive ablations and partial-transfer experiments, we discover that these structures reside in different parts of the model. Attention layers often carry the most transferable information, but some pretraining rules impart useful structure to MLP blocks instead. Most interestingly, the structures induced by multiple rules can be composed to jointly reinforce multiple capabilities. These results suggest an exciting possibility of disentangling the acquisition of knowledge from reasoning in language models, with the goal of improving their robustness and data efficiency.
Compressing Sine-Activated Low-Rank Adapters through Post-Training Quantization
May 28, 2025



Low-Rank Adaptation (LoRA) has become a standard approach for parameter-efficient fine-tuning, offering substantial reductions in trainable parameters by modeling updates as the product of two low-rank matrices. While effective, the low-rank constraint inherently limits representational capacity, often resulting in reduced performance compared to full-rank fine-tuning. Recent work by Ji et al. (2025) has addressed this limitation by applying a fixed-frequency sinusoidal transformation to low-rank adapters, increasing their stable rank without introducing additional parameters. This raises a crucial question: can the same sine-activated technique be successfully applied within the context of Post-Training Quantization to retain benefits even after model compression? In this paper, we investigate this question by extending the sinusoidal transformation framework to quantized LoRA adapters. We develop a theoretical analysis showing that the stable rank of a quantized adapter is tightly linked to that of its full-precision counterpart, motivating the use of such rank-enhancing functions even under quantization. Our results demonstrate that the expressivity gains from a sinusoidal non-linearity persist after quantization, yielding highly compressed adapters with negligible loss in performance. We validate our approach across a range of fine-tuning tasks for language, vision and text-to-image generation achieving significant memory savings while maintaining competitive accuracy.