 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Towards Task-Consistent Open-Vocabulary Adaptation in Video Recognition
Jun 24, 2026Adapting CLIP for open-vocabulary video recognition necessitates a delicate balance between newly acquired video knowledge and the pretrained generalization. While existing studies pursue this generalization-specialization trade-off with additional regularizations or constraints, we argue that they overlook the deviation of representations beyond the fine-tuning data distribution, resulting in suboptimal adaptation effects. We believe such deviation is inherited from the inconsistency between the fine-tuning and evaluation objectives, where model optimization is restricted to the known training distribution but evaluated on unseen ones. In this paper, we introduce \emph{TACO}, a simple yet effective framework to mitigate the potential negative effects induced by this inconsistency. Our key insight is that adaptation should preserve OOD-relevant alignment beyond the training distribution. To this end, we propose \emph{Relative Structure Distillation}, which regularizes the relative geometry of the representation space and suppresses harmful alignment shift during training. We further decouple the representation space from the optimization space with a lightweight specialization projection, allowing task-specific adaptation without directly overspecializing the representations used at test time. \emph{TACO} establishes state-of-the-art performance on diverse benchmarks under cross-dataset and base-to-novel settings. Code will be released at https://github.com/ZMHH-H/TACO.
P2DNav: Panorama-to-Downview Reasoning for Zero-shot Vision-and-Language Navigation
May 19, 2026Vision-and-language navigation (VLN) requires an embodied agent to ground natural-language instructions into executable navigation actions in unseen environments. Existing zero-shot methods typically rely on additional waypoint prediction modules, which often entangle high-level directional reasoning with fine-grained local grounding, leading to error-prone and unstable decisions. In this paper, we propose P2DNav, a hierarchical framework for zero-shot vision-and-language navigation. P2DNav consists of three core components: Panorama-to-Downview (P2D), Sliding-Window Dialogue Memory (SDM), and Reflective Reorientation Mechanism (RRM). P2D explicitly decomposes navigation decision-making into two stages: panoramic direction selection and downview local grounding. It first selects the instruction-relevant direction from a 360° panorama, and then predicts a pixel-level target point from the downview RGB observation in that direction. In addition, SDM organizes navigation history as a multi-turn dialogue context and maintains recent visual observations within a sliding window to support long-horizon navigation. RRM further enables reflective reorientation by assessing the reliability of local grounding based on the downview observation and returning to panoramic direction selection when necessary. Experiments on the R2R-CE benchmark show that P2DNav achieves strong performance among zero-shot methods. In particular, compared with the state-of-the-art (SOTA) zero-shot waypoint-based and waypoint-free methods, P2DNav achieves SR gains of 146.6% and 58.9%, respectively, demonstrating the effectiveness of P2D, SDM, and RRM for zero-shot VLN. Code will be released for public use.
GroundVTS: Visual Token Sampling in Multimodal Large Language Models for Video Temporal Grounding
Apr 02, 2026Video temporal grounding (VTG) is a critical task in video understanding and a key capability for extending video large language models (Vid-LLMs) to broader applications. However, existing Vid-LLMs rely on uniform frame sampling to extract video information, resulting in a sparse distribution of key frames and the loss of crucial temporal cues. To address this limitation, we propose Grounded Visual Token Sampling (GroundVTS), a Vid-LLM architecture that focuses on the most informative temporal segments. GroundVTS employs a fine-grained, query-guided mechanism to filter visual tokens before feeding them into the LLM, thereby preserving essential spatio-temporal information and maintaining temporal coherence. Futhermore, we introduce a progressive optimization strategy that enables the LLM to effectively adapt to the non-uniform distribution of visual features, enhancing its ability to model temporal dependencies and achieve precise video localization. We comprehensively evaluate GroundVTS on three standard VTG benchmarks, where it outperforms existing methods, achieving a 7.7-point improvement in mIoU for moment retrieval and 12.0-point improvement in mAP for highlight detection. Code is available at https://github.com/Florence365/GroundVTS.
Deconfounded Lifelong Learning for Autonomous Driving via Dynamic Knowledge Spaces
Mar 15, 2026End-to-End autonomous driving (E2E-AD) systems face challenges in lifelong learning, including catastrophic forgetting, difficulty in knowledge transfer across diverse scenarios, and spurious correlations between unobservable confounders and true driving intents. To address these issues, we propose DeLL, a Deconfounded Lifelong Learning framework that integrates a Dirichlet process mixture model (DPMM) with the front-door adjustment mechanism from causal inference. The DPMM is employed to construct two dynamic knowledge spaces: a trajectory knowledge space for clustering explicit driving behaviors and an implicit feature knowledge space for discovering latent driving abilities. Leveraging the non-parametric Bayesian nature of DPMM, our framework enables adaptive expansion and incremental updating of knowledge without predefining the number of clusters, thereby mitigating catastrophic forgetting. Meanwhile, the front-door adjustment mechanism utilizes the DPMM-derived knowledge as valid mediators to deconfound spurious correlations, such as those induced by sensor noise or environmental changes, and enhances the causal expressiveness of the learned representations. Additionally, we introduce an evolutionary trajectory decoder that enables non-autoregressive planning. To evaluate the lifelong learning performance of E2E-AD, we propose new evaluation protocols and metrics based on Bench2Drive. Extensive evaluations in the closed-loop CARLA simulator demonstrate that our framework significantly improves adaptability to new driving scenarios and overall driving performance, while effectively retaining previous acquired knowledge.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025



Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
CLASH: Collaborative Large-Small Hierarchical Framework for Continuous Vision-and-Language Navigation
Dec 11, 2025Vision-and-Language Navigation (VLN) requires robots to follow natural language instructions and navigate complex environments without prior maps. While recent vision-language large models demonstrate strong reasoning abilities, they often underperform task-specific panoramic small models in VLN tasks. To address this, we propose CLASH (Collaborative Large-Small Hierarchy), a VLN-CE framework that integrates a reactive small-model planner (RSMP) with a reflective large-model reasoner (RLMR). RSMP adopts a causal-learning-based dual-branch architecture to enhance generalization, while RLMR leverages panoramic visual prompting with chain-of-thought reasoning to support interpretable spatial understanding and navigation. We further introduce an uncertainty-aware collaboration mechanism (UCM) that adaptively fuses decisions from both models. For obstacle avoidance, in simulation, we replace the rule-based controller with a fully learnable point-goal policy, and in real-world deployment, we design a LiDAR-based clustering module for generating navigable waypoints and pair it with an online SLAM-based local controller. CLASH achieves state-of-the-art (SoTA) results (ranking 1-st) on the VLN-CE leaderboard, significantly improving SR and SPL on the test-unseen set over the previous SoTA methods. Real-world experiments demonstrate CLASH's strong robustness, validating its effectiveness in both simulation and deployment scenarios.
Temporal-Guided Visual Foundation Models for Event-Based Vision
Nov 09, 2025



Event cameras offer unique advantages for vision tasks in challenging environments, yet processing asynchronous event streams remains an open challenge. While existing methods rely on specialized architectures or resource-intensive training, the potential of leveraging modern Visual Foundation Models (VFMs) pretrained on image data remains under-explored for event-based vision. To address this, we propose Temporal-Guided VFM (TGVFM), a novel framework that integrates VFMs with our temporal context fusion block seamlessly to bridge this gap. Our temporal block introduces three key components: (1) Long-Range Temporal Attention to model global temporal dependencies, (2) Dual Spatiotemporal Attention for multi-scale frame correlation, and (3) Deep Feature Guidance Mechanism to fuse semantic-temporal features. By retraining event-to-video models on real-world data and leveraging transformer-based VFMs, TGVFM preserves spatiotemporal dynamics while harnessing pretrained representations. Experiments demonstrate SoTA performance across semantic segmentation, depth estimation, and object detection, with improvements of 16%, 21%, and 16% over existing methods, respectively. Overall, this work unlocks the cross-modality potential of image-based VFMs for event-based vision with temporal reasoning. Code is available at https://github.com/XiaRho/TGVFM.
Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual Disparities
Jul 17, 2025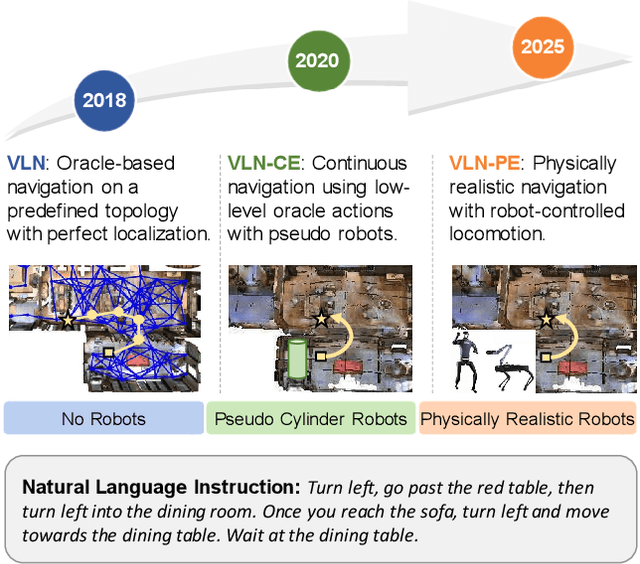
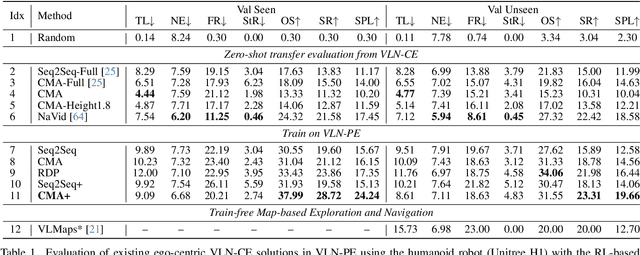
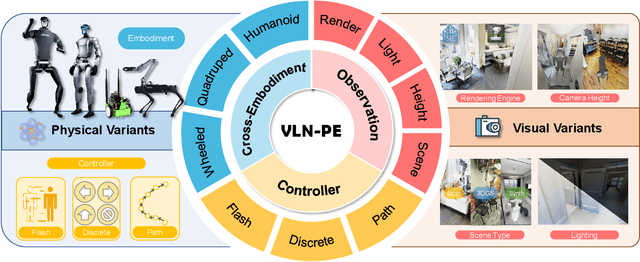

Recent Vision-and-Language Navigation (VLN) advancements are promising, but their idealized assumptions about robot movement and control fail to reflect physically embodied deployment challenges. To bridge this gap, we introduce VLN-PE, a physically realistic VLN platform supporting humanoid, quadruped, and wheeled robots. For the first time, we systematically evaluate several ego-centric VLN methods in physical robotic settings across different technical pipelines, including classification models for single-step discrete action prediction, a diffusion model for dense waypoint prediction, and a train-free, map-based large language model (LLM) integrated with path planning. Our results reveal significant performance degradation due to limited robot observation space, environmental lighting variations, and physical challenges like collisions and falls. This also exposes locomotion constraints for legged robots in complex environments. VLN-PE is highly extensible, allowing seamless integration of new scenes beyond MP3D, thereby enabling more comprehensive VLN evaluation. Despite the weak generalization of current models in physical deployment, VLN-PE provides a new pathway for improving cross-embodiment's overall adaptability. We hope our findings and tools inspire the community to rethink VLN limitations and advance robust, practical VLN models. The code is available at https://crystalsixone.github.io/vln_pe.github.io/.
CleanPose: Category-Level Object Pose Estimation via Causal Learning and Knowledge Distillation
Feb 03, 2025



Category-level object pose estimation aims to recover the rotation, translation and size of unseen instances within predefined categories. In this task, deep neural network-based methods have demonstrated remarkable performance. However, previous studies show they suffer from spurious correlations raised by "unclean" confounders in models, hindering their performance on novel instances with significant variations. To address this issue, we propose CleanPose, a novel approach integrating causal learning and knowledge distillation to enhance category-level pose estimation. To mitigate the negative effect of unobserved confounders, we develop a causal inference module based on front-door adjustment, which promotes unbiased estimation by reducing potential spurious correlations. Additionally, to further improve generalization ability, we devise a residual-based knowledge distillation method that has proven effective in providing comprehensive category information guidance. Extensive experiments across multiple benchmarks (REAL275, CAMERA25 and HouseCat6D) hightlight the superiority of proposed CleanPose over state-of-the-art methods. Code will be released.