 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Based Prototype Calibration for Multi-Rater Few-Shot Medical Image Segmentation
Jun 15, 2026Few-shot medical image segmentation methods typically assume a single ground-truth annotation, overlooking systematic variability across expert raters commonly observed in clinical datasets. We propose an attention-based prototype calibration framework for few-shot multi-rater segmentation that models rater-specific deviations from a consensus representation in prototype space. A lightweight yet principled attention operator directly refines rater prototypes without modifying the backbone feature extractor, making the approach fully compatible with existing prototype-based few-shot segmentation methods. This design preserves semantic consistency while enabling personalized segmentation outputs with minimal computational overhead. Experiments on multi-rater medical imaging datasets demonstrate consistent improvements over baseline prototype approaches, highlighting the effectiveness of structured prototype calibration for modeling annotation variability. Our code is available at https://github.com/truong2710-cyber/JAPC.
Beyond the Global Scores: Fine-Grained Token Grounding as a Robust Detector of LVLM Hallucinations
Apr 06, 2026Large vision-language models (LVLMs) achieve strong performance on visual reasoning tasks but remain highly susceptible to hallucination. Existing detection methods predominantly rely on coarse, whole-image measures of how an object token relates to the input image. This global strategy is limited: hallucinated tokens may exhibit weak but widely scattered correlations across many local regions, which aggregate into deceptively high overall relevance, thus evading the current global hallucination detectors. We begin with a simple yet critical observation: a faithful object token must be strongly grounded in a specific image region. Building on this insight, we introduce a patch-level hallucination detection framework that examines fine-grained token-level interactions across model layers. Our analysis uncovers two characteristic signatures of hallucinated tokens: (i) they yield diffuse, non-localized attention patterns, in contrast to the compact, well-focused attention seen in faithful tokens; and (ii) they fail to exhibit meaningful semantic alignment with any visual region. Guided by these findings, we develop a lightweight and interpretable detection method that leverages patch-level statistical features, combined with hidden-layer representations. Our approach achieves up to 90% accuracy in token-level hallucination detection, demonstrating the superiority of fine-grained structural analysis for detecting hallucinations.
Overthinking Causes Hallucination: Tracing Confounder Propagation in Vision Language Models
Mar 08, 2026Vision Language models (VLMs) often hallucinate non-existent objects. Detecting hallucination is analogous to detecting deception: a single final statement is insufficient, one must examine the underlying reasoning process. Yet existing detectors rely mostly on final-layer signals. Attention-based methods assume hallucinated tokens exhibit low attention, while entropy-based ones use final-step uncertainty. Our analysis reveals the opposite: hallucinated objects can exhibit peaked attention due to contextual priors; and models often express high confidence because intermediate layers have already converged to an incorrect hypothesis. We show that the key to hallucination detection lies within the model's thought process, not its final output. By probing decoder layers, we uncover a previously overlooked behavior, overthinking: models repeatedly revise object hypotheses across layers before committing to an incorrect answer. Once the model latches onto a confounded hypothesis, it can propagate through subsequent layers, ultimately causing hallucination. To capture this behavior, we introduce the Overthinking Score, a metric to measure how many competing hypotheses the model entertains and how unstable these hypotheses are across layers. This score significantly improves hallucination detection: 78.9% F1 on MSCOCO and 71.58% on AMBER.
Localizing Before Answering: A Hallucination Evaluation Benchmark for Grounded Medical Multimodal LLMs
May 05, 2025Medical Large Multi-modal Models (LMMs) have demonstrated remarkable capabilities in medical data interpretation. However, these models frequently generate hallucinations contradicting source evidence, particularly due to inadequate localization reasoning. This work reveals a critical limitation in current medical LMMs: instead of analyzing relevant pathological regions, they often rely on linguistic patterns or attend to irrelevant image areas when responding to disease-related queries. To address this, we introduce HEAL-MedVQA (Hallucination Evaluation via Localization MedVQA), a comprehensive benchmark designed to evaluate LMMs' localization abilities and hallucination robustness. HEAL-MedVQA features (i) two innovative evaluation protocols to assess visual and textual shortcut learning, and (ii) a dataset of 67K VQA pairs, with doctor-annotated anatomical segmentation masks for pathological regions. To improve visual reasoning, we propose the Localize-before-Answer (LobA) framework, which trains LMMs to localize target regions of interest and self-prompt to emphasize segmented pathological areas, generating grounded and reliable answers. Experimental results demonstrate that our approach significantly outperforms state-of-the-art biomedical LMMs on the challenging HEAL-MedVQA benchmark, advancing robustness in medical VQA.
TrafficVLM: A Controllable Visual Language Model for Traffic Video Captioning
Apr 14, 2024
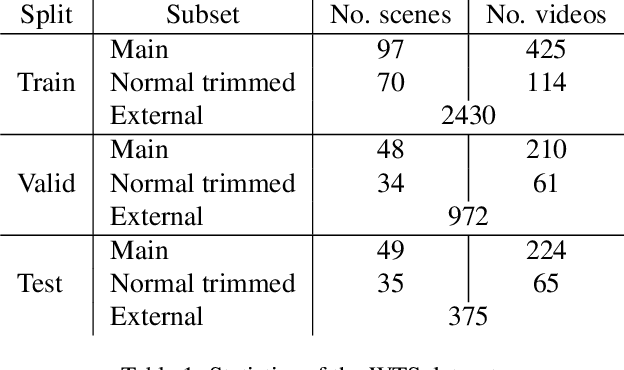

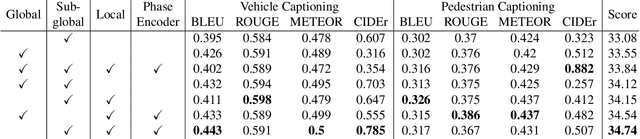
Traffic video description and analysis have received much attention recently due to the growing demand for efficient and reliable urban surveillance systems. Most existing methods only focus on locating traffic event segments, which severely lack descriptive details related to the behaviour and context of all the subjects of interest in the events. In this paper, we present TrafficVLM, a novel multi-modal dense video captioning model for vehicle ego camera view. TrafficVLM models traffic video events at different levels of analysis, both spatially and temporally, and generates long fine-grained descriptions for the vehicle and pedestrian at different phases of the event. We also propose a conditional component for TrafficVLM to control the generation outputs and a multi-task fine-tuning paradigm to enhance TrafficVLM's learning capability. Experiments show that TrafficVLM performs well on both vehicle and overhead camera views. Our solution achieved outstanding results in Track 2 of the AI City Challenge 2024, ranking us third in the challenge standings. Our code is publicly available at https://github.com/quangminhdinh/TrafficVLM.