 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri--Rao Product
Aug 01, 2025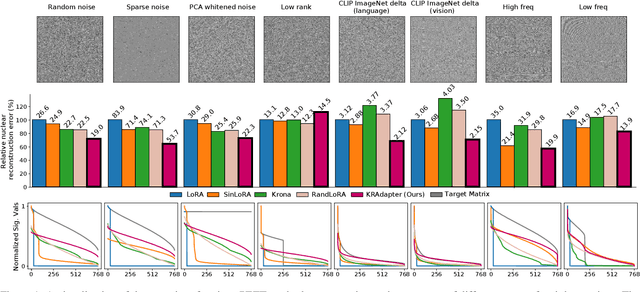
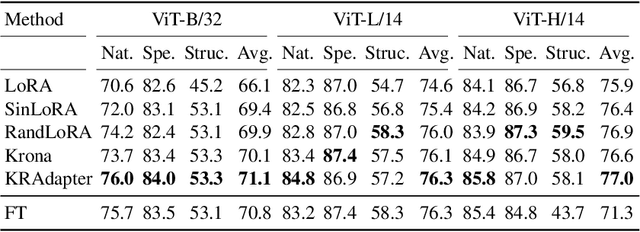
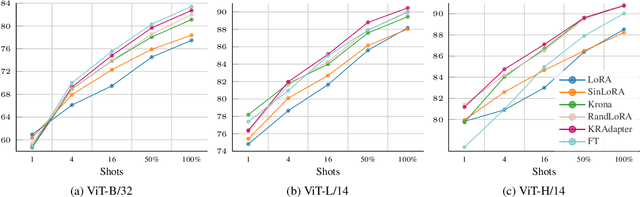
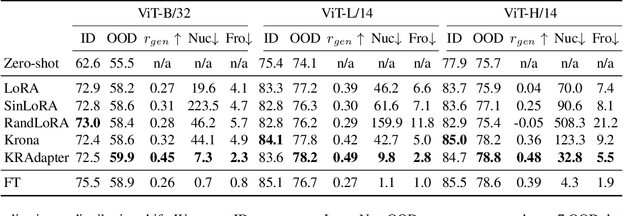
Parameter-efficient fine-tuning (PEFT) has become a standard approach for adapting large pre-trained models. Amongst PEFT methods, low-rank adaptation (LoRA) has achieved notable success. However, recent studies have highlighted its limitations compared against full-rank alternatives, particularly when applied to multimodal and large language models. In this work, we present a quantitative comparison amongst full-rank and low-rank PEFT methods using a synthetic matrix approximation benchmark with controlled spectral properties. Our results confirm that LoRA struggles to approximate matrices with relatively flat spectrums or high frequency components -- signs of high effective ranks. To this end, we introduce KRAdapter, a novel PEFT algorithm that leverages the Khatri-Rao product to produce weight updates, which, by construction, tends to produce matrix product with a high effective rank. We demonstrate performance gains with KRAdapter on vision-language models up to 1B parameters and on large language models up to 8B parameters, particularly on unseen common-sense reasoning tasks. In addition, KRAdapter maintains the memory and compute efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models.
RandLoRA: Full-rank parameter-efficient fine-tuning of large models
Feb 03, 2025Low-Rank Adaptation (LoRA) and its variants have shown impressive results in reducing the number of trainable parameters and memory requirements of large transformer networks while maintaining fine-tuning performance. However, the low-rank nature of the weight update inherently limits the representation power of fine-tuned models, potentially compromising performance on complex tasks. This raises a critical question: when a performance gap between LoRA and standard fine-tuning is observed, is it due to the reduced number of trainable parameters or the rank deficiency? This paper aims to answer this question by introducing RandLoRA, a parameter-efficient method that performs full-rank updates using a learned linear combinations of low-rank, non-trainable random matrices. Our method limits the number of trainable parameters by restricting optimization to diagonal scaling matrices applied to the fixed random matrices. This allows us to effectively overcome the low-rank limitations while maintaining parameter and memory efficiency during training. Through extensive experimentation across vision, language, and vision-language benchmarks, we systematically evaluate the limitations of LoRA and existing random basis methods. Our findings reveal that full-rank updates are beneficial across vision and language tasks individually, and even more so for vision-language tasks, where RandLoRA significantly reduces -- and sometimes eliminates -- the performance gap between standard fine-tuning and LoRA, demonstrating its efficacy.
Temporally Grounding Instructional Diagrams in Unconstrained Videos
Jul 16, 2024



We study the challenging problem of simultaneously localizing a sequence of queries in the form of instructional diagrams in a video. This requires understanding not only the individual queries but also their interrelationships. However, most existing methods focus on grounding one query at a time, ignoring the inherent structures among queries such as the general mutual exclusiveness and the temporal order. Consequently, the predicted timespans of different step diagrams may overlap considerably or violate the temporal order, thus harming the accuracy. In this paper, we tackle this issue by simultaneously grounding a sequence of step diagrams. Specifically, we propose composite queries, constructed by exhaustively pairing up the visual content features of the step diagrams and a fixed number of learnable positional embeddings. Our insight is that self-attention among composite queries carrying different content features suppress each other to reduce timespan overlaps in predictions, while the cross-attention corrects the temporal misalignment via content and position joint guidance. We demonstrate the effectiveness of our approach on the IAW dataset for grounding step diagrams and the YouCook2 benchmark for grounding natural language queries, significantly outperforming existing methods while simultaneously grounding multiple queries.
Knowledge Composition using Task Vectors with Learned Anisotropic Scaling
Jul 03, 2024



Pre-trained models produce strong generic representations that can be adapted via fine-tuning. The learned weight difference relative to the pre-trained model, known as a task vector, characterises the direction and stride of fine-tuning. The significance of task vectors is such that simple arithmetic operations on them can be used to combine diverse representations from different domains. This paper builds on these properties of task vectors and aims to answer (1) whether components of task vectors, particularly parameter blocks, exhibit similar characteristics, and (2) how such blocks can be used to enhance knowledge composition and transfer. To this end, we introduce aTLAS, an algorithm that linearly combines parameter blocks with different learned coefficients, resulting in anisotropic scaling at the task vector level. We show that such linear combinations explicitly exploit the low intrinsic dimensionality of pre-trained models, with only a few coefficients being the learnable parameters. Furthermore, composition of parameter blocks leverages the already learned representations, thereby reducing the dependency on large amounts of data. We demonstrate the effectiveness of our method in task arithmetic, few-shot recognition and test-time adaptation, with supervised or unsupervised objectives. In particular, we show that (1) learned anisotropic scaling allows task vectors to be more disentangled, causing less interference in composition; (2) task vector composition excels with scarce or no labeled data and is less prone to domain shift, thus leading to better generalisability; (3) mixing the most informative parameter blocks across different task vectors prior to training can reduce the memory footprint and improve the flexibility of knowledge transfer. Moreover, we show the potential of aTLAS as a PEFT method, particularly with less data, and demonstrate that its scalibility.
Exploring Predicate Visual Context in Detecting of Human-Object Interactions
Aug 11, 2023Recently, the DETR framework has emerged as the dominant approach for human--object interaction (HOI) research. In particular, two-stage transformer-based HOI detectors are amongst the most performant and training-efficient approaches. However, these often condition HOI classification on object features that lack fine-grained contextual information, eschewing pose and orientation information in favour of visual cues about object identity and box extremities. This naturally hinders the recognition of complex or ambiguous interactions. In this work, we study these issues through visualisations and carefully designed experiments. Accordingly, we investigate how best to re-introduce image features via cross-attention. With an improved query design, extensive exploration of keys and values, and box pair positional embeddings as spatial guidance, our model with enhanced predicate visual context (PViC) outperforms state-of-the-art methods on the HICO-DET and V-COCO benchmarks, while maintaining low training cost.
Efficient Two-Stage Detection of Human-Object Interactions with a Novel Unary-Pairwise Transformer
Dec 03, 2021
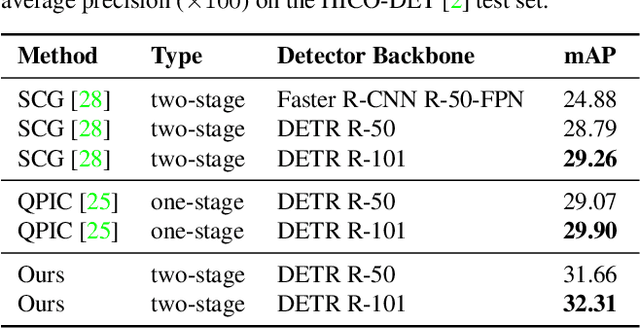
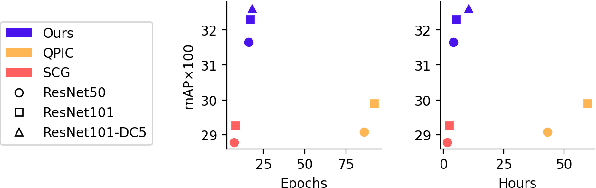
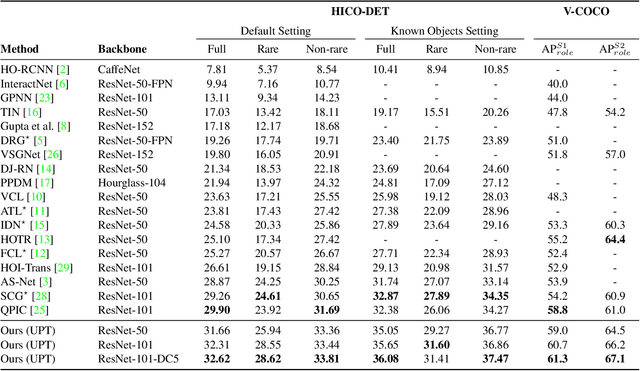
Recent developments in transformer models for visual data have led to significant improvements in recognition and detection tasks. In particular, using learnable queries in place of region proposals has given rise to a new class of one-stage detection models, spearheaded by the Detection Transformer (DETR). Variations on this one-stage approach have since dominated human-object interaction (HOI) detection. However, the success of such one-stage HOI detectors can largely be attributed to the representation power of transformers. We discovered that when equipped with the same transformer, their two-stage counterparts can be more performant and memory-efficient, while taking a fraction of the time to train. In this work, we propose the Unary-Pairwise Transformer, a two-stage detector that exploits unary and pairwise representations for HOIs. We observe that the unary and pairwise parts of our transformer network specialise, with the former preferentially increasing the scores of positive examples and the latter decreasing the scores of negative examples. We evaluate our method on the HICO-DET and V-COCO datasets, and significantly outperform state-of-the-art approaches. At inference time, our model with ResNet50 approaches real-time performance on a single GPU.
Spatio-attentive Graphs for Human-Object Interaction Detection
Dec 11, 2020
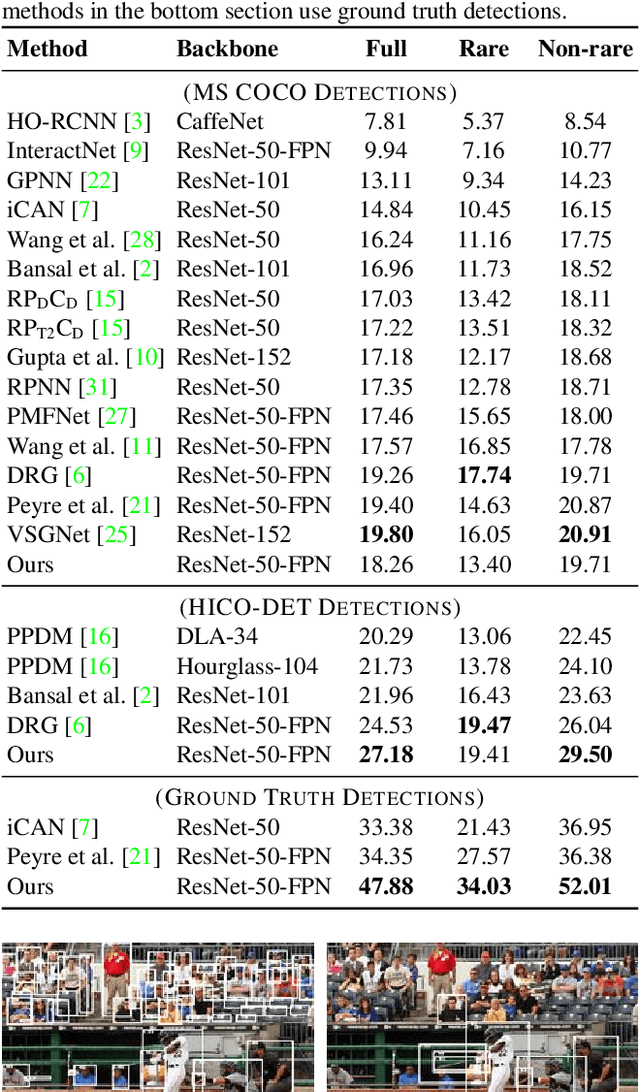
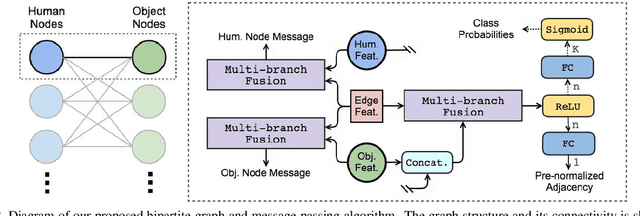
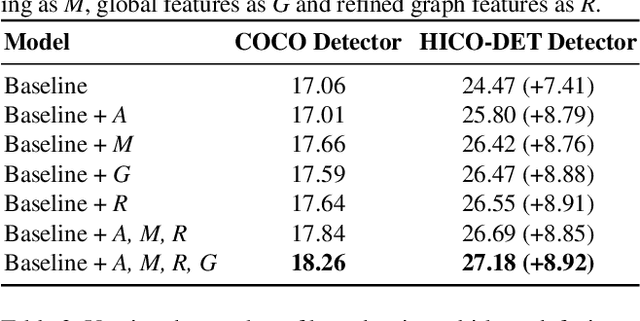
We address the problem of detecting human--object interactions in images using graphical neural networks. Our network constructs a bipartite graph of nodes representing detected humans and objects, wherein messages passed between the nodes encode relative spatial and appearance information. Unlike existing approaches that separate appearance and spatial features, our method fuses these two cues within a single graphical model allowing information conditioned on both modalities to influence the prediction of interactions with neighboring nodes. Through extensive experimentation we demonstrate the advantages of fusing relative spatial information with appearance features in the computation of adjacency structure, message passing and the ultimate refined graph features. On the popular HICO-DET benchmark dataset, our model outperforms state-of-the-art with an mAP of 27.18, a 10% relative improvement.