 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: A Multi-Agent System for GPU Kernel Performance Optimization
Sep 09, 2025GPU kernel optimization has long been a central challenge at the intersection of high-performance computing and machine learning. Efficient kernels are crucial for accelerating large language model (LLM) training and serving, yet attaining high performance typically requires extensive manual tuning. Compiler-based systems reduce some of this burden, but still demand substantial manual design and engineering effort. Recently, researchers have explored using LLMs for GPU kernel generation, though prior work has largely focused on translating high-level PyTorch modules into CUDA code. In this work, we introduce Astra, the first LLM-based multi-agent system for GPU kernel optimization. Unlike previous approaches, Astra starts from existing CUDA implementations extracted from SGLang, a widely deployed framework for serving LLMs, rather than treating PyTorch modules as the specification. Within Astra, specialized LLM agents collaborate through iterative code generation, testing, profiling, and planning to produce kernels that are both correct and high-performance. On kernels from SGLang, Astra achieves an average speedup of 1.32x using zero-shot prompting with OpenAI o4-mini. A detailed case study further demonstrates that LLMs can autonomously apply loop transformations, optimize memory access patterns, exploit CUDA intrinsics, and leverage fast math operations to yield substantial performance gains. Our work highlights multi-agent LLM systems as a promising new paradigm for GPU kernel optimization.
SATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
May 20, 2025



We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
May 16, 2025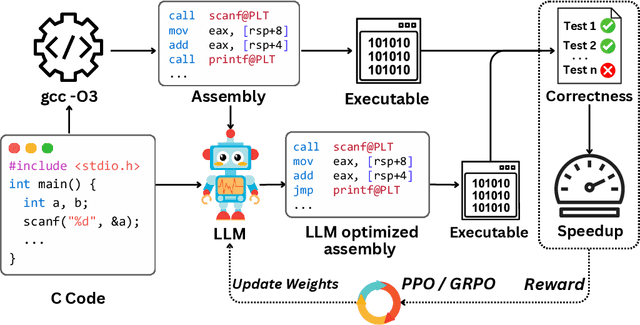
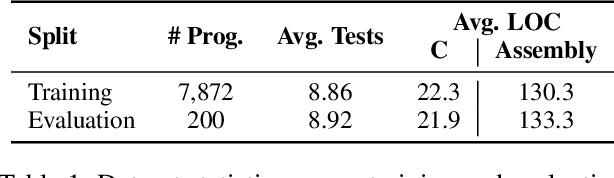
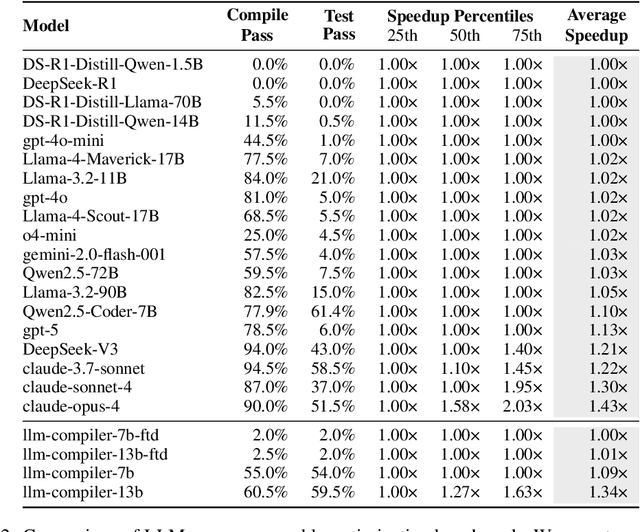

Large language models (LLMs) have demonstrated strong performance across a wide range of programming tasks, yet their potential for code optimization remains underexplored. This work investigates whether LLMs can optimize the performance of assembly code, where fine-grained control over execution enables improvements that are difficult to express in high-level languages. We present a reinforcement learning framework that trains LLMs using Proximal Policy Optimization (PPO), guided by a reward function that considers both functional correctness, validated through test cases, and execution performance relative to the industry-standard compiler gcc -O3. To support this study, we introduce a benchmark of 8,072 real-world programs. Our model, Qwen2.5-Coder-7B-PPO, achieves 96.0% test pass rates and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all 20 other models evaluated, including Claude-3.7-sonnet. These results indicate that reinforcement learning can unlock the potential of LLMs to serve as effective optimizers for assembly code performance.
ClarifyCoder: Clarification-Aware Fine-Tuning for Programmatic Problem Solving
Apr 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, a significant gap remains between their current performance and that of expert software engineers. A key differentiator is that human engineers actively seek clarification when faced with ambiguous requirements, while LLMs typically generate code regardless of uncertainties in the problem description. We present ClarifyCoder, a novel framework with synthetic data generation and instruction-tuning that enables LLMs to identify ambiguities and request clarification before proceeding with code generation. While recent work has focused on LLM-based agents for iterative code generation, we argue that the fundamental ability to recognize and query ambiguous requirements should be intrinsic to the models themselves. Our approach consists of two main components: (1) a data synthesis technique that augments existing programming datasets with scenarios requiring clarification to generate clarification-aware training data, and (2) a fine-tuning strategy that teaches models to prioritize seeking clarification over immediate code generation when faced with incomplete or ambiguous requirements. We further provide an empirical analysis of integrating ClarifyCoder with standard fine-tuning for a joint optimization of both clarify-awareness and coding ability. Experimental results demonstrate that ClarifyCoder significantly improves the communication capabilities of Code LLMs through meaningful clarification dialogues while maintaining code generation capabilities.
VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Apr 22, 2025



Recent advances in Large Language Models (LLMs) have sparked growing interest in applying them to Electronic Design Automation (EDA) tasks, particularly Register Transfer Level (RTL) code generation. While several RTL datasets have been introduced, most focus on syntactic validity rather than functional validation with tests, leading to training examples that compile but may not implement the intended behavior. We present VERICODER, a model for RTL code generation fine-tuned on a dataset validated for functional correctness. This fine-tuning dataset is constructed using a novel methodology that combines unit test generation with feedback-directed refinement. Given a natural language specification and an initial RTL design, we prompt a teacher model (GPT-4o-mini) to generate unit tests and iteratively revise the RTL design based on its simulation results using the generated tests. If necessary, the teacher model also updates the tests to ensure they comply with the natural language specification. As a result of this process, every example in our dataset is functionally validated, consisting of a natural language description, an RTL implementation, and passing tests. Fine-tuned on this dataset of over 125,000 examples, VERICODER achieves state-of-the-art metrics in functional correctness on VerilogEval and RTLLM, with relative gains of up to 71.7% and 27.4% respectively. An ablation study further shows that models trained on our functionally validated dataset outperform those trained on functionally non-validated datasets, underscoring the importance of high-quality datasets in RTL code generation.
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis
Mar 29, 2025Inductive program synthesis, or programming by example, requires synthesizing functions from input-output examples that generalize to unseen inputs. While large language model agents have shown promise in programming tasks guided by natural language, their ability to perform inductive program synthesis is underexplored. Existing evaluation protocols rely on static sets of examples and held-out tests, offering no feedback when synthesized functions are incorrect and failing to reflect real-world scenarios such as reverse engineering. We propose CodeARC, the Code Abstraction and Reasoning Challenge, a new evaluation framework where agents interact with a hidden target function by querying it with new inputs, synthesizing candidate functions, and iteratively refining their solutions using a differential testing oracle. This interactive setting encourages agents to perform function calls and self-correction based on feedback. We construct the first large-scale benchmark for general-purpose inductive program synthesis, featuring 1114 functions. Among 18 models evaluated, o3-mini performs best with a success rate of 52.7%, highlighting the difficulty of this task. Fine-tuning LLaMA-3.1-8B-Instruct on curated synthesis traces yields up to a 31% relative performance gain. CodeARC provides a more realistic and challenging testbed for evaluating LLM-based program synthesis and inductive reasoning.
EquiBench: Benchmarking Code Reasoning Capabilities of Large Language Models via Equivalence Checking
Feb 18, 2025



Equivalence checking, i.e., determining whether two programs produce identical outputs for all possible inputs, underpins a broad range of applications, including software refactoring, testing, and optimization. We present the task of equivalence checking as a new way to evaluate the code reasoning abilities of large language models (LLMs). We introduce EquiBench, a dataset of 2400 program pairs spanning four programming languages and six equivalence categories. These pairs are systematically generated through program analysis, compiler scheduling, and superoptimization, covering nontrivial structural transformations that demand deep semantic reasoning beyond simple syntactic variations. Our evaluation of 17 state-of-the-art LLMs shows that OpenAI o3-mini achieves the highest overall accuracy of 78.0%. In the most challenging categories, the best accuracies are 62.3% and 68.8%, only modestly above the 50% random baseline for binary classification, indicating significant room for improvement in current models' code reasoning capabilities.
Automated Generation of Challenging Multiple-Choice Questions for Vision Language Model Evaluation
Jan 06, 2025



The rapid development of vision language models (VLMs) demands rigorous and reliable evaluation. However, current visual question answering (VQA) benchmarks often depend on open-ended questions, making accurate evaluation difficult due to the variability in natural language responses. To address this, we introduce AutoConverter, an agentic framework that automatically converts these open-ended questions into multiple-choice format, enabling objective evaluation while reducing the costly question creation process. Our experiments demonstrate that AutoConverter can generate correct and challenging multiple-choice questions, with VLMs demonstrating consistently similar or lower accuracy on these questions compared to human-created ones. Using AutoConverter, we construct VMCBench, a benchmark created by transforming 20 existing VQA datasets into a unified multiple-choice format, totaling 9,018 questions. We comprehensively evaluate 33 state-of-the-art VLMs on VMCBench, setting a new standard for scalable, consistent, and reproducible VLM evaluation.
Improving Parallel Program Performance Through DSL-Driven Code Generation with LLM Optimizers
Oct 21, 2024Mapping computations to processors and assigning data to memory are critical for maximizing performance in parallel programming. These mapping decisions are managed through the development of specialized low-level system code, called mappers, crafted by performance engineers. Each mapper is tailored to a specific application and optimized for the underlying machine architecture, a process that requires days of refinement and tuning from an expert. Despite advances in system research, automating mapper generation remains a challenge due to the complexity of making millions of decisions to find the optimal solution and generate the solution as code. We introduce an approach that leverages recent advances in LLM-based optimizers for mapper design. In under ten minutes, our method automatically discovers mappers that surpass human expert designs in scientific applications by up to 1.34X speedup. For parallel matrix multiplication algorithms, our mapper achieves up to 1.31X of the expert-designed solution. To achieve this, we simplify the complexity of low-level code generation by introducing a domain-specific language (DSL) that abstracts the low-level system programming details and defines a structured search space for LLMs to explore. To maximize the application performance, we use an LLM optimizer to improve an agentic system that generates the mapper code. As a result, this approach significantly reduces the workload for performance engineers while achieving substantial performance gains across diverse applications. Finally, our results demonstrate the effectiveness of LLM-based optimization in system design and suggest its potential for addressing other complex system challenges.