 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuTeGen: An LLM-Based Agentic Framework for Generation and Optimization of High-Performance GPU Kernels using CuTe
Apr 01, 2026High-performance GPU kernels are critical to modern machine learning systems, yet developing efficient implementations remains a challenging, expert-driven process due to the tight coupling between algorithmic structure, memory hierarchy usage, and hardware-specific optimizations. Recent work has explored using large language models (LLMs) to generate GPU kernels automatically, but generated implementations often struggle to maintain correctness and achieve competitive performance across iterative refinements. We present CuTeGen, an agentic framework for automated generation and optimization of GPU kernels that treats kernel development as a structured generate--test--refine workflow. Unlike approaches that rely on one-shot generation or large-scale search over candidate implementations, CuTeGen focuses on progressive refinement of a single evolving kernel through execution-based validation, structured debugging, and staged optimization. A key design choice is to generate kernels using the CuTe abstraction layer, which exposes performance-critical structures such as tiling and data movement while providing a more stable representation for iterative modification. To guide performance improvement, CuTeGen incorporates workload-aware optimization prompts and delayed integration of profiling feedback. Experimental results on matrix multiplication and activation workloads demonstrate that the framework produces functionally correct kernels and achieves competitive performance relative to optimized library implementations.
Astra: A Multi-Agent System for GPU Kernel Performance Optimization
Sep 09, 2025GPU kernel optimization has long been a central challenge at the intersection of high-performance computing and machine learning. Efficient kernels are crucial for accelerating large language model (LLM) training and serving, yet attaining high performance typically requires extensive manual tuning. Compiler-based systems reduce some of this burden, but still demand substantial manual design and engineering effort. Recently, researchers have explored using LLMs for GPU kernel generation, though prior work has largely focused on translating high-level PyTorch modules into CUDA code. In this work, we introduce Astra, the first LLM-based multi-agent system for GPU kernel optimization. Unlike previous approaches, Astra starts from existing CUDA implementations extracted from SGLang, a widely deployed framework for serving LLMs, rather than treating PyTorch modules as the specification. Within Astra, specialized LLM agents collaborate through iterative code generation, testing, profiling, and planning to produce kernels that are both correct and high-performance. On kernels from SGLang, Astra achieves an average speedup of 1.32x using zero-shot prompting with OpenAI o4-mini. A detailed case study further demonstrates that LLMs can autonomously apply loop transformations, optimize memory access patterns, exploit CUDA intrinsics, and leverage fast math operations to yield substantial performance gains. Our work highlights multi-agent LLM systems as a promising new paradigm for GPU kernel optimization.
Accelerating Training and Inference of Graph Neural Networks with Fast Sampling and Pipelining
Oct 16, 2021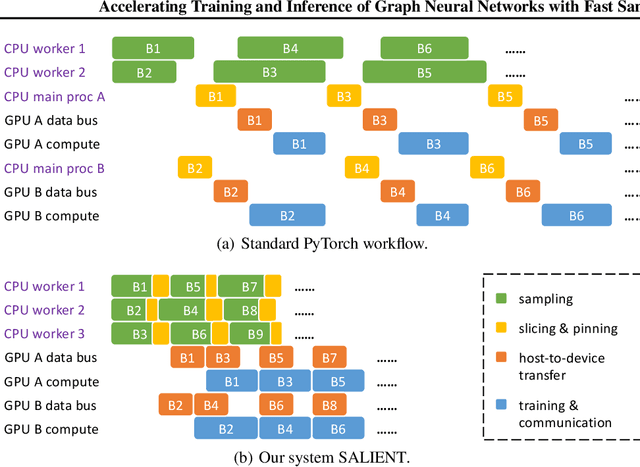
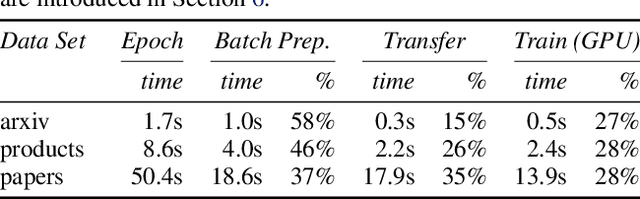
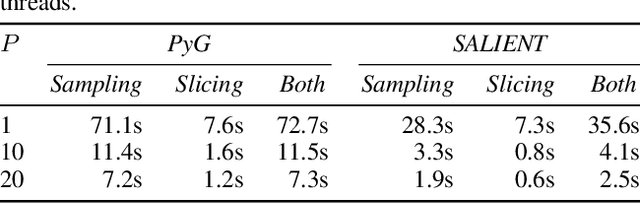
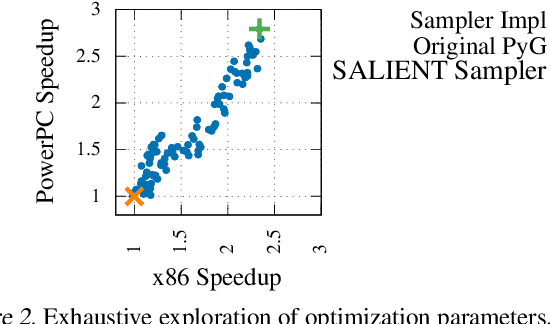
Improving the training and inference performance of graph neural networks (GNNs) is faced with a challenge uncommon in general neural networks: creating mini-batches requires a lot of computation and data movement due to the exponential growth of multi-hop graph neighborhoods along network layers. Such a unique challenge gives rise to a diverse set of system design choices. We argue in favor of performing mini-batch training with neighborhood sampling in a distributed multi-GPU environment, under which we identify major performance bottlenecks hitherto under-explored by developers: mini-batch preparation and transfer. We present a sequence of improvements to mitigate these bottlenecks, including a performance-engineered neighborhood sampler, a shared-memory parallelization strategy, and the pipelining of batch transfer with GPU computation. We also conduct an empirical analysis that supports the use of sampling for inference, showing that test accuracies are not materially compromised. Such an observation unifies training and inference, simplifying model implementation. We report comprehensive experimental results with several benchmark data sets and GNN architectures, including a demonstration that, for the ogbn-papers100M data set, our system SALIENT achieves a speedup of 3x over a standard PyTorch-Geometric implementation with a single GPU and a further 8x parallel speedup with 16 GPUs. Therein, training a 3-layer GraphSAGE model with sampling fanout (15, 10, 5) takes 2.0 seconds per epoch and inference with fanout (20, 20, 20) takes 2.4 seconds, attaining test accuracy 64.58%.