 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
May 20, 2025



We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
May 16, 2025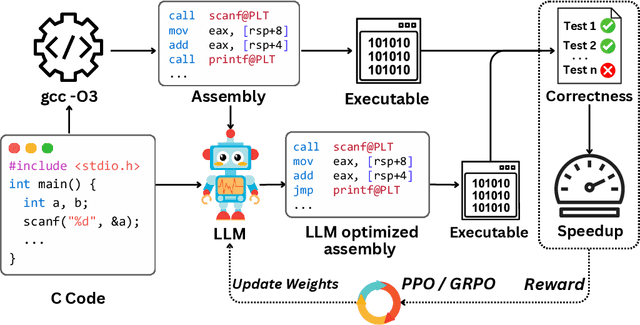
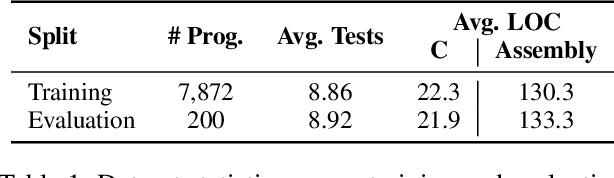
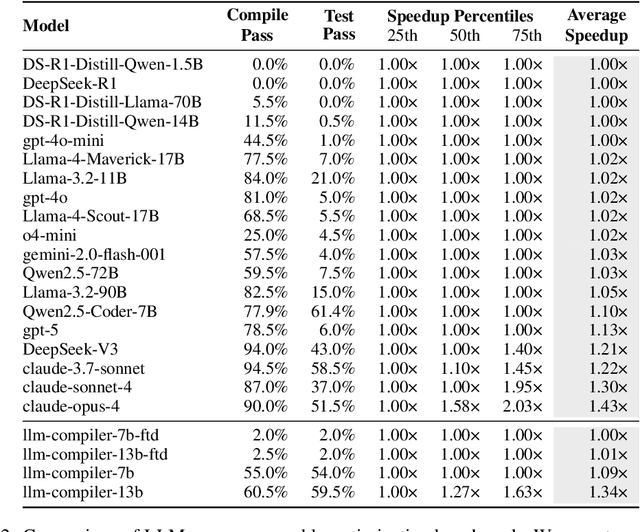

Large language models (LLMs) have demonstrated strong performance across a wide range of programming tasks, yet their potential for code optimization remains underexplored. This work investigates whether LLMs can optimize the performance of assembly code, where fine-grained control over execution enables improvements that are difficult to express in high-level languages. We present a reinforcement learning framework that trains LLMs using Proximal Policy Optimization (PPO), guided by a reward function that considers both functional correctness, validated through test cases, and execution performance relative to the industry-standard compiler gcc -O3. To support this study, we introduce a benchmark of 8,072 real-world programs. Our model, Qwen2.5-Coder-7B-PPO, achieves 96.0% test pass rates and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all 20 other models evaluated, including Claude-3.7-sonnet. These results indicate that reinforcement learning can unlock the potential of LLMs to serve as effective optimizers for assembly code performance.
VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Apr 22, 2025



Recent advances in Large Language Models (LLMs) have sparked growing interest in applying them to Electronic Design Automation (EDA) tasks, particularly Register Transfer Level (RTL) code generation. While several RTL datasets have been introduced, most focus on syntactic validity rather than functional validation with tests, leading to training examples that compile but may not implement the intended behavior. We present VERICODER, a model for RTL code generation fine-tuned on a dataset validated for functional correctness. This fine-tuning dataset is constructed using a novel methodology that combines unit test generation with feedback-directed refinement. Given a natural language specification and an initial RTL design, we prompt a teacher model (GPT-4o-mini) to generate unit tests and iteratively revise the RTL design based on its simulation results using the generated tests. If necessary, the teacher model also updates the tests to ensure they comply with the natural language specification. As a result of this process, every example in our dataset is functionally validated, consisting of a natural language description, an RTL implementation, and passing tests. Fine-tuned on this dataset of over 125,000 examples, VERICODER achieves state-of-the-art metrics in functional correctness on VerilogEval and RTLLM, with relative gains of up to 71.7% and 27.4% respectively. An ablation study further shows that models trained on our functionally validated dataset outperform those trained on functionally non-validated datasets, underscoring the importance of high-quality datasets in RTL code generation.