 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFlowOut: Dropout with Generative Flow Networks
Nov 07, 2022



Bayesian Inference offers principled tools to tackle many critical problems with modern neural networks such as poor calibration and generalization, and data inefficiency. However, scaling Bayesian inference to large architectures is challenging and requires restrictive approximations. Monte Carlo Dropout has been widely used as a relatively cheap way for approximate Inference and to estimate uncertainty with deep neural networks. Traditionally, the dropout mask is sampled independently from a fixed distribution. Recent works show that the dropout mask can be viewed as a latent variable, which can be inferred with variational inference. These methods face two important challenges: (a) the posterior distribution over masks can be highly multi-modal which can be difficult to approximate with standard variational inference and (b) it is not trivial to fully utilize sample-dependent information and correlation among dropout masks to improve posterior estimation. In this work, we propose GFlowOut to address these issues. GFlowOut leverages the recently proposed probabilistic framework of Generative Flow Networks (GFlowNets) to learn the posterior distribution over dropout masks. We empirically demonstrate that GFlowOut results in predictive distributions that generalize better to out-of-distribution data, and provide uncertainty estimates which lead to better performance in downstream tasks.
Discrete Factorial Representations as an Abstraction for Goal Conditioned Reinforcement Learning
Nov 01, 2022Goal-conditioned reinforcement learning (RL) is a promising direction for training agents that are capable of solving multiple tasks and reach a diverse set of objectives. How to \textit{specify} and \textit{ground} these goals in such a way that we can both reliably reach goals during training as well as generalize to new goals during evaluation remains an open area of research. Defining goals in the space of noisy and high-dimensional sensory inputs poses a challenge for training goal-conditioned agents, or even for generalization to novel goals. We propose to address this by learning factorial representations of goals and processing the resulting representation via a discretization bottleneck, for coarser goal specification, through an approach we call DGRL. We show that applying a discretizing bottleneck can improve performance in goal-conditioned RL setups, by experimentally evaluating this method on tasks ranging from maze environments to complex robotic navigation and manipulation. Additionally, we prove a theorem lower-bounding the expected return on out-of-distribution goals, while still allowing for specifying goals with expressive combinatorial structure.
Stateful active facilitator: Coordination and Environmental Heterogeneity in Cooperative Multi-Agent Reinforcement Learning
Oct 07, 2022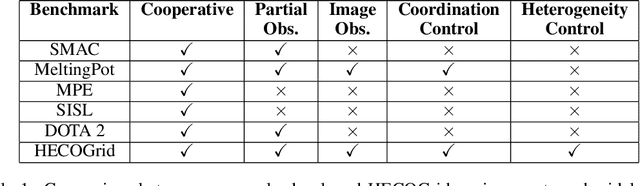

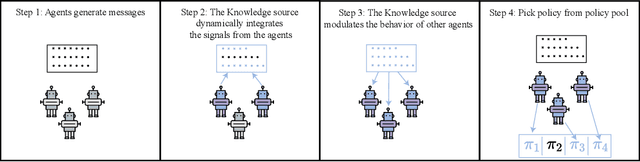
In cooperative multi-agent reinforcement learning, a team of agents works together to achieve a common goal. Different environments or tasks may require varying degrees of coordination among agents in order to achieve the goal in an optimal way. The nature of coordination will depend on properties of the environment -- its spatial layout, distribution of obstacles, dynamics, etc. We term this variation of properties within an environment as heterogeneity. Existing literature has not sufficiently addressed the fact that different environments may have different levels of heterogeneity. We formalize the notions of coordination level and heterogeneity level of an environment and present HECOGrid, a suite of multi-agent RL environments that facilitates empirical evaluation of different MARL approaches across different levels of coordination and environmental heterogeneity by providing a quantitative control over coordination and heterogeneity levels of the environment. Further, we propose a Centralized Training Decentralized Execution learning approach called Stateful Active Facilitator (SAF) that enables agents to work efficiently in high-coordination and high-heterogeneity environments through a differentiable and shared knowledge source used during training and dynamic selection from a shared pool of policies. We evaluate SAF and compare its performance against baselines IPPO and MAPPO on HECOGrid. Our results show that SAF consistently outperforms the baselines across different tasks and different heterogeneity and coordination levels.
Discrete Key-Value Bottleneck
Jul 22, 2022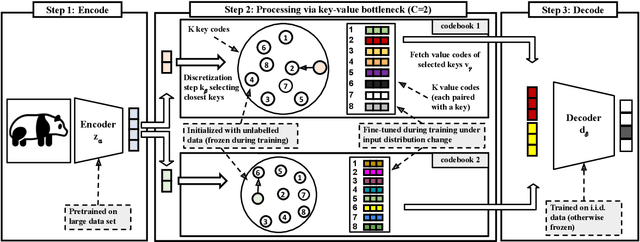
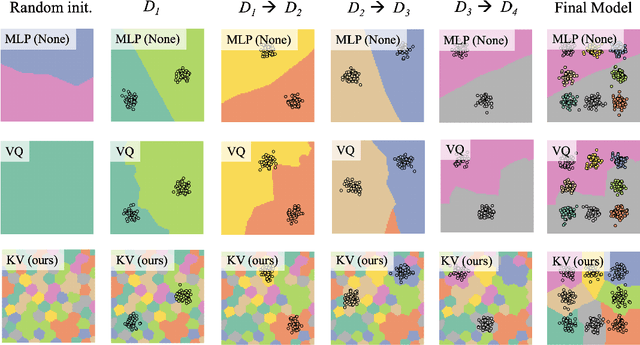

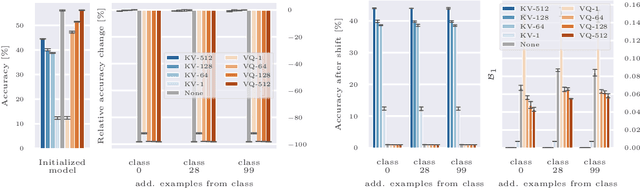
Deep neural networks perform well on prediction and classification tasks in the canonical setting where data streams are i.i.d., labeled data is abundant, and class labels are balanced. Challenges emerge with distribution shifts, including non-stationary or imbalanced data streams. One powerful approach that has addressed this challenge involves self-supervised pretraining of large encoders on volumes of unlabeled data, followed by task-specific tuning. Given a new task, updating the weights of these encoders is challenging as a large number of weights needs to be fine-tuned, and as a result, they forget information about the previous tasks. In the present work, we propose a model architecture to address this issue, building upon a discrete bottleneck containing pairs of separate and learnable (key, value) codes. In this setup, we follow the encode; process the representation via a discrete bottleneck; and decode paradigm, where the input is fed to the pretrained encoder, the output of the encoder is used to select the nearest keys, and the corresponding values are fed to the decoder to solve the current task. The model can only fetch and re-use a limited number of these (key, value) pairs during inference, enabling localized and context-dependent model updates. We theoretically investigate the ability of the proposed model to minimize the effect of the distribution shifts and show that such a discrete bottleneck with (key, value) pairs reduces the complexity of the hypothesis class. We empirically verified the proposed methods' benefits under challenging distribution shift scenarios across various benchmark datasets and show that the proposed model reduces the common vulnerability to non-i.i.d. and non-stationary training distributions compared to various other baselines.
On the Generalization and Adaption Performance of Causal Models
Jun 09, 2022

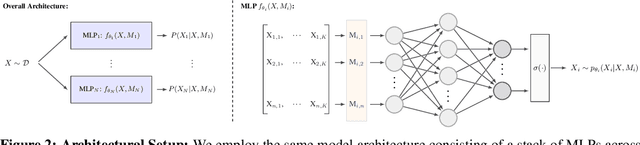

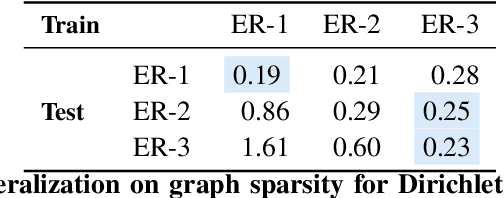
Learning models that offer robust out-of-distribution generalization and fast adaptation is a key challenge in modern machine learning. Modelling causal structure into neural networks holds the promise to accomplish robust zero and few-shot adaptation. Recent advances in differentiable causal discovery have proposed to factorize the data generating process into a set of modules, i.e. one module for the conditional distribution of every variable where only causal parents are used as predictors. Such a modular decomposition of knowledge enables adaptation to distributions shifts by only updating a subset of parameters. In this work, we systematically study the generalization and adaption performance of such modular neural causal models by comparing it to monolithic models and structured models where the set of predictors is not constrained to causal parents. Our analysis shows that the modular neural causal models outperform other models on both zero and few-shot adaptation in low data regimes and offer robust generalization. We also found that the effects are more significant for sparser graphs as compared to denser graphs.
Temporal Latent Bottleneck: Synthesis of Fast and Slow Processing Mechanisms in Sequence Learning
May 30, 2022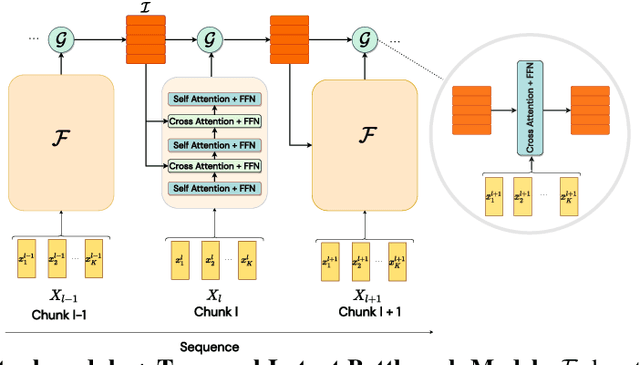
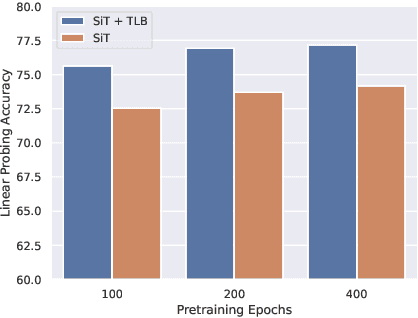
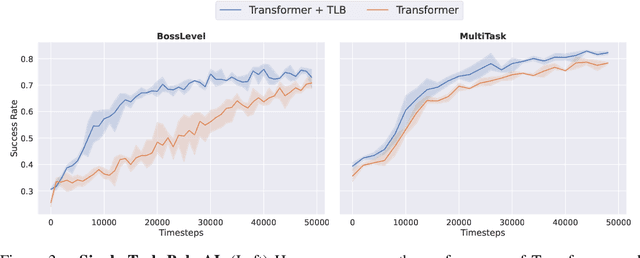
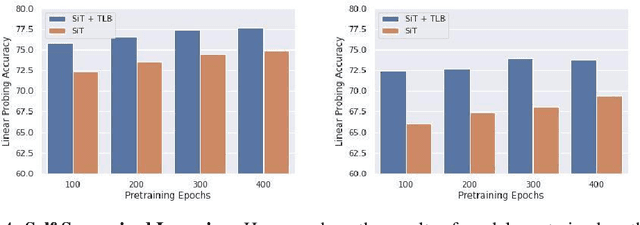
Recurrent neural networks have a strong inductive bias towards learning temporally compressed representations, as the entire history of a sequence is represented by a single vector. By contrast, Transformers have little inductive bias towards learning temporally compressed representations, as they allow for attention over all previously computed elements in a sequence. Having a more compressed representation of a sequence may be beneficial for generalization, as a high-level representation may be more easily re-used and re-purposed and will contain fewer irrelevant details. At the same time, excessive compression of representations comes at the cost of expressiveness. We propose a solution which divides computation into two streams. A slow stream that is recurrent in nature aims to learn a specialized and compressed representation, by forcing chunks of $K$ time steps into a single representation which is divided into multiple vectors. At the same time, a fast stream is parameterized as a Transformer to process chunks consisting of $K$ time-steps conditioned on the information in the slow-stream. In the proposed approach we hope to gain the expressiveness of the Transformer, while encouraging better compression and structuring of representations in the slow stream. We show the benefits of the proposed method in terms of improved sample efficiency and generalization performance as compared to various competitive baselines for visual perception and sequential decision making tasks.
Coordinating Policies Among Multiple Agents via an Intelligent Communication Channel
May 25, 2022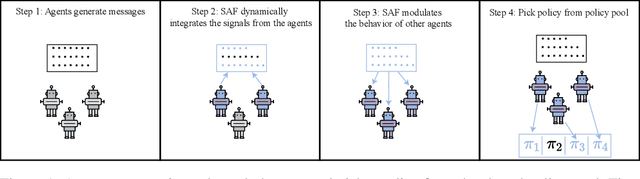

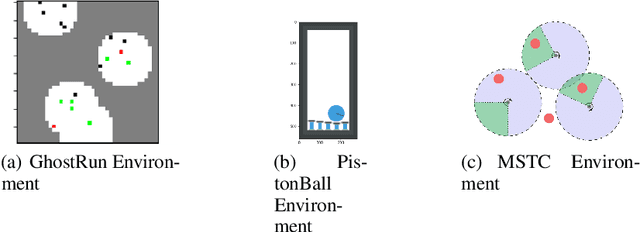

In Multi-Agent Reinforcement Learning (MARL), specialized channels are often introduced that allow agents to communicate directly with one another. In this paper, we propose an alternative approach whereby agents communicate through an intelligent facilitator that learns to sift through and interpret signals provided by all agents to improve the agents' collective performance. To ensure that this facilitator does not become a centralized controller, agents are incentivized to reduce their dependence on the messages it conveys, and the messages can only influence the selection of a policy from a fixed set, not instantaneous actions given the policy. We demonstrate the strength of this architecture over existing baselines on several cooperative MARL environments.
Learning to Induce Causal Structure
Apr 11, 2022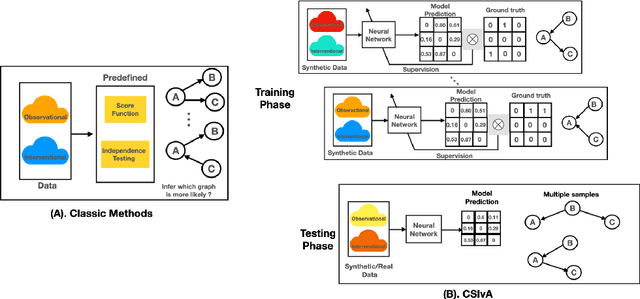
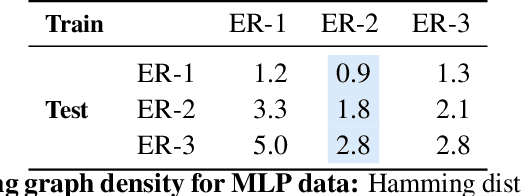
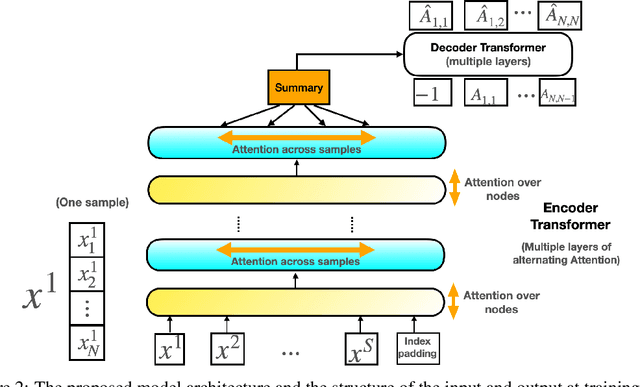
The fundamental challenge in causal induction is to infer the underlying graph structure given observational and/or interventional data. Most existing causal induction algorithms operate by generating candidate graphs and then evaluating them using either score-based methods (including continuous optimization) or independence tests. In this work, instead of proposing scoring function or independence tests, we treat the inference process as a black box and design a neural network architecture that learns the mapping from both observational and interventional data to graph structures via supervised training on synthetic graphs. We show that the proposed model generalizes not only to new synthetic graphs but also to naturalistic graphs.
Generating Fast and Slow: Scene Decomposition via Reconstruction
Mar 21, 2022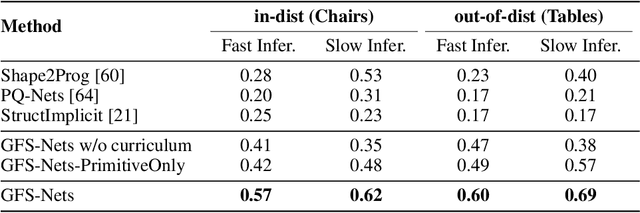
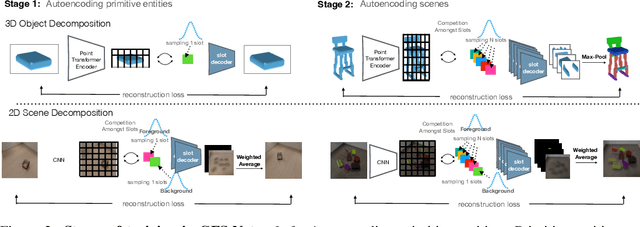
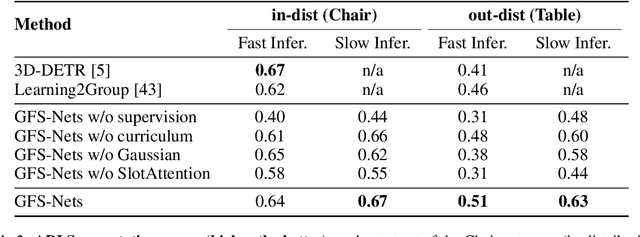
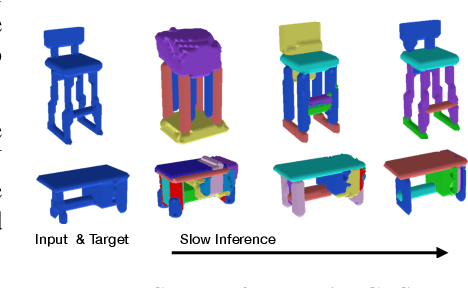
We consider the problem of segmenting scenes into constituent entities, i.e. underlying objects and their parts. Current supervised visual detectors though impressive within their training distribution, often fail to segment out-of-distribution scenes into their constituent entities. Recent slot-centric generative models break such dependence on supervision, by attempting to segment scenes into entities unsupervised, by reconstructing pixels. However, they have been restricted thus far to toy scenes as they suffer from a reconstruction-segmentation trade-off: as the entity bottleneck gets wider, reconstruction improves but then the segmentation collapses. We propose GFS-Nets (Generating Fast and Slow Networks) that alleviate this issue with two ingredients: i) curriculum training in the form of primitives, often missing from current generative models and, ii) test-time adaptation per scene through gradient descent on the reconstruction objective, what we call slow inference, missing from current feed-forward detectors. We show the proposed curriculum suffices to break the reconstruction-segmentation trade-off, and slow inference greatly improves segmentation in out-of-distribution scenes. We evaluate GFS-Nets in 3D and 2D scene segmentation benchmarks of PartNet, CLEVR, Room Diverse++, and show large ( 50%) performance improvements against SOTA supervised feed-forward detectors and unsupervised object discovery methods
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022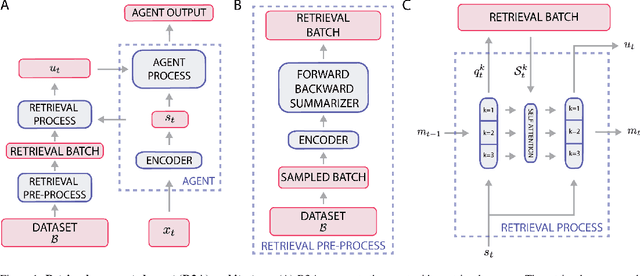

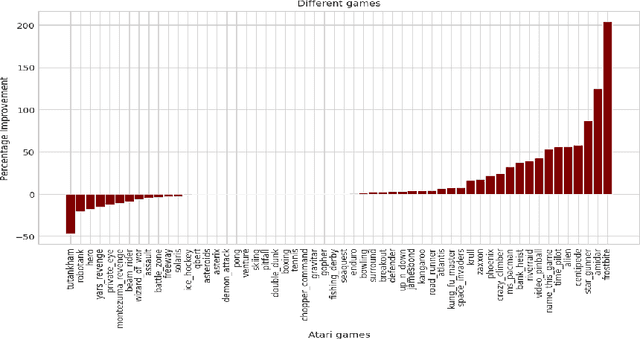
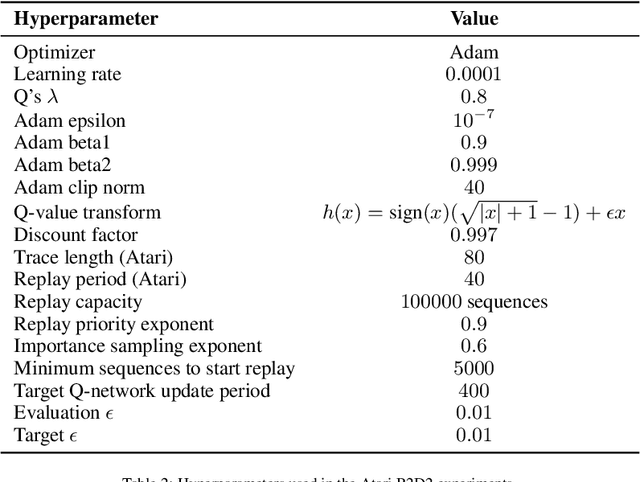
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.