 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023



We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers
May 11, 2023



We present Region-aware Open-vocabulary Vision Transformers (RO-ViT) - a contrastive image-text pretraining recipe to bridge the gap between image-level pretraining and open-vocabulary object detection. At the pretraining phase, we propose to randomly crop and resize regions of positional embeddings instead of using the whole image positional embeddings. This better matches the use of positional embeddings at region-level in the detection finetuning phase. In addition, we replace the common softmax cross entropy loss in contrastive learning with focal loss to better learn the informative yet difficult examples. Finally, we leverage recent advances in novel object proposals to improve open-vocabulary detection finetuning. We evaluate our full model on the LVIS and COCO open-vocabulary detection benchmarks and zero-shot transfer. RO-ViT achieves a state-of-the-art 32.1 $AP_r$ on LVIS, surpassing the best existing approach by +5.8 points in addition to competitive zero-shot transfer detection. Surprisingly, RO-ViT improves the image-level representation as well and achieves the state of the art on 9 out of 12 metrics on COCO and Flickr image-text retrieval benchmarks, outperforming competitive approaches with larger models.
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
Mar 30, 2023



The development of language models have moved from encoder-decoder to decoder-only designs. In addition, the common knowledge has it that the two most popular multimodal tasks, the generative and contrastive tasks, tend to conflict with one another, are hard to accommodate in one architecture, and further need complex adaptations for downstream tasks. We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder. We demonstrate that joint learning of these diverse objectives is simple, effective, and maximizes the weight-sharing of the model across these tasks. Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and video-language tasks. The model tackles a diverse range of tasks, while being modest in capacity. Our model achieves the state of the art on image-text and text-image retrieval, video question answering and open-vocabulary detection tasks, outperforming much larger and more extensively trained foundational models. It shows very competitive results on VQA and Video Captioning, especially considering its capacity. Ablations confirm the flexibility and advantages of our approach.
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
Dec 06, 2022We present a simple approach which can turn a ViT encoder into an efficient video model, which can seamlessly work with both image and video inputs. By sparsely sampling the inputs, the model is able to do training and inference from both inputs. The model is easily scalable and can be adapted to large-scale pre-trained ViTs without requiring full finetuning. The model achieves SOTA results and the code will be open-sourced.
F-VLM: Open-Vocabulary Object Detection upon Frozen Vision and Language Models
Sep 30, 2022
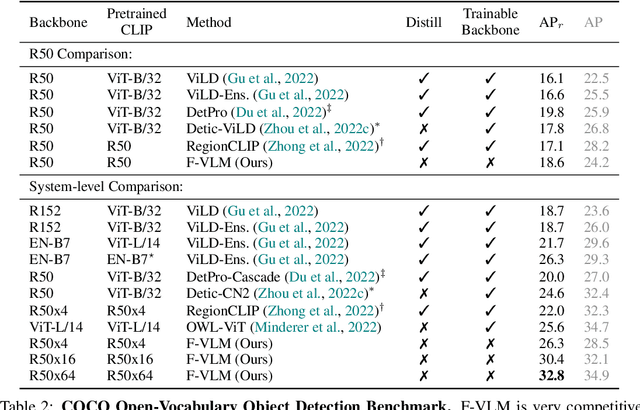
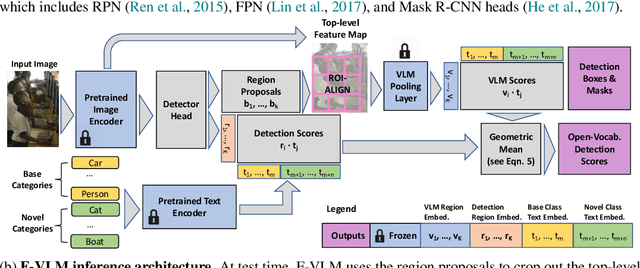
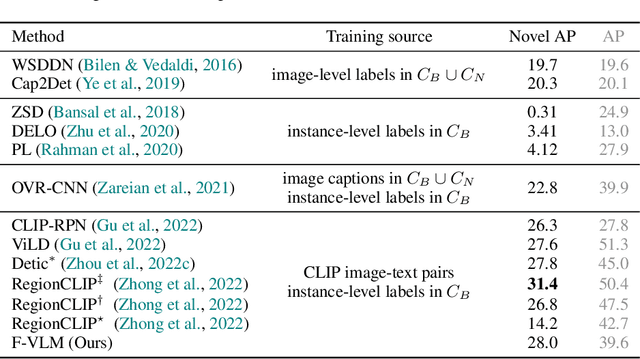
We present F-VLM, a simple open-vocabulary object detection method built upon Frozen Vision and Language Models. F-VLM simplifies the current multi-stage training pipeline by eliminating the need for knowledge distillation or detection-tailored pretraining. Surprisingly, we observe that a frozen VLM: 1) retains the locality-sensitive features necessary for detection, and 2) is a strong region classifier. We finetune only the detector head and combine the detector and VLM outputs for each region at inference time. F-VLM shows compelling scaling behavior and achieves +6.5 mask AP improvement over the previous state of the art on novel categories of LVIS open-vocabulary detection benchmark. In addition, we demonstrate very competitive results on COCO open-vocabulary detection benchmark and cross-dataset transfer detection, in addition to significant training speed-up and compute savings. Code will be released.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022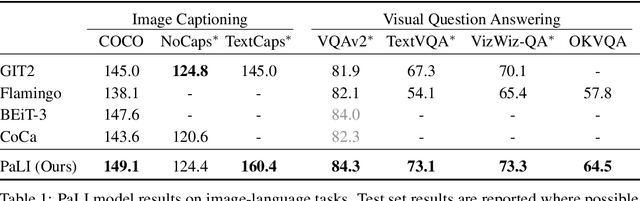

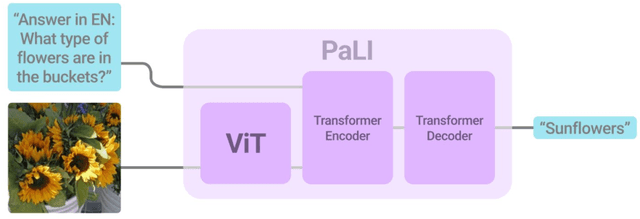

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
Pre-training image-language transformers for open-vocabulary tasks
Sep 09, 2022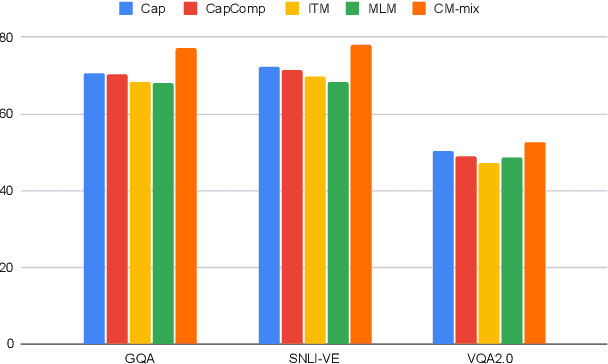
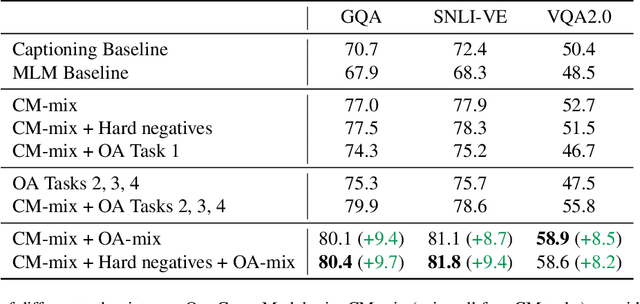
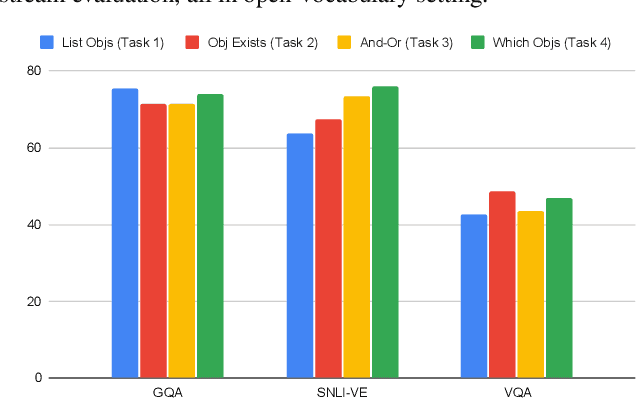

We present a pre-training approach for vision and language transformer models, which is based on a mixture of diverse tasks. We explore both the use of image-text captioning data in pre-training, which does not need additional supervision, as well as object-aware strategies to pre-train the model. We evaluate the method on a number of textgenerative vision+language tasks, such as Visual Question Answering, visual entailment and captioning, and demonstrate large gains over standard pre-training methods.
Video Question Answering with Iterative Video-Text Co-Tokenization
Aug 01, 2022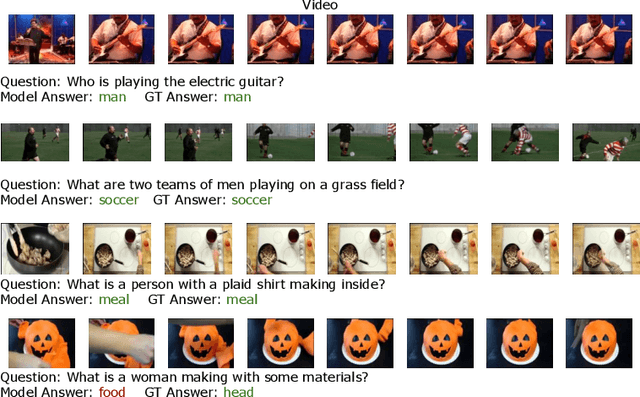
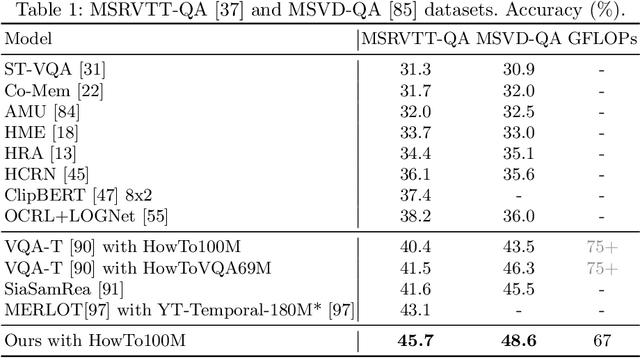
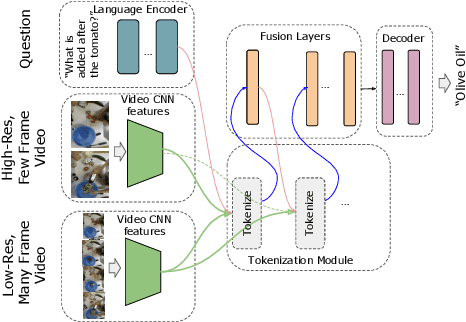

Video question answering is a challenging task that requires understanding jointly the language input, the visual information in individual video frames, as well as the temporal information about the events occurring in the video. In this paper, we propose a novel multi-stream video encoder for video question answering that uses multiple video inputs and a new video-text iterative co-tokenization approach to answer a variety of questions related to videos. We experimentally evaluate the model on several datasets, such as MSRVTT-QA, MSVD-QA, IVQA, outperforming the previous state-of-the-art by large margins. Simultaneously, our model reduces the required GFLOPs from 150-360 to only 67, producing a highly efficient video question answering model.
Mechanical Search on Shelves with Efficient Stacking and Destacking of Objects
Jul 05, 2022
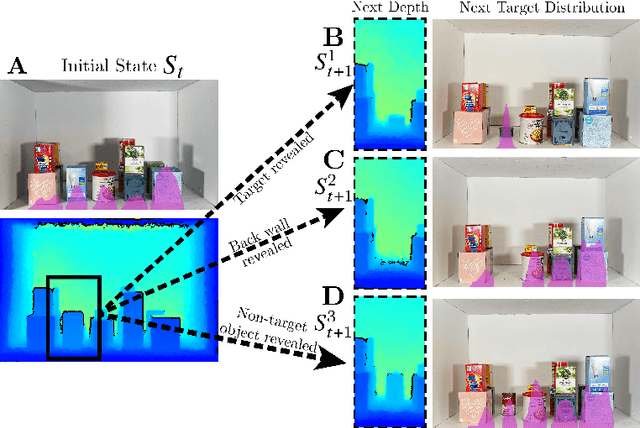
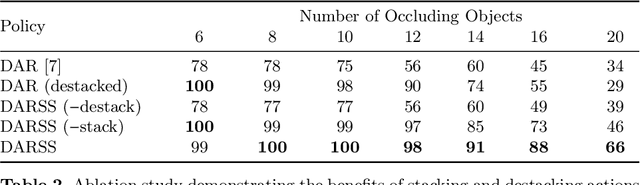
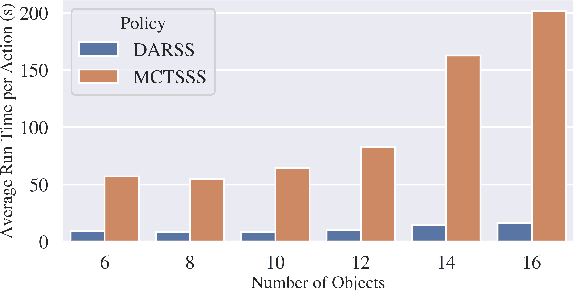
Stacking increases storage efficiency in shelves, but the lack of visibility and accessibility makes the mechanical search problem of revealing and extracting target objects difficult for robots. In this paper, we extend the lateral-access mechanical search problem to shelves with stacked items and introduce two novel policies -- Distribution Area Reduction for Stacked Scenes (DARSS) and Monte Carlo Tree Search for Stacked Scenes (MCTSSS) -- that use destacking and restacking actions. MCTSSS improves on prior lookahead policies by considering future states after each potential action. Experiments in 1200 simulated and 18 physical trials with a Fetch robot equipped with a blade and suction cup suggest that destacking and restacking actions can reveal the target object with 82--100% success in simulation and 66--100% in physical experiments, and are critical for searching densely packed shelves. In the simulation experiments, both policies outperform a baseline and achieve similar success rates but take more steps compared with an oracle policy that has full state information. In simulation and physical experiments, DARSS outperforms MCTSSS in median number of steps to reveal the target, but MCTSSS has a higher success rate in physical experiments, suggesting robustness to perception noise. See https://sites.google.com/berkeley.edu/stax-ray for supplementary material.
Answer-Me: Multi-Task Open-Vocabulary Visual Question Answering
May 02, 2022
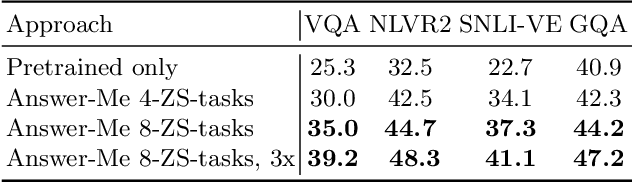
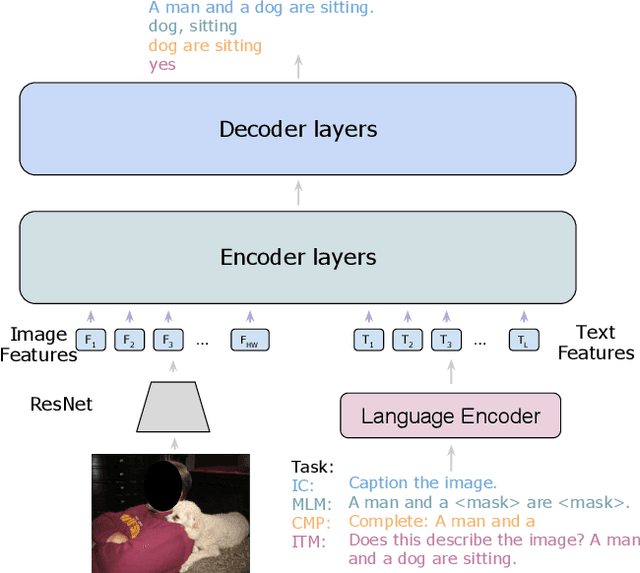
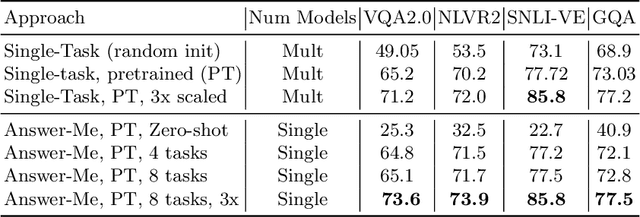
We present Answer-Me, a task-aware multi-task framework which unifies a variety of question answering tasks, such as, visual question answering, visual entailment, visual reasoning. In contrast to previous works using contrastive or generative captioning training, we propose a novel and simple recipe to pre-train a vision-language joint model, which is multi-task as well. The pre-training uses only noisy image captioning data, and is formulated to use the entire architecture end-to-end with both a strong language encoder and decoder. Our results show state-of-the-art performance, zero-shot generalization, robustness to forgetting, and competitive single-task results across a variety of question answering tasks. Our multi-task mixture training learns from tasks of various question intents and thus generalizes better, including on zero-shot vision-language tasks. We conduct experiments in the challenging multi-task and open-vocabulary settings and across a variety of datasets and tasks, such as VQA2.0, SNLI-VE, NLVR2, GQA, VizWiz. We observe that the proposed approach is able to generalize to unseen tasks and that more diverse mixtures lead to higher accuracy in both known and novel tasks.