 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Re-engineering Along the Ontological Continuum (extended version)
May 21, 2026Knowledge graphs have become the primary vehicle for data integration and are critical to the success of modern AI, but the diversity of KG modelling practices, from lightweight vocabularies to richly axiomatised ontologies, makes integration and reuse expensive and brittle. This challenge is particularly acute in neuro-symbolic AI, where bridging neural and symbolic components depends on the ability to reengineer KGs to fit new requirements; GenAI now offers unprecedented automation capability, but without a principled understanding of the KG space, such automation remains conceptually ungrounded. We introduce the ontological continuum as that missing conceptualisation, a theoretical construct a theoretical construct whose characterisation framework is defined by two orthogonal distinctions: semantics vs pragmatics, and properties vs affordances; together these define a vocabulary to describe, compare, navigate, and transform KGs across the full range of modelling practices. The methodological stance is empirical: rather than prescribing how KGs should be modelled, the continuum aims to define a theory of the existent, derived from observation of real-world KG engineering practices and whose structure can be made formally explicit, for example, through Formal Concept Analysis (FCA). We ground the vision through a case study on provenance knowledge, showing how a single concern manifests differently across the continuum. We articulate five open research challenges and invite the community to develop the ontological continuum as a shared research agenda.
Discoverable Agent Knowledge -- A Formal Framework for Agentic KG Affordances (Extended Version)
May 18, 2026Two decades ago, the Semantic Web Services community was asked how agents with different ontological commitments could discover, compose, and invoke web services coherently. The response was OWL-S and WSMO: formally grounded capability descriptions specifying what a service could do, what the agent must already know for invocation to be epistemically sound, and how ontological mismatches could be formally bridged. Current Knowledge Graph (KG) metadata standards such as VoID and DCAT describe what a KG contains yet say nothing about what a specific agent can prove from it, what closure assumptions govern empty results, or whether the agent's task vocabulary is grounded in the schema. Furthermore, in deployed KGs the governing schema DL and the operative entailment regime can diverge: an epistemic failure mode invisible to current metadata. We revisit and extend these insights for the KG setting with a four-dimensional formal framework from which we derive the Agentic Affordance Profile (AAP): a semantic layer above VoID and DCAT enabling principled KG selection, composition, and failure diagnosis at agent planning time. A five-point research agenda identifies the formal, computational, and engineering work needed to realise AAP-based affordance matching at scale.
The AnIML Ontology: Enabling Semantic Interoperability for Large-Scale Experimental Data in Interconnected Scientific Labs
Apr 02, 2026Achieving semantic interoperability across heterogeneous experimental data systems remains a major barrier to data-driven scientific discovery. The Analytical Information Markup Language (AnIML), a flexible XML-based standard for analytical chemistry and biology, is increasingly used in industrial R&D labs for managing and exchanging experimental data. However, the expressivity of the XML schema permits divergent interpretations across stakeholders, introducing inconsistencies that undermine the interoperability the AnIML schema was designed to support. In this paper, we present the AnIML Ontology, an OWL 2 ontology that formalises the semantics of AnIML and aligns it with the Allotrope Data Format to support future cross-system and cross-lab interoperability. The ontology was developed using an expert-in-the-loop approach combining LLM-assisted requirement elicitation with collaborative ontology engineering. We validate the ontology through a multi-layered approach: data-driven transformation of real-world AnIML files into knowledge graphs, competency question verification via SPARQL, and a novel validation protocol based on adversarial negative competency questions mapped to established ontological anti-patterns and enforced via SHACL constraints.
IDEA2: Expert-in-the-loop competency question elicitation for collaborative ontology engineering
Apr 01, 2026Competency question (CQ) elicitation represents a critical but resource-intensive bottleneck in ontology engineering. This foundational phase is often hampered by the communication gap between domain experts, who possess the necessary knowledge, and ontology engineers, who formalise it. This paper introduces IDEA2, a novel, semi-automated workflow that integrates Large Language Models (LLMs) within a collaborative, expert-in-the-loop process to address this challenge. The methodology is characterised by a core iterative loop: an initial LLM-based extraction of CQs from requirement documents, a co-creational review and feedback phase by domain experts on an accessible collaborative platform, and an iterative, feedback-driven reformulation of rejected CQs by an LLM until consensus is achieved. To ensure transparency and reproducibility, the entire lifecycle of each CQ is tracked using a provenance model that captures the full lineage of edits, anonymised feedback, and generation parameters. The workflow was validated in 2 real-world scenarios (scientific data, cultural heritage), demonstrating that IDEA2 can accelerate the requirements engineering process, improve the acceptance and relevance of the resulting CQs, and exhibit high usability and effectiveness among domain experts. We release all code and experiments at https://github.com/KE-UniLiv/IDEA2
Evaluating the Fitness of Ontologies for the Task of Question Generation
Apr 08, 2025Ontology-based question generation is an important application of semantic-aware systems that enables the creation of large question banks for diverse learning environments. The effectiveness of these systems, both in terms of the calibre and cognitive difficulty of the resulting questions, depends heavily on the quality and modelling approach of the underlying ontologies, making it crucial to assess their fitness for this task. To date, there has been no comprehensive investigation into the specific ontology aspects or characteristics that affect the question generation process. Therefore, this paper proposes a set of requirements and task-specific metrics for evaluating the fitness of ontologies for question generation tasks in pedagogical settings. Using the ROMEO methodology, a structured framework for deriving task-specific metrics, an expert-based approach is employed to assess the performance of various ontologies in Automatic Question Generation (AQG) tasks, which is then evaluated over a set of ontologies. Our results demonstrate that ontology characteristics significantly impact the effectiveness of question generation, with different ontologies exhibiting varying performance levels. This highlights the importance of assessing ontology quality with respect to AQG tasks.
A Pattern to Align Them All: Integrating Different Modalities to Define Multi-Modal Entities
Oct 17, 2024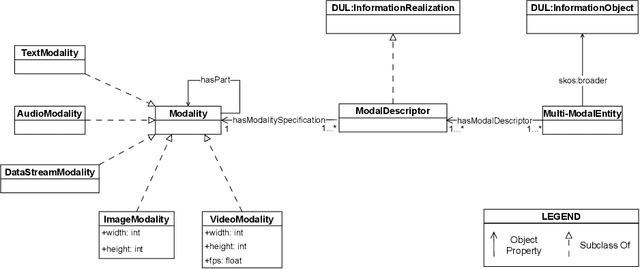

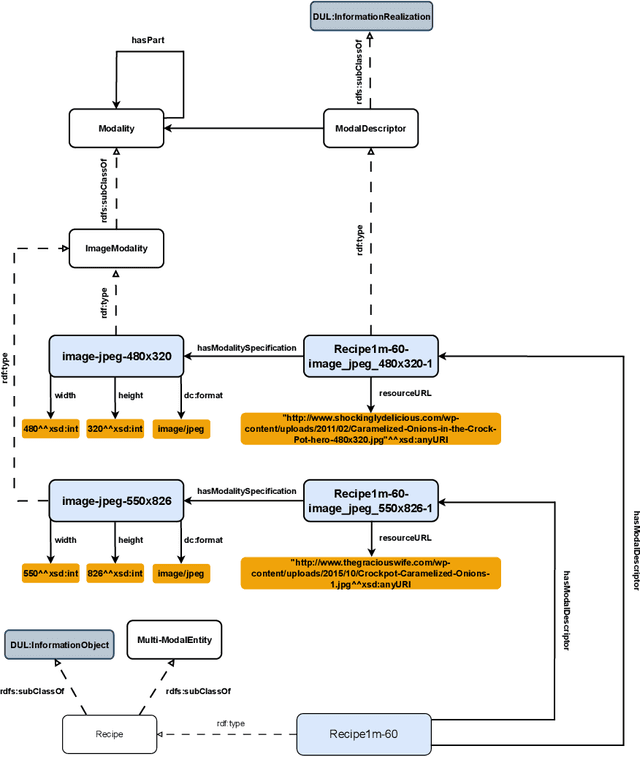
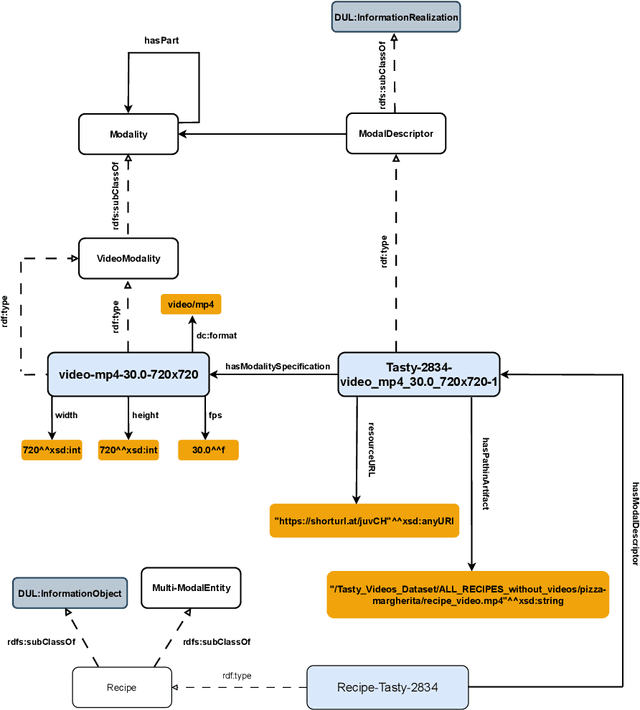
The ability to reason with and integrate different sensory inputs is the foundation underpinning human intelligence and it is the reason for the growing interest in modelling multi-modal information within Knowledge Graphs. Multi-Modal Knowledge Graphs extend traditional Knowledge Graphs by associating an entity with its possible modal representations, including text, images, audio, and videos, all of which are used to convey the semantics of the entity. Despite the increasing attention that Multi-Modal Knowledge Graphs have received, there is a lack of consensus about the definitions and modelling of modalities, whose definition is often determined by application domains. In this paper, we propose a novel ontology design pattern that captures the separation of concerns between an entity (and the information it conveys), whose semantics can have different manifestations across different media, and its realisation in terms of a physical information entity. By introducing this abstract model, we aim to facilitate the harmonisation and integration of different existing multi-modal ontologies which is crucial for many intelligent applications across different domains spanning from medicine to digital humanities.
An Experiment in Retrofitting Competency Questions for Existing Ontologies
Nov 09, 2023



Competency Questions (CQs) are a form of ontology functional requirements expressed as natural language questions. Inspecting CQs together with the axioms in an ontology provides critical insights into the intended scope and applicability of the ontology. CQs also underpin a number of tasks in the development of ontologies e.g. ontology reuse, ontology testing, requirement specification, and the definition of patterns that implement such requirements. Although CQs are integral to the majority of ontology engineering methodologies, the practice of publishing CQs alongside the ontological artefacts is not widely observed by the community. In this context, we present an experiment in retrofitting CQs from existing ontologies. We propose RETROFIT-CQs, a method to extract candidate CQs directly from ontologies using Generative AI. In the paper we present the pipeline that facilitates the extraction of CQs by leveraging Large Language Models (LLMs) and we discuss its application to a number of existing ontologies.
Knowledge Graphs for the Life Sciences: Recent Developments, Challenges and Opportunities
Oct 06, 2023
The term life sciences refers to the disciplines that study living organisms and life processes, and include chemistry, biology, medicine, and a range of other related disciplines. Research efforts in life sciences are heavily data-driven, as they produce and consume vast amounts of scientific data, much of which is intrinsically relational and graph-structured. The volume of data and the complexity of scientific concepts and relations referred to therein promote the application of advanced knowledge-driven technologies for managing and interpreting data, with the ultimate aim to advance scientific discovery. In this survey and position paper, we discuss recent developments and advances in the use of graph-based technologies in life sciences and set out a vision for how these technologies will impact these fields into the future. We focus on three broad topics: the construction and management of Knowledge Graphs (KGs), the use of KGs and associated technologies in the discovery of new knowledge, and the use of KGs in artificial intelligence applications to support explanations (explainable AI). We select a few exemplary use cases for each topic, discuss the challenges and open research questions within these topics, and conclude with a perspective and outlook that summarizes the overarching challenges and their potential solutions as a guide for future research.
OntoMerger: An Ontology Integration Library for Deduplicating and Connecting Knowledge Graph Nodes
Jun 05, 2022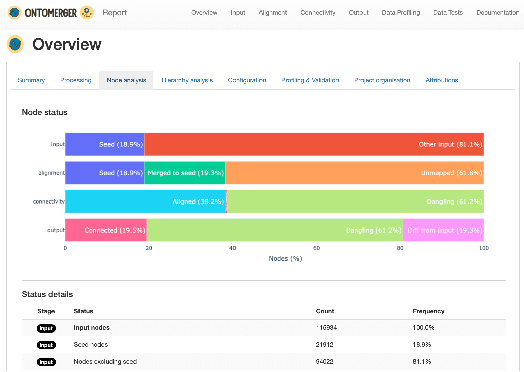

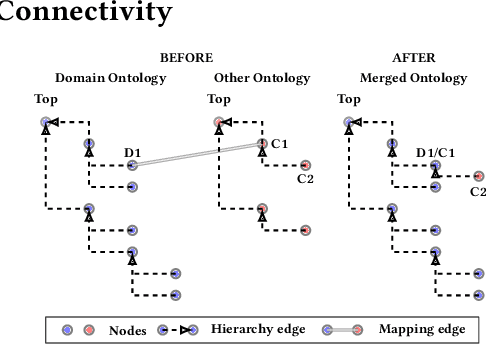

Duplication of nodes is a common problem encountered when building knowledge graphs (KGs) from heterogeneous datasets, where it is crucial to be able to merge nodes having the same meaning. OntoMerger is a Python ontology integration library whose functionality is to deduplicate KG nodes. Our approach takes a set of KG nodes, mappings and disconnected hierarchies and generates a set of merged nodes together with a connected hierarchy. In addition, the library provides analytic and data testing functionalities that can be used to fine-tune the inputs, further reducing duplication, and to increase connectivity of the output graph. OntoMerger can be applied to a wide variety of ontologies and KGs. In this paper we introduce OntoMerger and illustrate its functionality on a real-world biomedical KG.