 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXanatomy: Anatomy-Aware Vision-Language Modeling for Chest Radiographs
Jun 07, 2026Vision-language models (VLMs) pretrained on large-scale image-text pairs demonstrate strong image-level understanding, but are primarily optimized for global alignment and do not explicitly encode fine-grained anatomical structure, limiting their suitability for spatially precise tasks such as segmentation. We introduce CheXanatomy, a framework that integrates explicit anatomical knowledge into a pretrained VLM through autoregressive token-space supervision. Instead of adding task-specific decoder heads, the model is trained to generate anatomical segmentation masks via next-token prediction. To enable scalable supervision, we synthesize realistic chest radiographs from CT volumes and forward-project CT segmentation labels to obtain anatomically consistent 2D masks. We evaluate the approach on synthetic and real chest radiographs against a U-Net baseline, including ablations on model scale, input resolution, and vision encoder fine-tuning. Autoregressive anatomical supervision achieves performance comparable to specialized convolutional models in-distribution and demonstrates improved geometric robustness under domain shift to real CXR data. In addition, anatomy-pretrained models exhibit improved sample efficiency when adapting to novel localization tasks under limited supervision. Larger models and higher input image resolution improve performance, while vision encoder fine-tuning has limited effect. These results show that embedding anatomical structure directly into the generative objective promotes spatially grounded representations and supports anatomy-aware medical vision-language modeling.
Activation Matters: Test-time Activated Negative Labels for OOD Detection with Vision-Language Models
Mar 26, 2026Out-of-distribution (OOD) detection aims to identify samples that deviate from in-distribution (ID). One popular pipeline addresses this by introducing negative labels distant from ID classes and detecting OOD based on their distance to these labels. However, such labels may present poor activation on OOD samples, failing to capture the OOD characteristics. To address this, we propose \underline{T}est-time \underline{A}ctivated \underline{N}egative \underline{L}abels (TANL) by dynamically evaluating activation levels across the corpus dataset and mining candidate labels with high activation responses during the testing process. Specifically, TANL identifies high-confidence test images online and accumulates their assignment probabilities over the corpus to construct a label activation metric. Such a metric leverages historical test samples to adaptively align with the test distribution, enabling the selection of distribution-adaptive activated negative labels. By further exploring the activation information within the current testing batch, we introduce a more fine-grained, batch-adaptive variant. To fully utilize label activation knowledge, we propose an activation-aware score function that emphasizes negative labels with stronger activations, boosting performance and enhancing its robustness to the label number. Our TANL is training-free, test-efficient, and grounded in theoretical justification. Experiments on diverse backbones and wide task settings validate its effectiveness. Notably, on the large-scale ImageNet benchmark, TANL significantly reduces the FPR95 from 17.5\% to 9.8\%. Codes are available at \href{https://github.com/YBZh/OpenOOD-VLM}{YBZh/OpenOOD-VLM}.
Learning Generalizable 3D Medical Image Representations from Mask-Guided Self-Supervision
Mar 14, 2026Foundation models have transformed vision and language by learning general-purpose representations from large-scale unlabeled data, yet 3D medical imaging lacks analogous approaches. Existing self-supervised methods rely on low-level reconstruction or contrastive objectives that fail to capture the anatomical semantics critical for medical image analysis, limiting transfer to downstream tasks. We present MASS (MAsk-guided Self-Supervised learning), which treats in-context segmentation as the pretext task for learning general-purpose medical imaging representations. MASS's key insight is that automatically generated class-agnostic masks provide sufficient structural supervision for learning semantically rich representations. By training on thousands of diverse mask proposals spanning anatomical structures and pathological findings, MASS learns what semantically defines medical structures: the holistic combination of appearance, shape, spatial context, and anatomical relationships. We demonstrate effectiveness across data regimes: from small-scale pretraining on individual datasets (20-200 scans) to large-scale multi-modal pretraining on 5K CT, MRI, and PET volumes, all without annotations. MASS demonstrates: (i) few-shot segmentation on novel structures, (ii) matching full supervision with only 20-40\% labeled data while outperforming self-supervised baselines by over 20 in Dice score in low-data regimes, and (iii) frozen-encoder classification on unseen pathologies that matches full supervised training with thousands of samples. Mask-guided self-supervised pretraining captures broadly generalizable knowledge, opening a path toward 3D medical imaging foundation models without expert annotations. Code is available: https://github.com/Stanford-AIMI/MASS.
Attention Head Entropy of LLMs Predicts Answer Correctness
Feb 14, 2026Large language models (LLMs) often generate plausible yet incorrect answers, posing risks in safety-critical settings such as medicine. Human evaluation is expensive, and LLM-as-judge approaches risk introducing hidden errors. Recent white-box methods detect contextual hallucinations using model internals, focusing on the localization of the attention mass, but two questions remain open: do these approaches extend to predicting answer correctness, and do they generalize out-of-domains? We introduce Head Entropy, a method that predicts answer correctness from attention entropy patterns, specifically measuring the spread of the attention mass. Using sparse logistic regression on per-head 2-Renyi entropies, Head Entropy matches or exceeds baselines in-distribution and generalizes substantially better on out-of-domains, it outperforms the closest baseline on average by +8.5% AUROC. We further show that attention patterns over the question/context alone, before answer generation, already carry predictive signal using Head Entropy with on average +17.7% AUROC over the closest baseline. We evaluate across 5 instruction-tuned LLMs and 3 QA datasets spanning general knowledge, multi-hop reasoning, and medicine.
RadDiff: Describing Differences in Radiology Image Sets with Natural Language
Jan 07, 2026Understanding how two radiology image sets differ is critical for generating clinical insights and for interpreting medical AI systems. We introduce RadDiff, a multimodal agentic system that performs radiologist-style comparative reasoning to describe clinically meaningful differences between paired radiology studies. RadDiff builds on a proposer-ranker framework from VisDiff, and incorporates four innovations inspired by real diagnostic workflows: (1) medical knowledge injection through domain-adapted vision-language models; (2) multimodal reasoning that integrates images with their clinical reports; (3) iterative hypothesis refinement across multiple reasoning rounds; and (4) targeted visual search that localizes and zooms in on salient regions to capture subtle findings. To evaluate RadDiff, we construct RadDiffBench, a challenging benchmark comprising 57 expert-validated radiology study pairs with ground-truth difference descriptions. On RadDiffBench, RadDiff achieves 47% accuracy, and 50% accuracy when guided by ground-truth reports, significantly outperforming the general-domain VisDiff baseline. We further demonstrate RadDiff's versatility across diverse clinical tasks, including COVID-19 phenotype comparison, racial subgroup analysis, and discovery of survival-related imaging features. Together, RadDiff and RadDiffBench provide the first method-and-benchmark foundation for systematically uncovering meaningful differences in radiological data.
Improving the Performance of Radiology Report De-identification with Large-Scale Training and Benchmarking Against Cloud Vendor Methods
Nov 06, 2025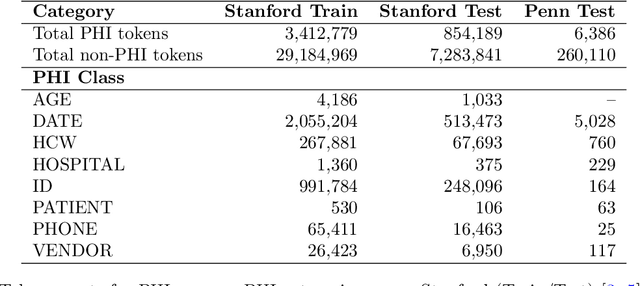

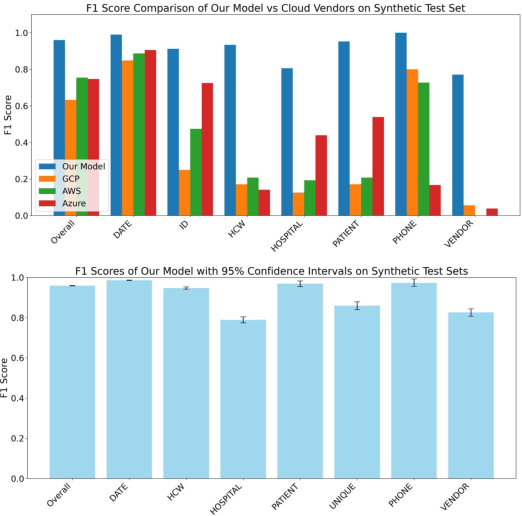
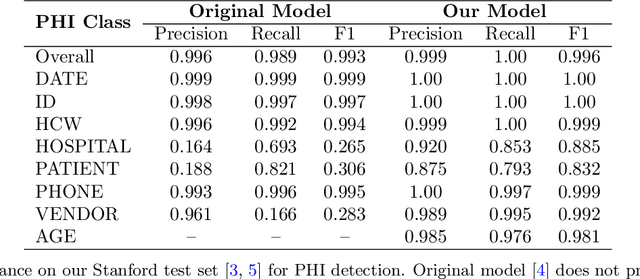
Objective: To enhance automated de-identification of radiology reports by scaling transformer-based models through extensive training datasets and benchmarking performance against commercial cloud vendor systems for protected health information (PHI) detection. Materials and Methods: In this retrospective study, we built upon a state-of-the-art, transformer-based, PHI de-identification pipeline by fine-tuning on two large annotated radiology corpora from Stanford University, encompassing chest X-ray, chest CT, abdomen/pelvis CT, and brain MR reports and introducing an additional PHI category (AGE) into the architecture. Model performance was evaluated on test sets from Stanford and the University of Pennsylvania (Penn) for token-level PHI detection. We further assessed (1) the stability of synthetic PHI generation using a "hide-in-plain-sight" method and (2) performance against commercial systems. Precision, recall, and F1 scores were computed across all PHI categories. Results: Our model achieved overall F1 scores of 0.973 on the Penn dataset and 0.996 on the Stanford dataset, outperforming or maintaining the previous state-of-the-art model performance. Synthetic PHI evaluation showed consistent detectability (overall F1: 0.959 [0.958-0.960]) across 50 independently de-identified Penn datasets. Our model outperformed all vendor systems on synthetic Penn reports (overall F1: 0.960 vs. 0.632-0.754). Discussion: Large-scale, multimodal training improved cross-institutional generalization and robustness. Synthetic PHI generation preserved data utility while ensuring privacy. Conclusion: A transformer-based de-identification model trained on diverse radiology datasets outperforms prior academic and commercial systems in PHI detection and establishes a new benchmark for secure clinical text processing.
Automated Structured Radiology Report Generation
May 30, 2025Automated radiology report generation from chest X-ray (CXR) images has the potential to improve clinical efficiency and reduce radiologists' workload. However, most datasets, including the publicly available MIMIC-CXR and CheXpert Plus, consist entirely of free-form reports, which are inherently variable and unstructured. This variability poses challenges for both generation and evaluation: existing models struggle to produce consistent, clinically meaningful reports, and standard evaluation metrics fail to capture the nuances of radiological interpretation. To address this, we introduce Structured Radiology Report Generation (SRRG), a new task that reformulates free-text radiology reports into a standardized format, ensuring clarity, consistency, and structured clinical reporting. We create a novel dataset by restructuring reports using large language models (LLMs) following strict structured reporting desiderata. Additionally, we introduce SRR-BERT, a fine-grained disease classification model trained on 55 labels, enabling more precise and clinically informed evaluation of structured reports. To assess report quality, we propose F1-SRR-BERT, a metric that leverages SRR-BERT's hierarchical disease taxonomy to bridge the gap between free-text variability and structured clinical reporting. We validate our dataset through a reader study conducted by five board-certified radiologists and extensive benchmarking experiments.
MedVAE: Efficient Automated Interpretation of Medical Images with Large-Scale Generalizable Autoencoders
Feb 20, 2025



Medical images are acquired at high resolutions with large fields of view in order to capture fine-grained features necessary for clinical decision-making. Consequently, training deep learning models on medical images can incur large computational costs. In this work, we address the challenge of downsizing medical images in order to improve downstream computational efficiency while preserving clinically-relevant features. We introduce MedVAE, a family of six large-scale 2D and 3D autoencoders capable of encoding medical images as downsized latent representations and decoding latent representations back to high-resolution images. We train MedVAE autoencoders using a novel two-stage training approach with 1,052,730 medical images. Across diverse tasks obtained from 20 medical image datasets, we demonstrate that (1) utilizing MedVAE latent representations in place of high-resolution images when training downstream models can lead to efficiency benefits (up to 70x improvement in throughput) while simultaneously preserving clinically-relevant features and (2) MedVAE can decode latent representations back to high-resolution images with high fidelity. Our work demonstrates that large-scale, generalizable autoencoders can help address critical efficiency challenges in the medical domain. Our code is available at https://github.com/StanfordMIMI/MedVAE.
Best Practices for Large Language Models in Radiology
Dec 02, 2024



At the heart of radiological practice is the challenge of integrating complex imaging data with clinical information to produce actionable insights. Nuanced application of language is key for various activities, including managing requests, describing and interpreting imaging findings in the context of clinical data, and concisely documenting and communicating the outcomes. The emergence of large language models (LLMs) offers an opportunity to improve the management and interpretation of the vast data in radiology. Despite being primarily general-purpose, these advanced computational models demonstrate impressive capabilities in specialized language-related tasks, even without specific training. Unlocking the potential of LLMs for radiology requires basic understanding of their foundations and a strategic approach to navigate their idiosyncrasies. This review, drawing from practical radiology and machine learning expertise and recent literature, provides readers insight into the potential of LLMs in radiology. It examines best practices that have so far stood the test of time in the rapidly evolving landscape of LLMs. This includes practical advice for optimizing LLM characteristics for radiology practices along with limitations, effective prompting, and fine-tuning strategies.
Foundation Models in Radiology: What, How, When, Why and Why Not
Nov 27, 2024



Recent advances in artificial intelligence have witnessed the emergence of large-scale deep learning models capable of interpreting and generating both textual and imaging data. Such models, typically referred to as foundation models, are trained on extensive corpora of unlabeled data and demonstrate high performance across various tasks. Foundation models have recently received extensive attention from academic, industry, and regulatory bodies. Given the potentially transformative impact that foundation models can have on the field of radiology, this review aims to establish a standardized terminology concerning foundation models, with a specific focus on the requirements of training data, model training paradigms, model capabilities, and evaluation strategies. We further outline potential pathways to facilitate the training of radiology-specific foundation models, with a critical emphasis on elucidating both the benefits and challenges associated with such models. Overall, we envision that this review can unify technical advances and clinical needs in the training of foundation models for radiology in a safe and responsible manner, for ultimately benefiting patients, providers, and radiologists.