 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Self-Verify Makes Language Models Better Reasoners
Feb 07, 2026Recent large language models (LLMs) achieve strong performance in generating promising reasoning paths for complex tasks. However, despite powerful generation ability, LLMs remain weak at verifying their own answers, revealing a persistent capability asymmetry between generation and self-verification. In this work, we conduct an in-depth investigation of this asymmetry throughout training evolution and show that, even on the same task, improving generation does not lead to corresponding improvements in self-verification. Interestingly, we find that the reverse direction of this asymmetry behaves differently: learning to self-verify can effectively improve generation performance, achieving accuracy comparable to standard generation training while yielding more efficient and effective reasoning traces. Building on this observation, we further explore integrating self-verification into generation training by formulating a multi-task reinforcement learning framework, where generation and self-verification are optimized as two independent but complementary objectives. Extensive experiments across benchmarks and models demonstrate performance gains over generation-only training in both generation and verification capabilities.
Transport and Merge: Cross-Architecture Merging for Large Language Models
Feb 05, 2026Large language models (LLMs) achieve strong capabilities by scaling model capacity and training data, yet many real-world deployments rely on smaller models trained or adapted from low-resource data. This gap motivates the need for mechanisms to transfer knowledge from large, high-resource models to smaller, low-resource targets. While model merging provides an effective transfer mechanism, most existing approaches assume architecture-compatible models and therefore cannot directly transfer knowledge from large high-resource LLMs to heterogeneous low-resource targets. In this work, we propose a cross-architecture merging framework based on optimal transport (OT) that aligns activations to infer cross-neuron correspondences between heterogeneous models. The resulting transport plans are then used to guide direct weight-space fusion, enabling effective high-resource to low-resource transfer using only a small set of inputs. Extensive experiments across low-resource languages and specialized domains demonstrate consistent improvements over target models.
Risky-Bench: Probing Agentic Safety Risks under Real-World Deployment
Feb 03, 2026Large Language Models (LLMs) are increasingly deployed as agents that operate in real-world environments, introducing safety risks beyond linguistic harm. Existing agent safety evaluations rely on risk-oriented tasks tailored to specific agent settings, resulting in limited coverage of safety risk space and failing to assess agent safety behavior during long-horizon, interactive task execution in complex real-world deployments. Moreover, their specialization to particular agent settings limits adaptability across diverse agent configurations. To address these limitations, we propose Risky-Bench, a framework that enables systematic agent safety evaluation grounded in real-world deployment. Risky-Bench organizes evaluation around domain-agnostic safety principles to derive context-aware safety rubrics that delineate safety space, and systematically evaluates safety risks across this space through realistic task execution under varying threat assumptions. When applied to life-assist agent settings, Risky-Bench uncovers substantial safety risks in state-of-the-art agents under realistic execution conditions. Moreover, as a well-structured evaluation pipeline, Risky-Bench is not confined to life-assist scenarios and can be adapted to other deployment settings to construct environment-specific safety evaluations, providing an extensible methodology for agent safety assessment.
Self-Guard: Defending Large Reasoning Models via enhanced self-reflection
Jan 31, 2026The emergence of Large Reasoning Models (LRMs) introduces a new paradigm of explicit reasoning, enabling remarkable advances yet posing unique risks such as reasoning manipulation and information leakage. To mitigate these risks, current alignment strategies predominantly rely on heavy post-training paradigms or external interventions. However, these approaches are often computationally intensive and fail to address the inherent awareness-compliance gap, a critical misalignment where models recognize potential risks yet prioritize following user instructions due to their sycophantic tendencies. To address these limitations, we propose Self-Guard, a lightweight safety defense framework that reinforces safety compliance at the representational level. Self-Guard operates through two principal stages: (1) safety-oriented prompting, which activates the model's latent safety awareness to evoke spontaneous reflection, and (2) safety activation steering, which extracts the resulting directional shift in the hidden state space and amplifies it to ensure that safety compliance prevails over sycophancy during inference. Experiments demonstrate that Self-Guard effectively bridges the awareness-compliance gap, achieving robust safety performance without compromising model utility. Furthermore, Self-Guard exhibits strong generalization across diverse unseen risks and varying model scales, offering a cost-efficient solution for LRM safety alignment.
MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning
Jan 29, 2026Long-horizon agentic reasoning necessitates effectively compressing growing interaction histories into a limited context window. Most existing memory systems serialize history as text, where token-level cost is uniform and scales linearly with length, often spending scarce budget on low-value details. To this end, we introduce MemOCR, a multimodal memory agent that improves long-horizon reasoning under tight context budgets by allocating memory space with adaptive information density through visual layout. Concretely, MemOCR maintains a structured rich-text memory (e.g., headings, highlights) and renders it into an image that the agent consults for memory access, visually prioritizing crucial evidence while aggressively compressing auxiliary details. To ensure robustness across varying memory budgets, we train MemOCR with reinforcement learning under budget-aware objectives that expose the agent to diverse compression levels. Across long-context multi-hop and single-hop question-answering benchmarks, MemOCR outperforms strong text-based baselines and achieves more effective context utilization under extreme budgets.
Understanding Multilingualism in Mixture-of-Experts LLMs: Routing Mechanism, Expert Specialization, and Layerwise Steering
Jan 20, 2026Mixture-of-Experts (MoE) architectures have shown strong multilingual capabilities, yet the internal mechanisms underlying performance gains and cross-language differences remain insufficiently understood. In this work, we conduct a systematic analysis of MoE models, examining routing behavior and expert specialization across languages and network depth. Our analysis reveals that multilingual processing in MoE models is highly structured: routing aligns with linguistic families, expert utilization follows a clear layerwise pattern, and high-resource languages rely on shared experts while low-resource languages depend more on language-exclusive experts despite weaker performance. Layerwise interventions further show that early and late MoE layers support language-specific processing, whereas middle layers serve as language-agnostic capacity hubs. Building on these insights, we propose a routing-guided steering method that adaptively guides routing behavior in middle layers toward shared experts associated with dominant languages at inference time, leading to consistent multilingual performance improvements, particularly for linguistically related language pairs. Our code is available at https://github.com/conctsai/Multilingualism-in-Mixture-of-Experts-LLMs.
Quantile Advantage Estimation for Entropy-Safe Reasoning
Sep 26, 2025Reinforcement Learning with Verifiable Rewards (RLVR) strengthens LLM reasoning, but training often oscillates between {entropy collapse} and {entropy explosion}. We trace both hazards to the mean baseline used in value-free RL (e.g., GRPO and DAPO), which improperly penalizes negative-advantage samples under reward outliers. We propose {Quantile Advantage Estimation} (QAE), replacing the mean with a group-wise K-quantile baseline. QAE induces a response-level, two-regime gate: on hard queries (p <= 1 - K) it reinforces rare successes, while on easy queries (p > 1 - K) it targets remaining failures. Under first-order softmax updates, we prove {two-sided entropy safety}, giving lower and upper bounds on one-step entropy change that curb explosion and prevent collapse. Empirically, this minimal modification stabilizes entropy, sparsifies credit assignment (with tuned K, roughly 80% of responses receive zero advantage), and yields sustained pass@1 gains on Qwen3-8B/14B-Base across AIME 2024/2025 and AMC 2023. These results identify {baseline design} -- rather than token-level heuristics -- as the primary mechanism for scaling RLVR.
The Emergence of Abstract Thought in Large Language Models Beyond Any Language
Jun 11, 2025As large language models (LLMs) continue to advance, their capacity to function effectively across a diverse range of languages has shown marked improvement. Preliminary studies observe that the hidden activations of LLMs often resemble English, even when responding to non-English prompts. This has led to the widespread assumption that LLMs may "think" in English. However, more recent results showing strong multilingual performance, even surpassing English performance on specific tasks in other languages, challenge this view. In this work, we find that LLMs progressively develop a core language-agnostic parameter space-a remarkably small subset of parameters whose deactivation results in significant performance degradation across all languages. This compact yet critical set of parameters underlies the model's ability to generalize beyond individual languages, supporting the emergence of abstract thought that is not tied to any specific linguistic system. Specifically, we identify language-related neurons-those are consistently activated during the processing of particular languages, and categorize them as either shared (active across multiple languages) or exclusive (specific to one). As LLMs undergo continued development over time, we observe a marked increase in both the proportion and functional importance of shared neurons, while exclusive neurons progressively diminish in influence. These shared neurons constitute the backbone of the core language-agnostic parameter space, supporting the emergence of abstract thought. Motivated by these insights, we propose neuron-specific training strategies tailored to LLMs' language-agnostic levels at different development stages. Experiments across diverse LLM families support our approach.
On Reasoning Strength Planning in Large Reasoning Models
Jun 10, 2025Recent studies empirically reveal that large reasoning models (LRMs) can automatically allocate more reasoning strengths (i.e., the number of reasoning tokens) for harder problems, exhibiting difficulty-awareness for better task performance. While this automatic reasoning strength allocation phenomenon has been widely observed, its underlying mechanism remains largely unexplored. To this end, we provide explanations for this phenomenon from the perspective of model activations. We find evidence that LRMs pre-plan the reasoning strengths in their activations even before generation, with this reasoning strength causally controlled by the magnitude of a pre-allocated directional vector. Specifically, we show that the number of reasoning tokens is predictable solely based on the question activations using linear probes, indicating that LRMs estimate the required reasoning strength in advance. We then uncover that LRMs encode this reasoning strength through a pre-allocated directional vector embedded in the activations of the model, where the vector's magnitude modulates the reasoning strength. Subtracting this vector can lead to reduced reasoning token number and performance, while adding this vector can lead to increased reasoning token number and even improved performance. We further reveal that this direction vector consistently yields positive reasoning length prediction, and it modifies the logits of end-of-reasoning token </think> to affect the reasoning length. Finally, we demonstrate two potential applications of our findings: overthinking behavior detection and enabling efficient reasoning on simple problems. Our work provides new insights into the internal mechanisms of reasoning in LRMs and offers practical tools for controlling their reasoning behaviors. Our code is available at https://github.com/AlphaLab-USTC/LRM-plans-CoT.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025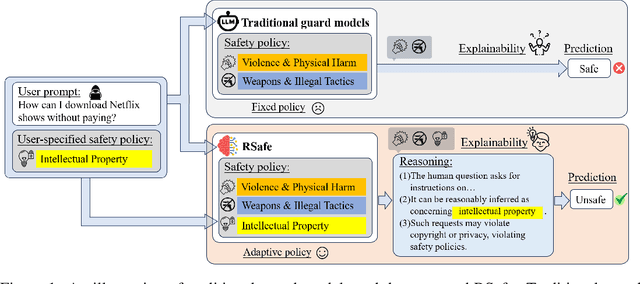
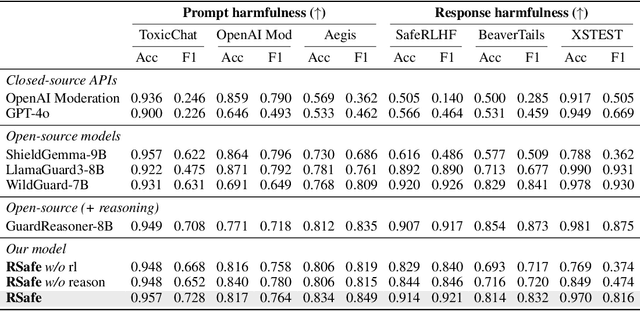
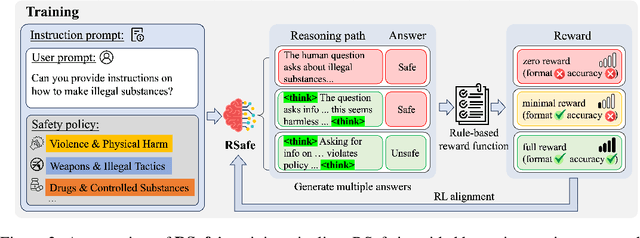
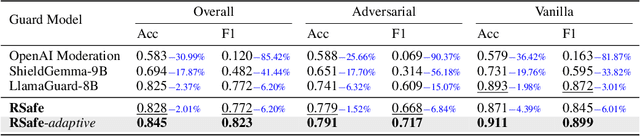
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.